
Feature Importance in Gradient Boosting Trees with Cross-Validation Feature Selection


Abstract
:1. Introduction
2. Background
2.1. Decision Trees
2.2. Gradient Boosting Trees
2.3. GBM Implementations
2.4. FI Methods
2.4.1. Global FI Methods
- Split count—the number of times a feature is selected for a split in a tree.
- Cover—the number of observations in the training set that a node had split. Specifically, for every feature j, Cover is the total number of observations in splits that involve this feature.
2.4.2. Local FI Methods
2.5. Bias in Tree-Based Algorithms
3. Formulation of CVB
3.1. The Rationale behind CVB
3.2. CVB Stopping Criteria
4. Methods
5. Bias in Gradient Boosting FI
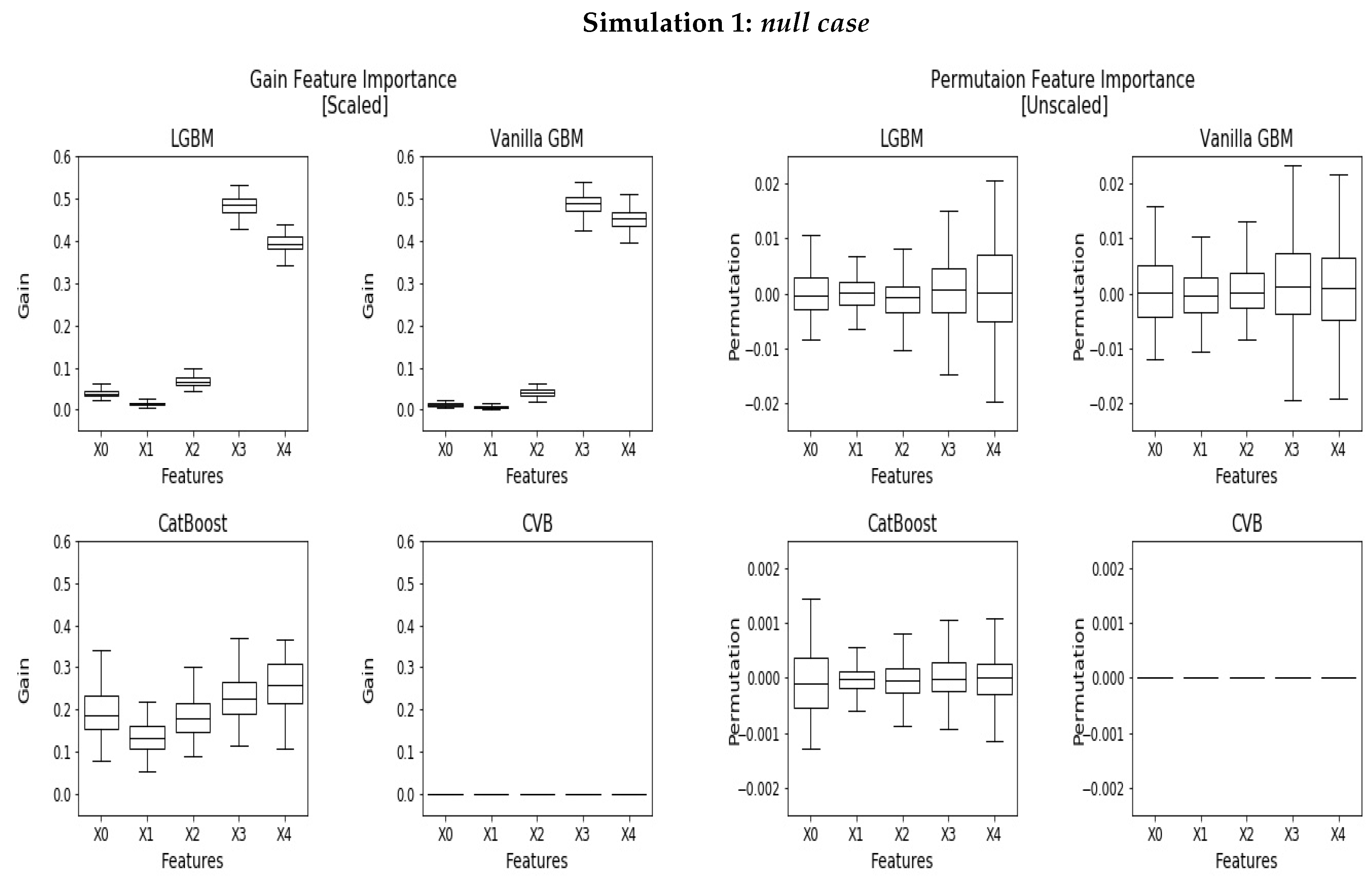
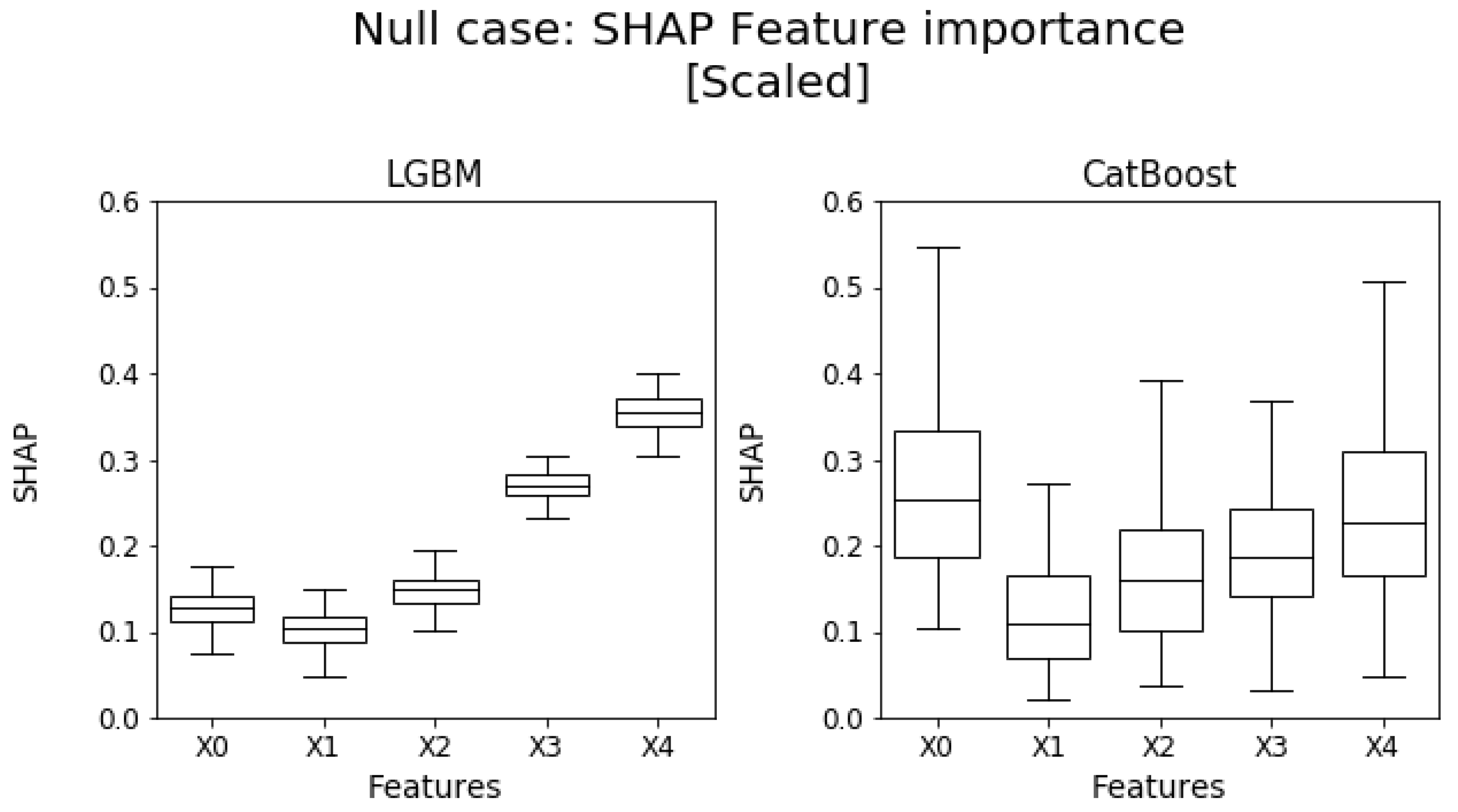
5.1. Null Case
