
Link Prediction in Complex Networks Using Recursive Feature Elimination and Stacking Ensemble Learning

Abstract
:1. Introduction
2. Preliminaries
2.1. Problem Description
2.2. Similarity Indices
2.3. Dataset Description
3. Proposed Framework: RF-RFE-SELLP
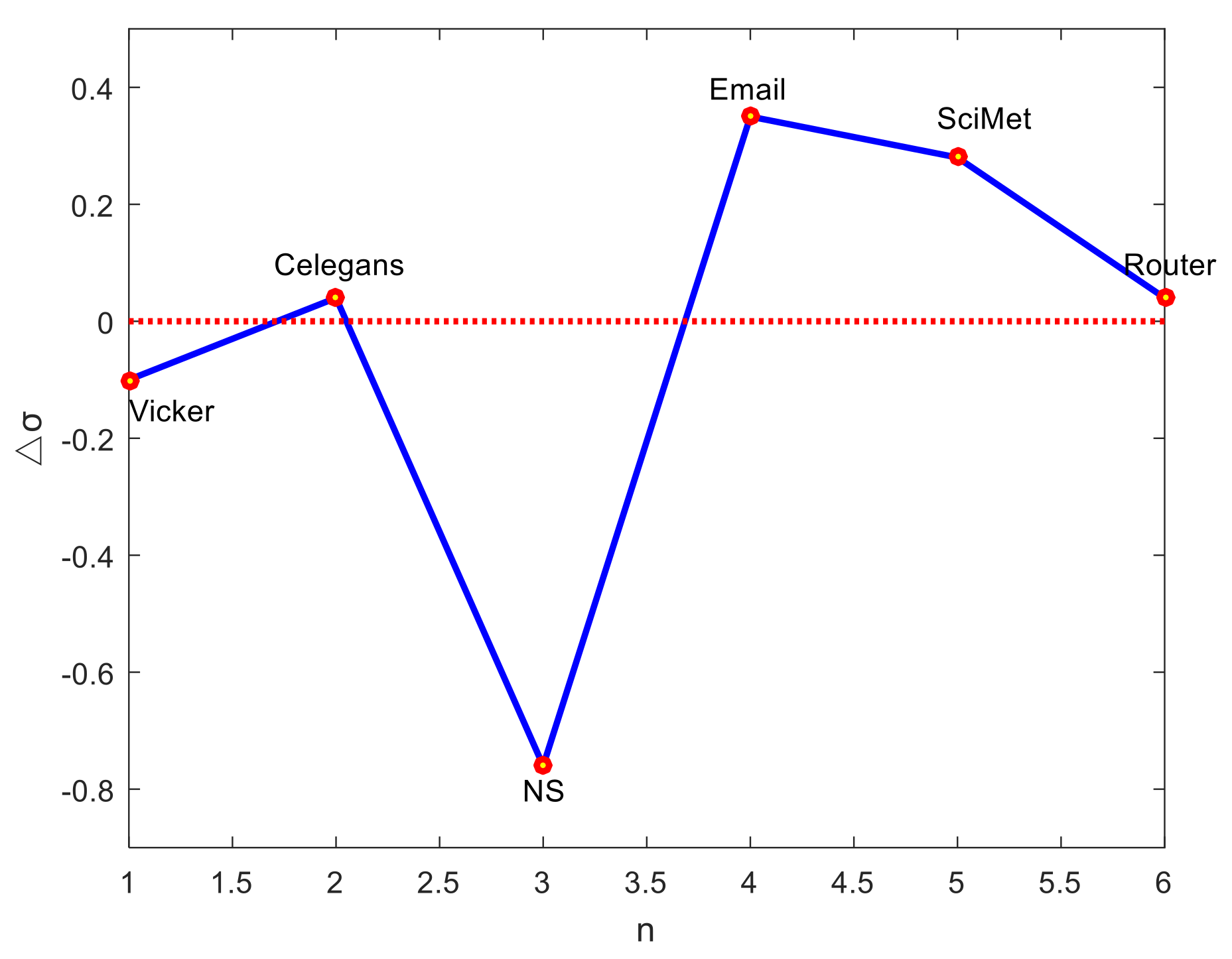
3.1. Motivation
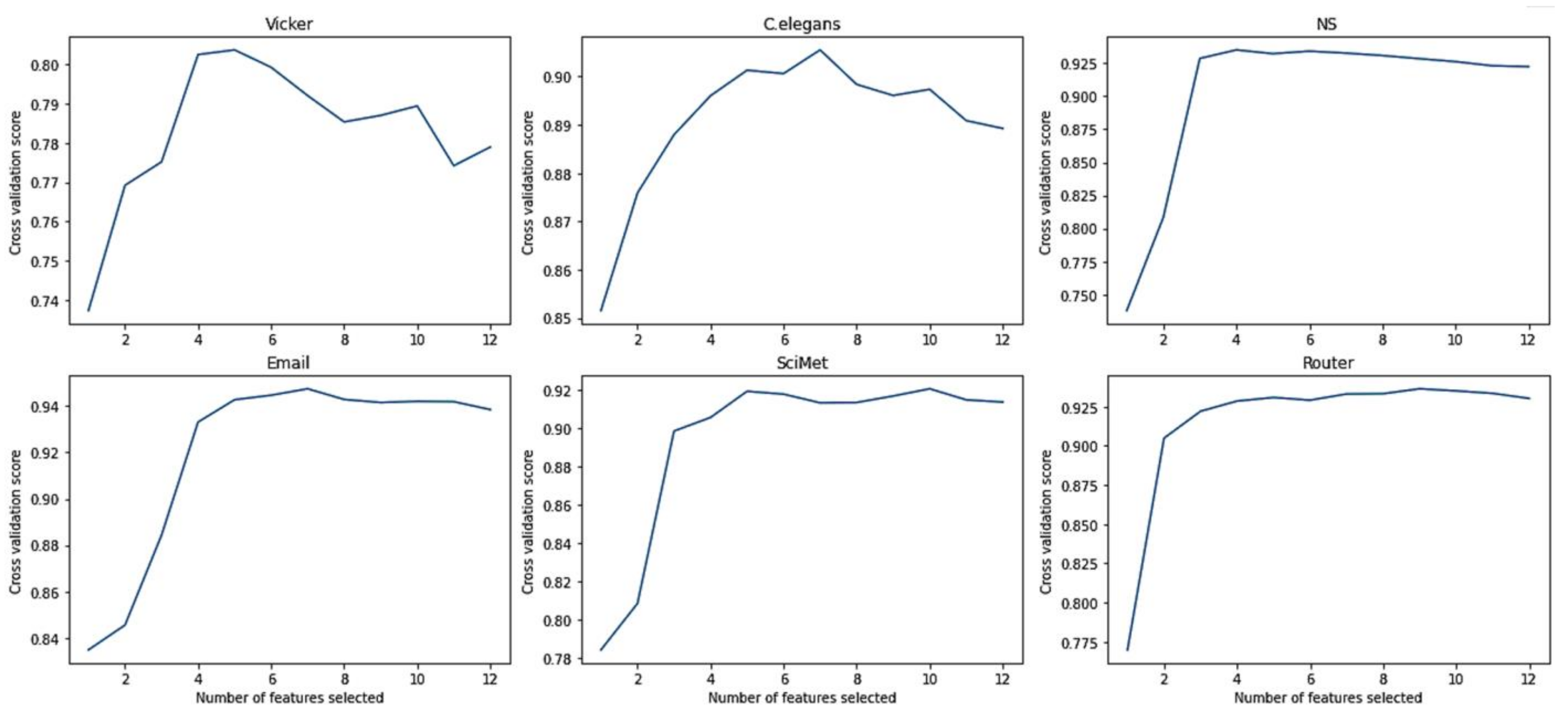
3.2. Random Forest-Based Recursive Feature Elimination for Feature Selection
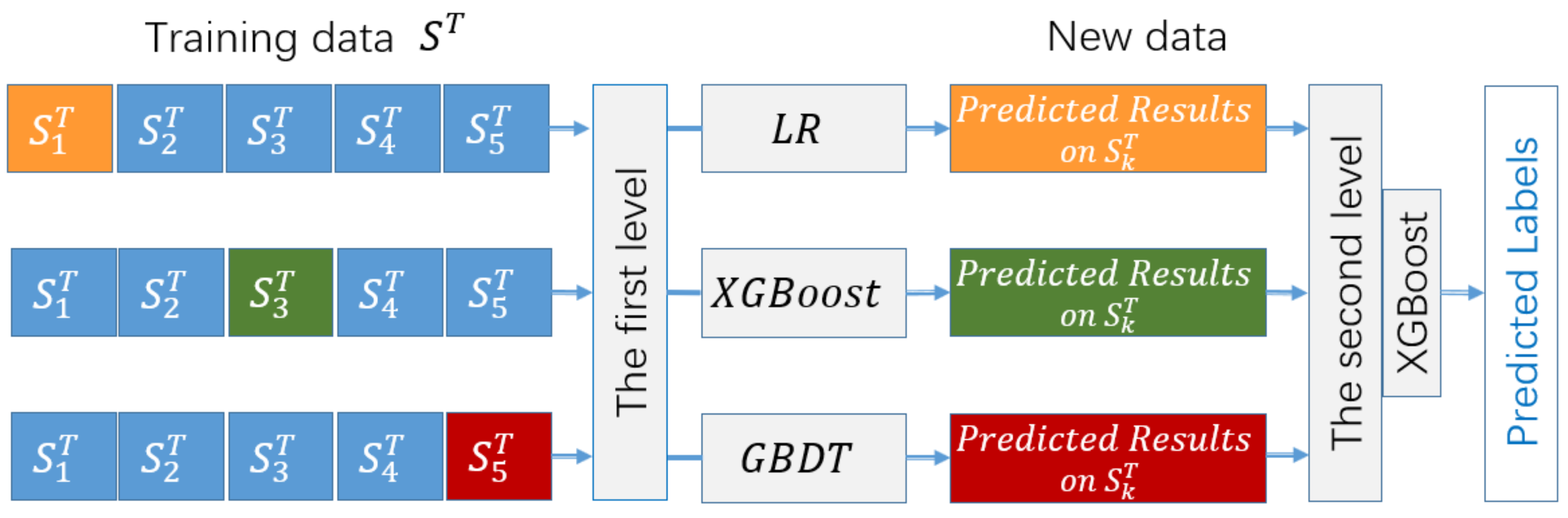
3.3. Stacking Ensemble Learning for Link Prediction
3.4. RF-RFE-SELLP Algorithm
| Algorithm 1: RF-RFE-SELLP algorithm |
| Input: Network Output: Parameters of SELLP model 1: Calculate the adjacency matrix of network G. 2: for each do 3: 4: 5:/* is the label, is the feature vector, and is the score computed by the similarity index .*/ 6: end for 7: for to 12 do 8: Compute the VIM of features, and remove the feature with the lowest one. 9: Update feature ranked list, and calculate the corresponding CVS. 10: end for 11: Obtain the optimal feature subset by comparing CVS. 12: Construct the set including the feature subset and label , and then divide into the training set and test set . 13: for to 5 do 14: for to 3 do 15: Train the base model on the training set . 16: Predict the probability on the test set . 17: end for 18: end for 19: Construct the set by the prediction results of each base model. 20: Train the fuse model of the second layer on the set . 21: Return the parameters of RF-RFE-SELLP model. |
4. Experiments
4.1. Experimental Setting
4.2. Evaluation Metric
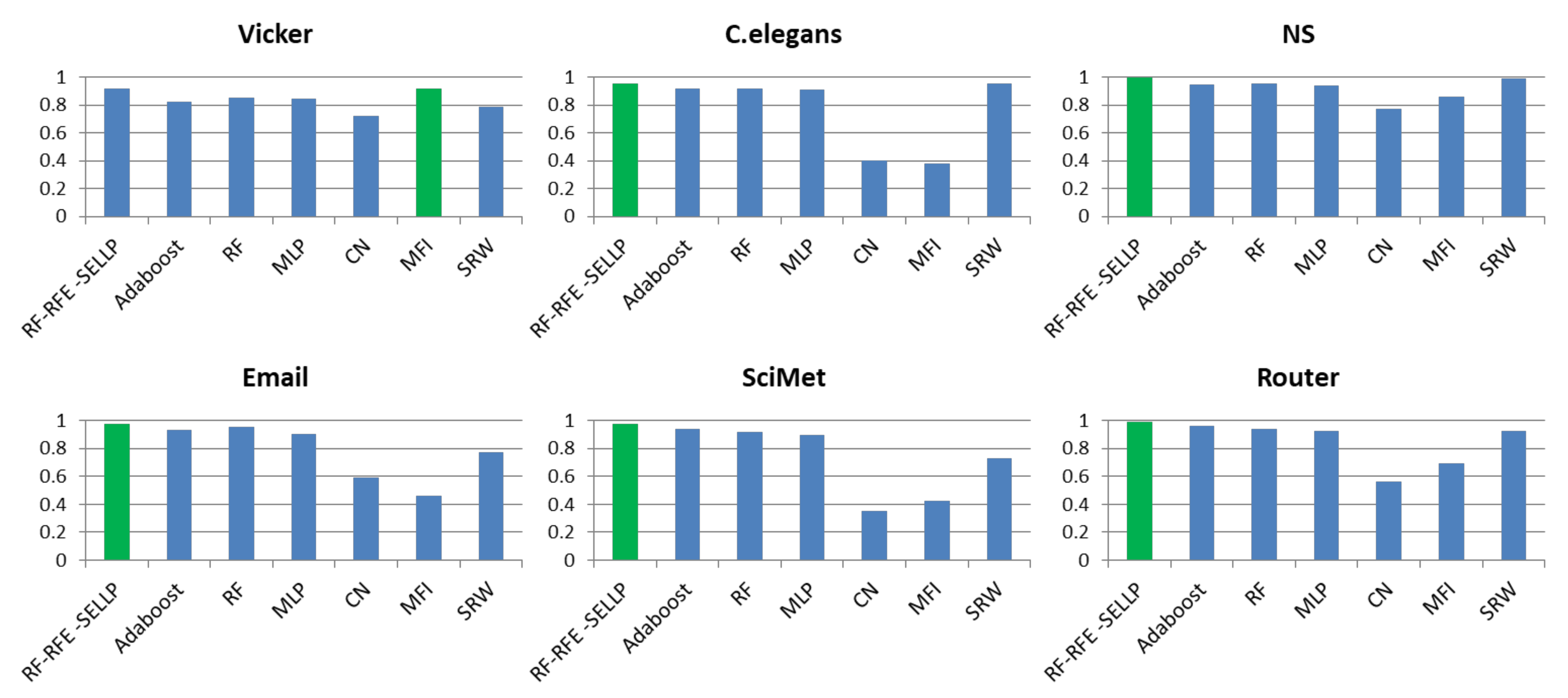
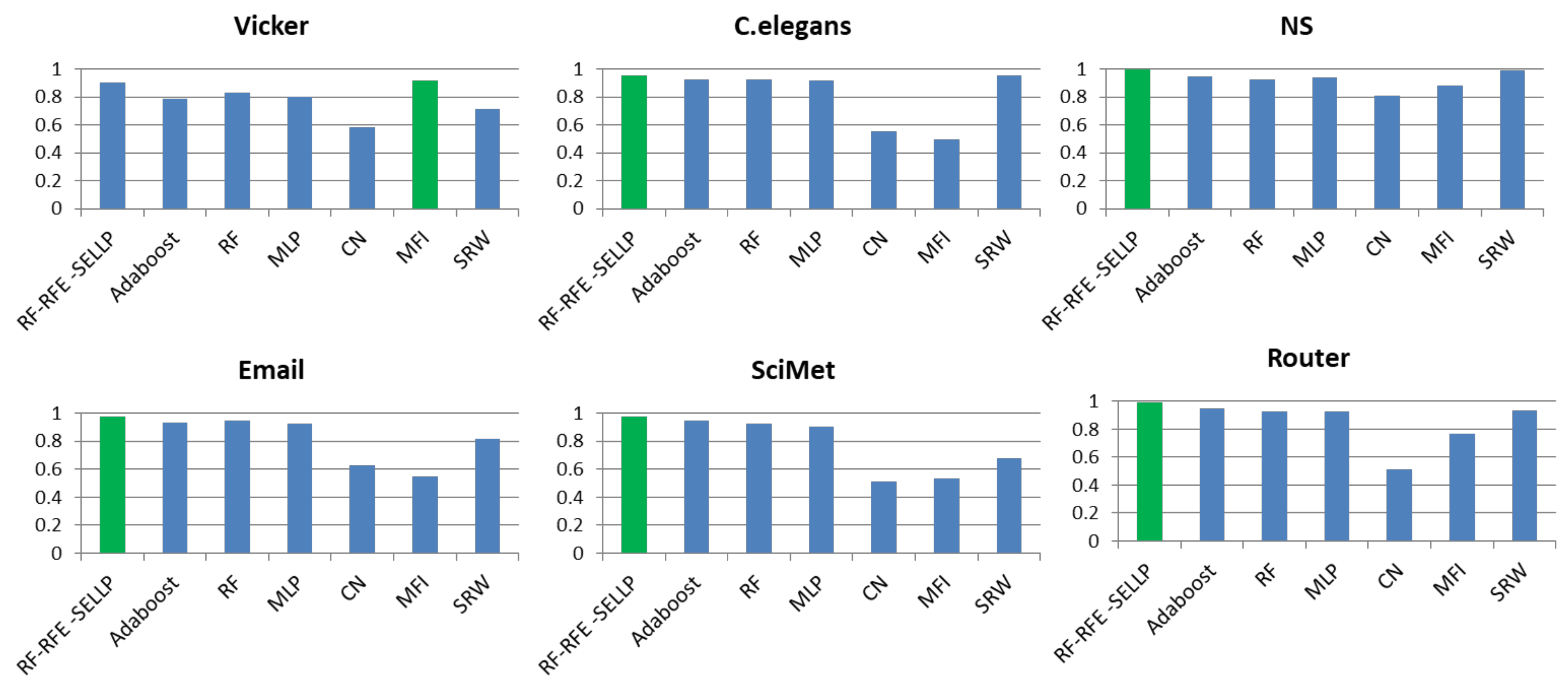
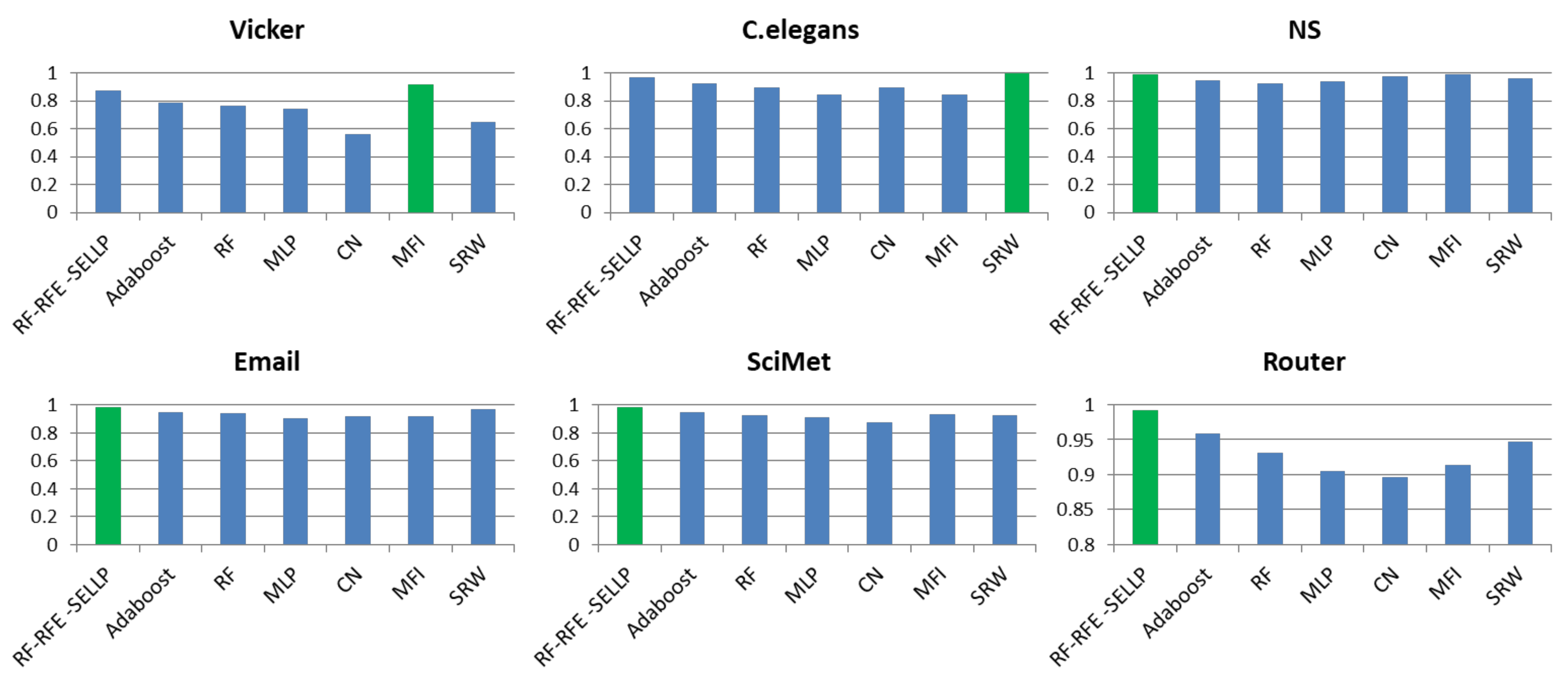
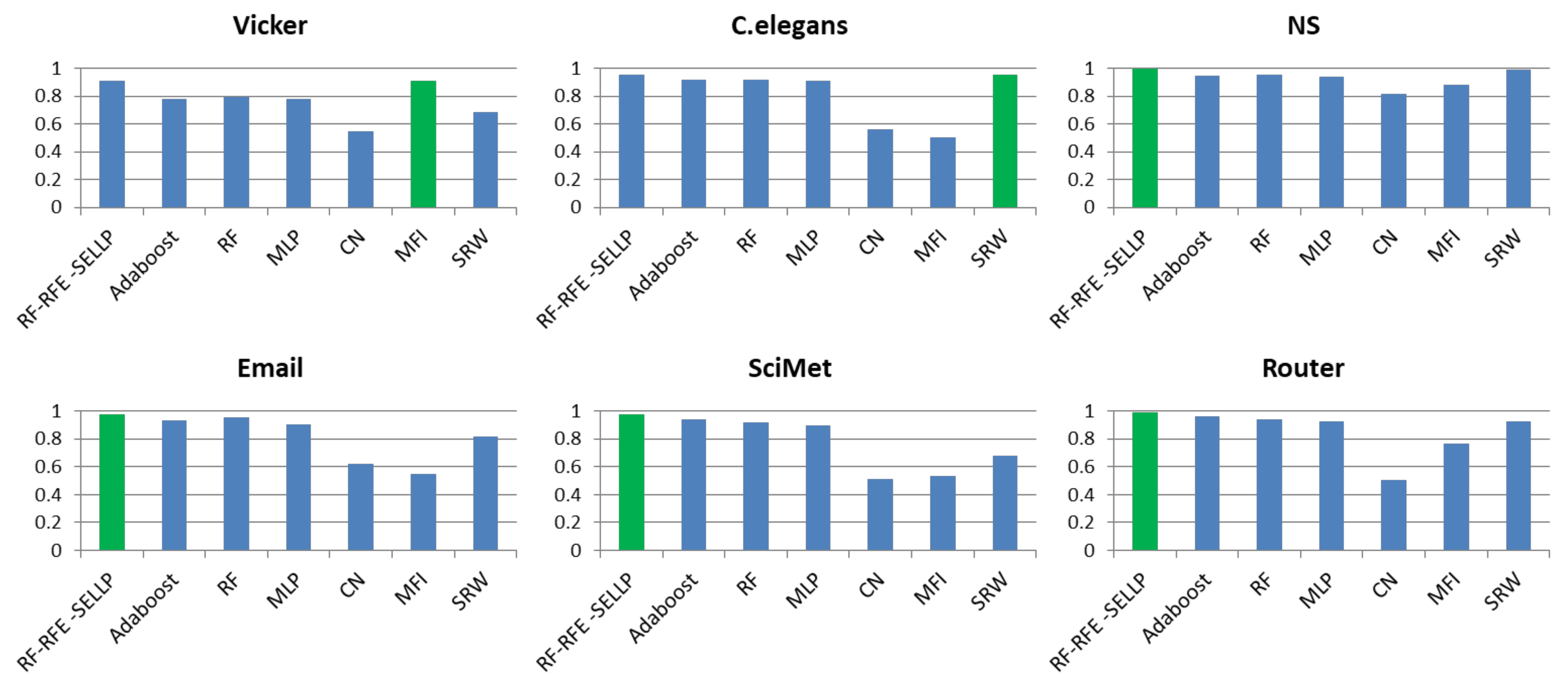
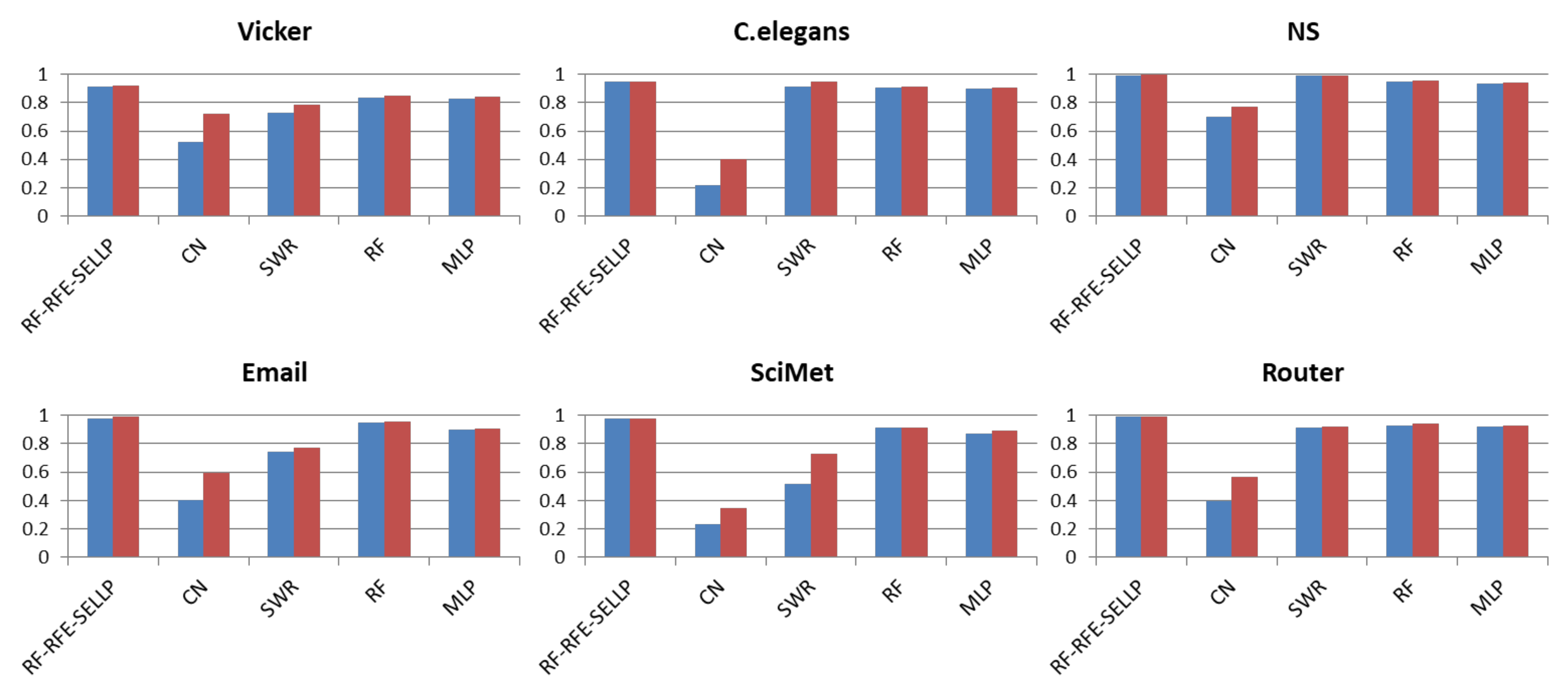
4.3. Performance Comparison
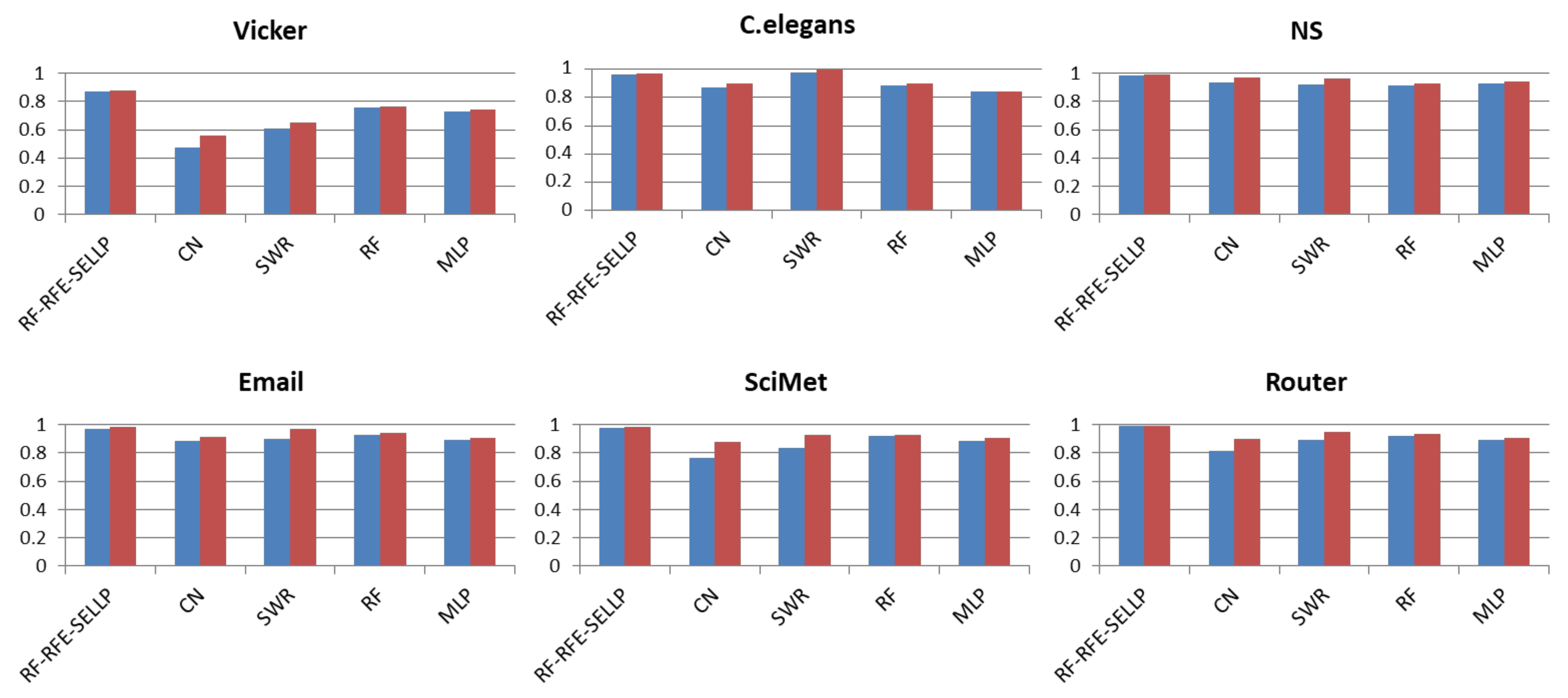
4.4. Robustness
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Boccaletti, S.; Latora, V.; Moreno, Y.; Chavez, M.; Hwang, D.U. Complex Networks: Structure and Dynamics. Phys. Rep. 2006, 424, 175–308. [Google Scholar] [CrossRef]
- Kumar, A.; Singh, S.S.; Singh, K.; Biswas, B. Link Prediction Techniques, Applications, and Performance: A Survey. Physica A 2020, 553, 124289. [Google Scholar] [CrossRef]
- Gou, F.; Wu, J. Triad link prediction method based on the evolutionary analysis with IoT in opportunistic social networks. Comput. Commun. 2022, 181, 143–155. [Google Scholar] [CrossRef]
- Zhou, T. Progresses and Challenges in Link Prediction. iScience 2021, 24, 103217. [Google Scholar] [CrossRef]
- Martínez, V.; Berzal, F.; Cubero, J.C. A Survey of Link Prediction in Complex Networks. ACM Comput. Surv. 2016, 49, 1–33. [Google Scholar] [CrossRef]
- Zhang, Q.; Tong, T.; Wu, S. Hybrid Link Prediction via Model Averaging. Physica A 2020, 556, 124772. [Google Scholar] [CrossRef]
- Mori, L.; O’Hara, K.; Pujol, T.A.; Ventresca, M. Examining Supervised Machine Learning Methods for Integer Link Weight Prediction Using Node Metadata. Entropy 2022, 24, 842. [Google Scholar] [CrossRef]
- Newman, M.E.J. Clustering and Preferential Attachment in Growing Networks. Phys. Rev. E 2001, 64, 025102. [Google Scholar] [CrossRef]