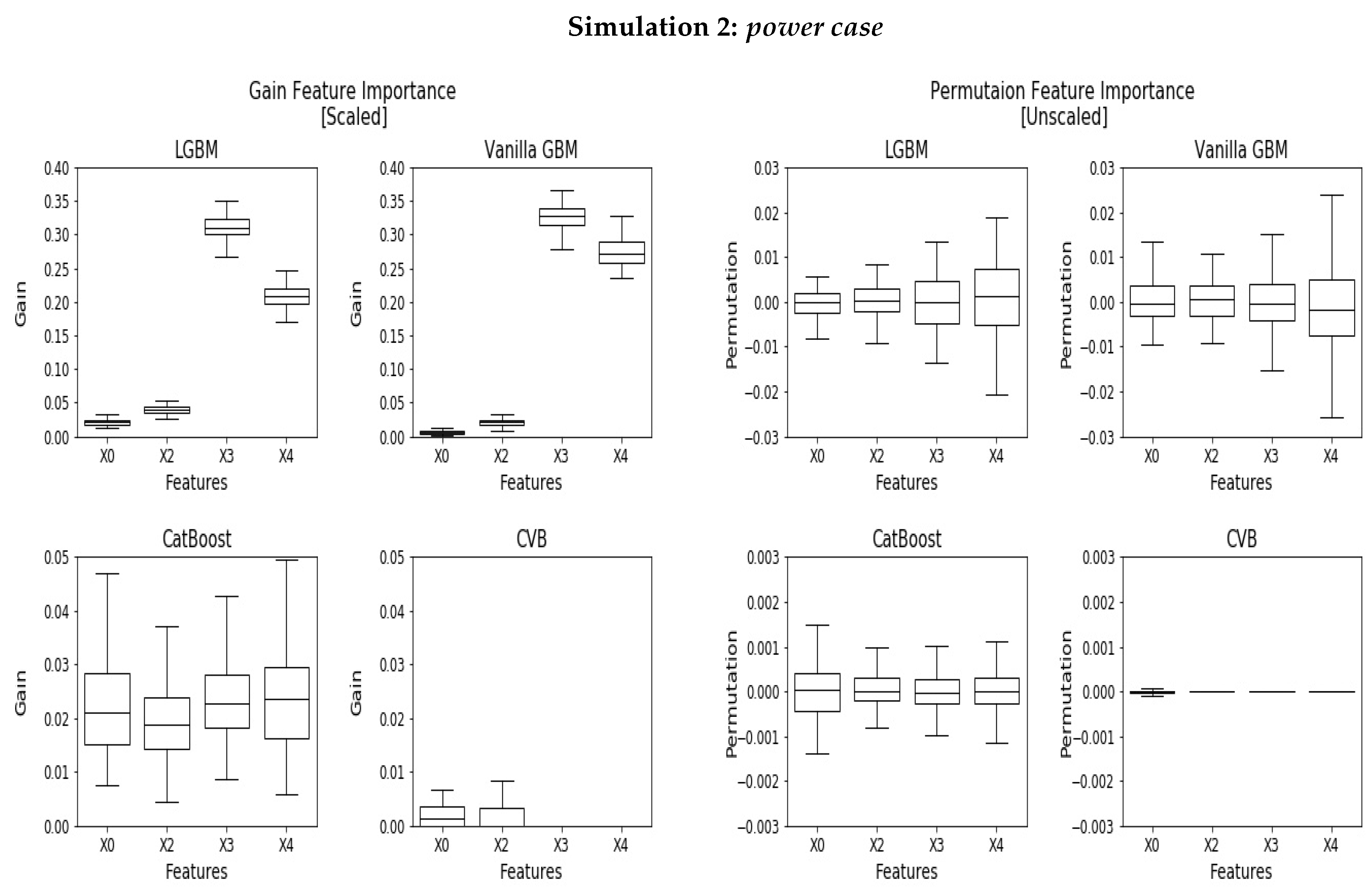
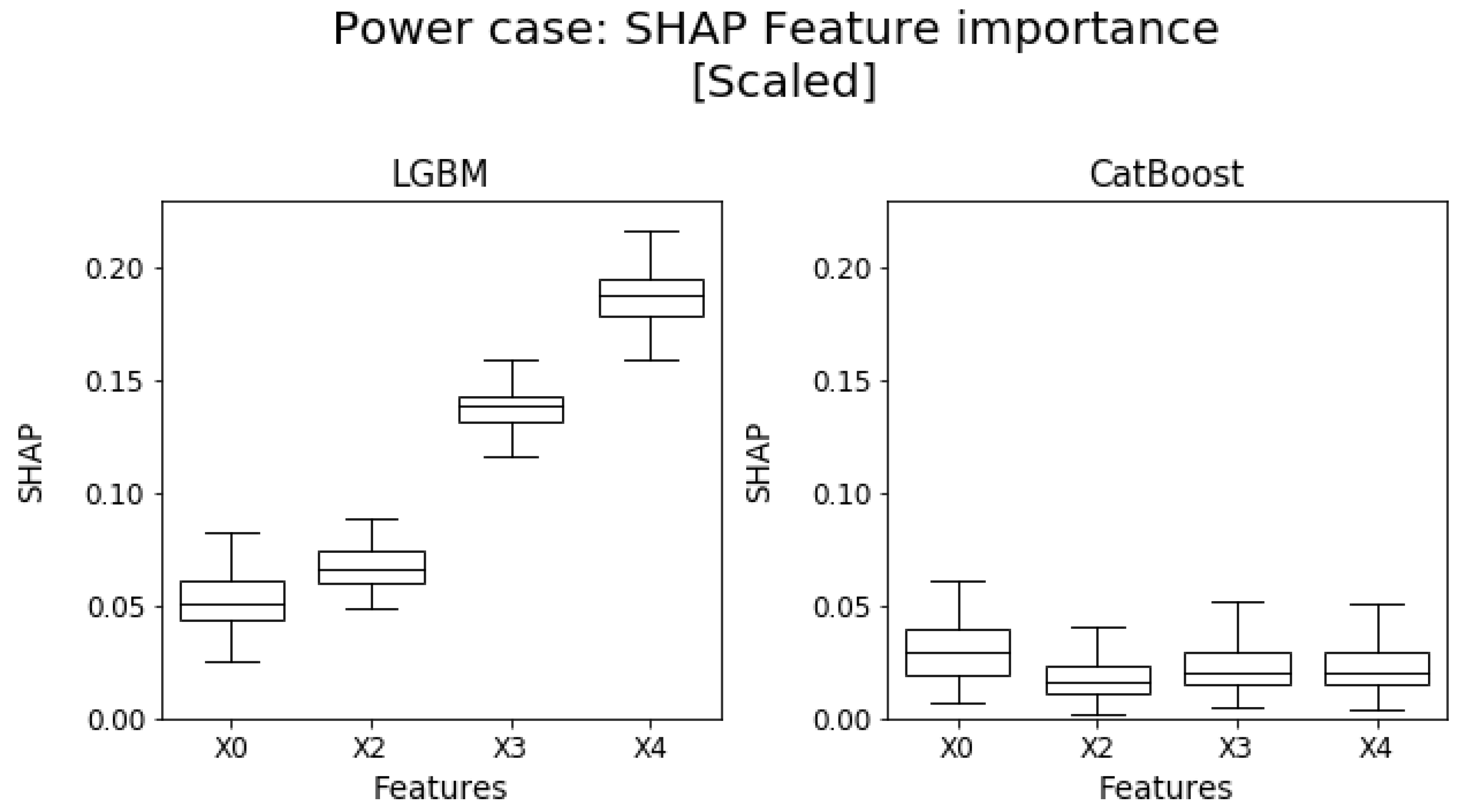
5.2. Power Case
6. Real Data Case Studies
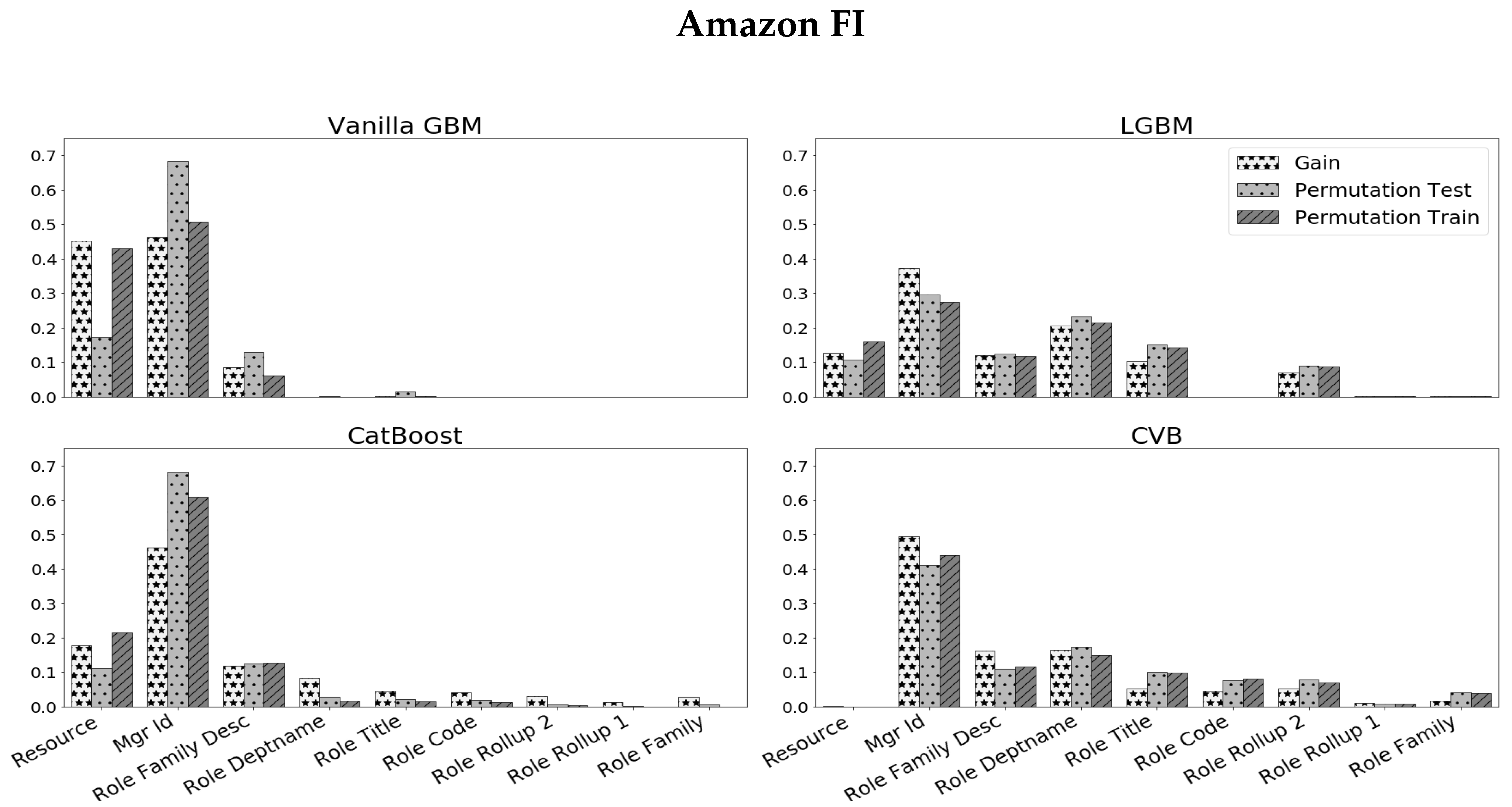
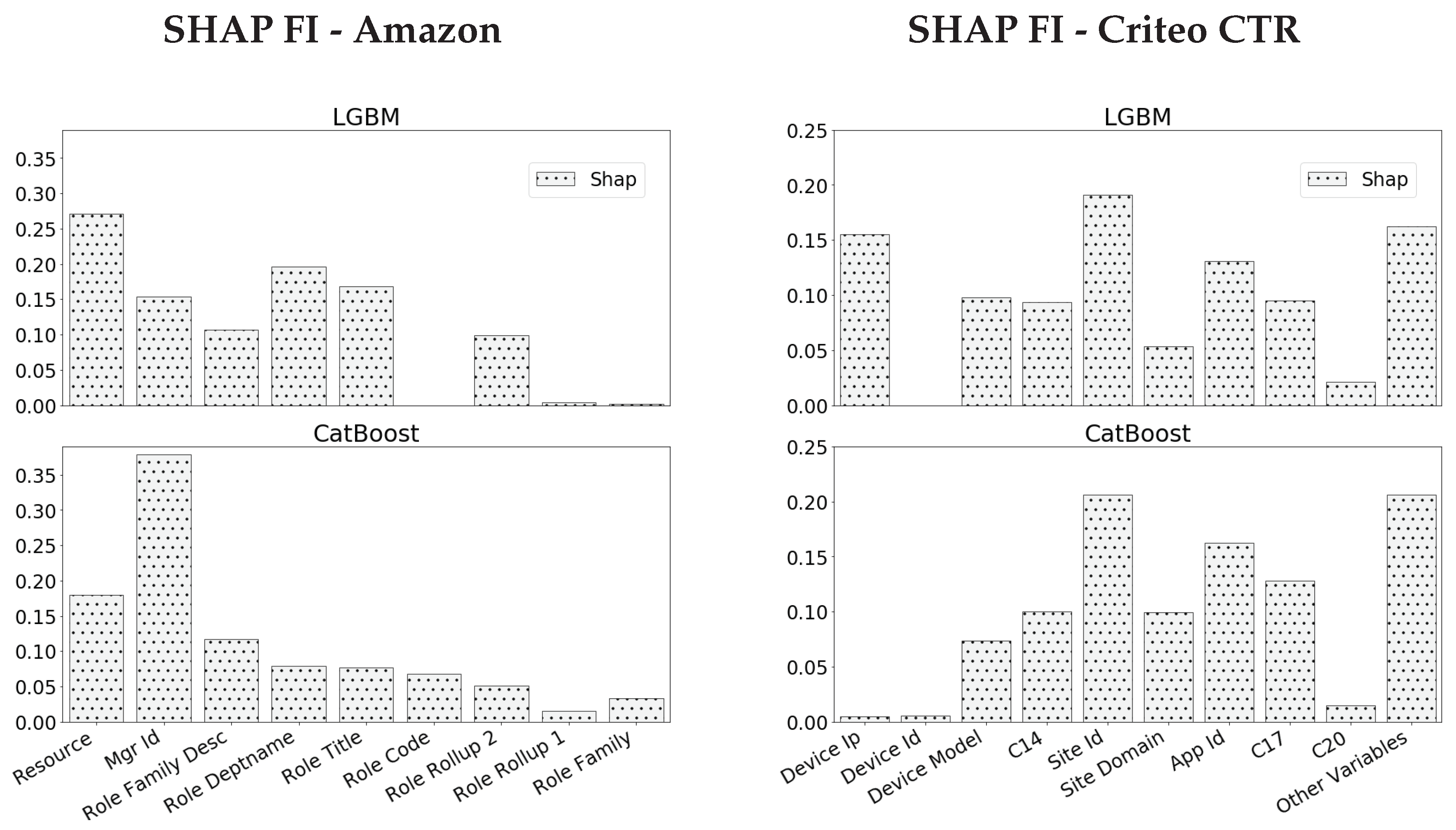
6.1. Amazon Dataset
- As in the simulation experiments, Vanilla GBM mostly utilizes high cardinality features and attains large values of FI for higher cardinality features (which appear on the left side of the plots).