- Jaccard, P. Étude comparative de la distribution florale dans une portion des Alpes et des Jura. Bull. Soc. Vaudoise Sci. Nat. 1901, 37, 547–579. [Google Scholar]
- Barabási, A.L.; Albert, R. Emergence of Scaling in Random Networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef]
- Adamic, L.A.; Adar, E. Friends and Neighbors on the Web. Soc. Netw. 2003, 25, 211–230. [Google Scholar] [CrossRef]
- Zhou, T.; Lü, L.; Zhang, Y.C. Predicting Missing Links via Local Information. Eur. Phys. J. B 2009, 71, 623–630. [Google Scholar] [CrossRef]
- Salton, G.; McGill, M.J. Introduction to Modern Information Retrieval; McGraw-Hill: Auckland, New Zealand, 1983. [Google Scholar]
- Aziz, F.; Gul, H.; Muhammad, I.; Uddin, I. Link Prediction Using Node Information on Local Paths. Physica A 2020, 557, 124980. [Google Scholar] [CrossRef]
- Klein, D.J.; Randić, M. Resistance Distance. J. Math. Chem. 1993, 12, 81–95. [Google Scholar] [CrossRef]
- Brin, S.; Page, L. The Anatomy of a Large-scale Hypertextual Web Search Engine. Comput. Netw. ISDN Syst. 1998, 30, 107–117. [Google Scholar] [CrossRef]
- Jeh, G.; Widom, J. Simrank: A Measure of Structural-context Similarity. In Proceedings of the eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; pp. 538–543. [Google Scholar]
- Lü, L.; Jin, C.H.; Zhou, T. Similarity Index based on Local Paths for Link Prediction of Complex Networks. Phys. Rev. E 2009, 80, 046122. [Google Scholar] [CrossRef]
- Liu, W.; Lü, L. Link Prediction based on Local Random Walk. Euro. Lett. 2010, 89, 58007. [Google Scholar] [CrossRef]
- Wu, Z.; Liang, Q.; Liu, Q.; Qin, Z.G. Modified Link Prediction Algorithm based on AdaBoost. J. Commun. 2014, 35, 116. [Google Scholar]
- Li, K.; Tu, L.; Chai, L. Ensemble-model-based Link Prediction of Complex Networks. Comput. Netw. 2020, 166, 106978. [Google Scholar] [CrossRef]
- Ma, C.; Bao, Z.K.; Zhang, H.F. Improving Link Prediction in Complex Networks by Adaptively Exploiting Multiple Structural Features of Networks. Phys. Lett. A 2017, 381, 3369–3376. [Google Scholar] [CrossRef]
- He, Y.-L.; Liu, J.N.; Hu, Y.-X.; Wang, X.-Z. OWA Operator based Link Prediction Ensemble for Social Network. Expert Syst. Appl. 2015, 42, 21–50. [Google Scholar] [CrossRef]
- Yu, H.; Wang, S.; Ma, Q. Link Prediction Algorithm based on the Choquet Fuzzy Integral. J. Commun. 2016, 20, 809–824. [Google Scholar] [CrossRef]
- Li, X.; Wang, Z.; Zhang, Z. Complex Embedding with Type Constraints for Link Prediction. Entropy 2022, 24, 330. [Google Scholar] [CrossRef] [PubMed]
- Lv, H.; Zhang, B.; Hu, S.; Xu, Z. Deep Link-Prediction Based on the Local Structure of Bipartite Networks. Entropy 2022, 24, 610. [Google Scholar] [CrossRef]
- Zhu, Y.; Liu, S.; Li, Y.; Li, H. TLP-CCC: Temporal Link Prediction Based on Collective Community and Centrality Feature Fusion. Entropy 2022, 24, 296. [Google Scholar] [CrossRef]
- Leicht, E.A.; Holme, P.; Newman, M.E.J. Vertex Similarity in Networks. Phys. Rev. E 2006, 73, 026120. [Google Scholar] [CrossRef]
- Chebotarev, P.; Shamis, E. The Matrix-forest Theorem and Measuring Relations in Small Social Groups. arXiv 2006. [Google Scholar] [CrossRef]
- Watts, D.J.; Strogatz, S.H. Collective Dynamics of ‘Small-world’. Netw. Nat. 1998, 393, 440–442. [Google Scholar] [CrossRef]
- Vickers, M.; Chan, S. Representing Classroom Social Structure; Victoria Institute of Secondary Education: Melbourne, VIC, Australia, 1981. [Google Scholar]
- Guimerà, R.; Danon, L.; Díaz-Guilera, A.; Giralt, F.; Arenas, A. Self-similar community structure in a network of human interactions. Phys. Rev. E 2003, 68, 065103. [Google Scholar] [CrossRef]
- Von Mering, C.; Krause, R.; Snel, B.; Cornell, M.; Oliver, S.G.; Fields, S.; Bork, P. Comparative assessment of large-scale data sets of protein–protein interactions. Nature 2002, 417, 399–403. [Google Scholar] [CrossRef]
- Pajek Datasets. Available online: http://vlado.fmf.uni-lj.si/pub/networks/data/ (accessed on 6 May 2016).
- Spring, N.; Mahajan, R.; Wetherall, D.; Anderson, T. Measuring ISP Topologies with Rocketfuel. IEEE/ACM Trans. Netw. 2004, 12, 2–16. [Google Scholar] [CrossRef]
- Li, L.; Bai, S.; Leng, M.; Wang, L.; Chen, X. Finding Missing Links in Complex Networks: A multiple-attribute Decision-making Method. Complexity 2018, 2018, 3579758. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L.; Wang, B.; Li, F.; Zhang, Z. Feature clustering based support vector machine recursive feature elimination for gene selection. Appl. Intell. 2018, 48, 594–607. [Google Scholar] [CrossRef]
- Shan, N.; Li, L.; Zhang, Y.; Bai, S.; Chen, X. Supervised link prediction in multiplex networks. Knowl. Based Syst. 2020, 203, 106168. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Networks | N | M | C | R | H |
|---|---|---|---|---|---|
| C. elegans | 297 | 2148 | 0.308 | −0.163 | 1.800 |
| Vicker | 29 | 376 | 0.733 | −0.157 | 0.982 |
| 1133 | 5451 | 0.254 | 0.078 | 1.942 | |
| NS | 1589 | 2742 | 0.791 | 0.462 | 2.011 |
| SciMet | 3084 | 10,399 | 0.175 | −0.033 | 2.78 |
| Router | 5022 | 6258 | 0.033 | −0.138 | 5.503 |
| Results Based on the Original Features | ||||||
|---|---|---|---|---|---|---|
| Methods | Vicker | C. elegans | NS | SciMet | Router | |
| SELLP | 0.8290 | 0.9236 | 0.9538 | 0.9424 | 0.9378 | 0.9604 |
| GBDT | 0.7750 | 0.9079 | 0.9461 | 0.9308 | 0.9138 | 0.9477 |
| XGBoost | 0.7604 | 0.9085 | 0.9457 | 0.9460 | 0.9268 | 0.9531 |
| LR | 0.7318 | 0.8631 | 0.9365 | 0.9263 | 0.8967 | 0.9287 |
| Results based on the selected features using RF-RFE | ||||||
| Methods | Vicker | C. elegans | NS | SciMet | Router | |
| RF-RFE -SELLP | 0.9118 | 0.9525 | 0.9949 | 0.9747 | 0.9764 | 0.9884 |
| RF-RFE-GBDT | 0.8663 | 0.9419 | 0.9747 | 0.9476 | 0.9438 | 0.9680 |
| RF-RFE-XGBoost | 0.8059 | 0.9278 | 0.9786 | 0.9521 | 0.9563 | 0.9769 |
| RF-RFE-LR | 0.8263 | 0.9121 | 0.9627 | 0.9497 | 0.9432 | 0.9581 |
| Results Based on the Original Features | ||||||
|---|---|---|---|---|---|---|
| Methods | Vicker | C. elegans | NS | SciMet | Router | |
| SELLP | 0.8260 | 0.9246 | 0.9536 | 0.9524 | 0.9447 | 0.9600 |
| GBDT | 0.7681 | 0.9093 | 0.9245 | 0.9434 | 0.9237 | 0.9276 |
| XGBoost | 0.7826 | 0.9030 | 0.9453 | 0.9461 | 0.9279 | 0.9492 |
| LR | 0.7681 | 0.8813 | 0.9353 | 0.9361 | 0.9019 | 0.9248 |
| Results based on the selected features using RF-RFE | ||||||
| Methods | Vicker | C. elegans | NS | SciMet | Router | |
| RF-RFE-SELLP | 0.8985 | 0.9534 | 0.9945 | 0.9747 | 0.9764 | 0.9884 |
| RF-RFE-GBDT | 0.8405 | 0.9369 | 0.9745 | 0.9611 | 0.9537 | 0.9780 |
| RF-RFE-XGBoost | 0.8405 | 0.9355 | 0.9854 | 0.9606 | 0.9572 | 0.9768 |
| RF-RFE-LR | 0.8115 | 0.9081 | 0.9726 | 0.9592 | 0.9328 | 0.9492 |
| Results Based on the Original Features | ||||||
|---|---|---|---|---|---|---|
| Methods | Vicker | C. elegans | NS | SciMet | Router | |
| SELLP | 0.8246 | 0.9294 | 0.9545 | 0.9488 | 0.9481 | 0.9652 |
| GBDT | 0.7868 | 0.8919 | 0.9309 | 0.9375 | 0.9100 | 0.9474 |
| XGBoost | 0.7822 | 0.9097 | 0.9455 | 0.9419 | 0.9310 | 0.9523 |
| LR | 0.7791 | 0.8696 | 0.9370 | 0.9221 | 0.9098 | 0.9259 |
| Results based on the selected features using RF-RFE | ||||||
| Methods | Vicker | C. elegans | NS | SciMet | Router | |
| RF-RFE-SELLP | 0.8743 | 0.9670 | 0.9927 | 0.9794 | 0.9853 | 0.9913 |
| RF-RFE-GBDT | 0.8614 | 0.9320 | 0.9727 | 0.9548 | 0.9510 | 0.9789 |
| RF-RFE-XGBoost | 0.8367 | 0.9469 | 0.9845 | 0.9592 | 0.9524 | 0.9744 |
| RF-RFE-LR | 0.8189 | 0.8934 | 0.9781 | 0.9481 | 0.9428 | 0.9576 |
| Results based on the original features | ||||||
|---|---|---|---|---|---|---|
| Methods | Vicker | C. elegans | NS | SciMet | Router | |
| SELLP | 0.8571 | 0.9213 | 0.9536 | 0.9421 | 0.9374 | 0.9601 |
| GBDT | 0.8048 | 0.9059 | 0.9457 | 0.9304 | 0.9136 | 0.9478 |
| XGBoost | 0.8314 | 0.9066 | 0.9455 | 0.9457 | 0.9265 | 0.9533 |
| LR | 0.8260 | 0.8552 | 0.9363 | 0.9257 | 0.8960 | 0.9290 |
| Results based on the selected features using RF-RFE | ||||||
| Methods | Vicker | C. elegans | NS | SciMet | Router | |
| RF-RFE-SELLP | 0.9156 | 0.9501 | 0.9945 | 0.9744 | 0.9762 | 0.9885 |
| RF-RFE-GBDT | 0.8607 | 0.9380 | 0.9745 | 0.9473 | 0.9436 | 0.9682 |
| RF-RFE-XGBoost | 0.8817 | 0.9261 | 0.9785 | 0.9512 | 0.9559 | 0.9769 |
| RF-RFE-LR | 0.8395 | 0.9109 | 0.9624 | 0.9486 | 0.9429 | 0.9584 |
| AdaBoost | RF | MLP | CN | MFI | SRW | |
|---|---|---|---|---|---|---|
| p-value (F-test) | 0.48 | 0.45 | 0.11 | 0.02 | 0.14 | 0.19 |
| p-value (t-test) | 4.95 × 10−5 | 3.41 × 10−3 | 1.25 × 10−4 | 3.14 × 10−7 | 4.56 × 10−9 | 6.09 × 10−9 |
| Mean Accuracy | 0.9341 | 0.9461 | 0.9249 | 0.6227 | 0.5441 | 0.8161 |
| Mean Accuracy of RF-RFE-SELLP | 0.9748 | 0.9748 | 0.9748 | 0.9748 | 0.9748 | 0.9748 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, T.; Jiao, M.; Wang, X. Link Prediction in Complex Networks Using Recursive Feature Elimination and Stacking Ensemble Learning. Entropy 2022, 24, 1124. https://doi.org/10.3390/e24081124
Wang T, Jiao M, Wang X. Link Prediction in Complex Networks Using Recursive Feature Elimination and Stacking Ensemble Learning. Entropy. 2022; 24(8):1124. https://doi.org/10.3390/e24081124
Chicago/Turabian StyleWang, Tao, Mengyu Jiao, and Xiaoxia Wang. 2022. "Link Prediction in Complex Networks Using Recursive Feature Elimination and Stacking Ensemble Learning" Entropy 24, no. 8: 1124. https://doi.org/10.3390/e24081124