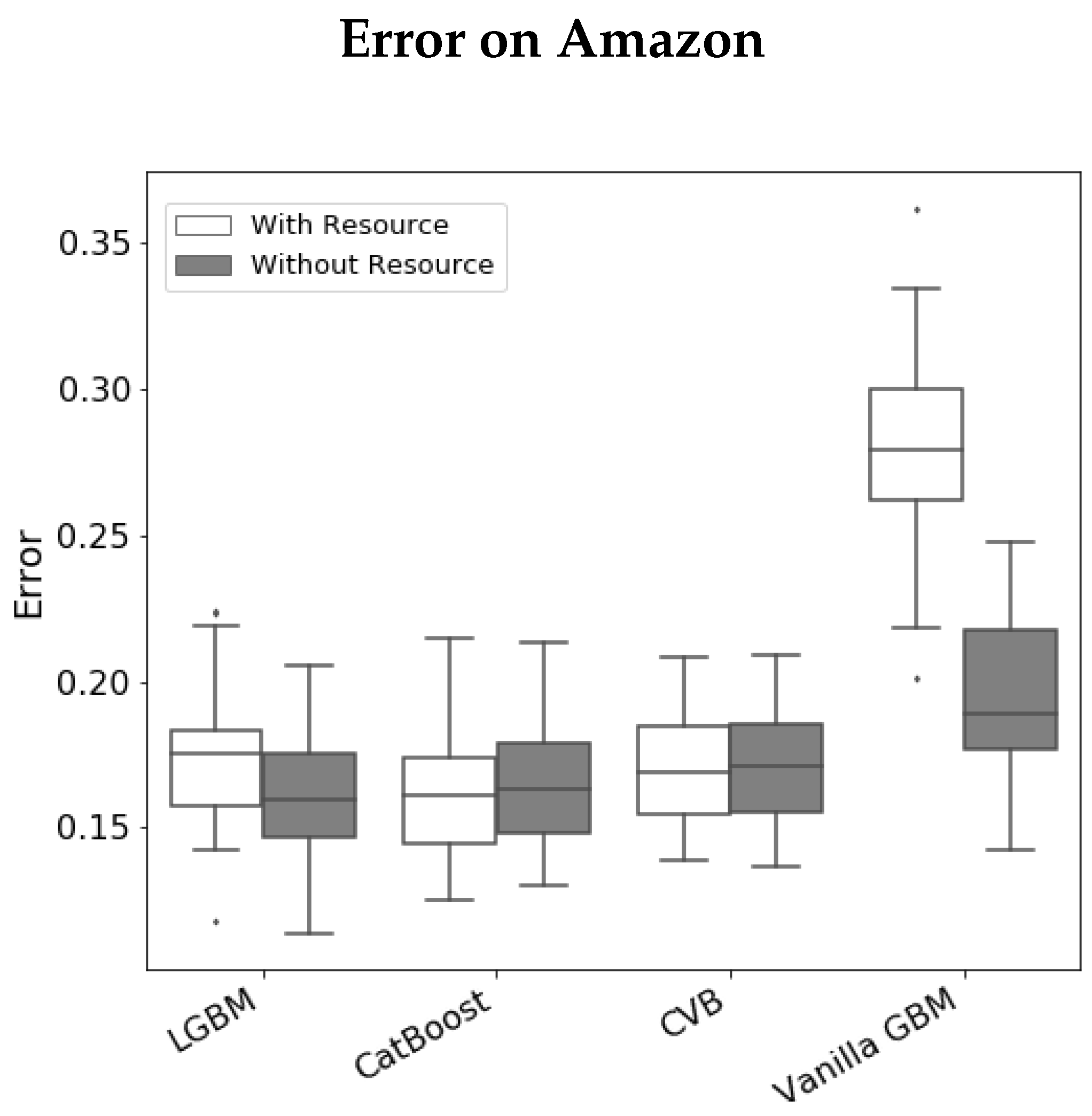
- The Resource variable attains a significantly large FI value in all methods besides CVB (in a significance level of 1%).
- As we further study the Resource variable, we observe that Vanilla GBM, LGBM and CatBoost demonstrate a significant gap between the PFI on the train-set and the PFI on the test-set. Since both are in the same units, a gap in favor of the former suggests that this feature is quite dominant in the train-set, but has less effect on the test-set. This may suggest an over-fitted model.

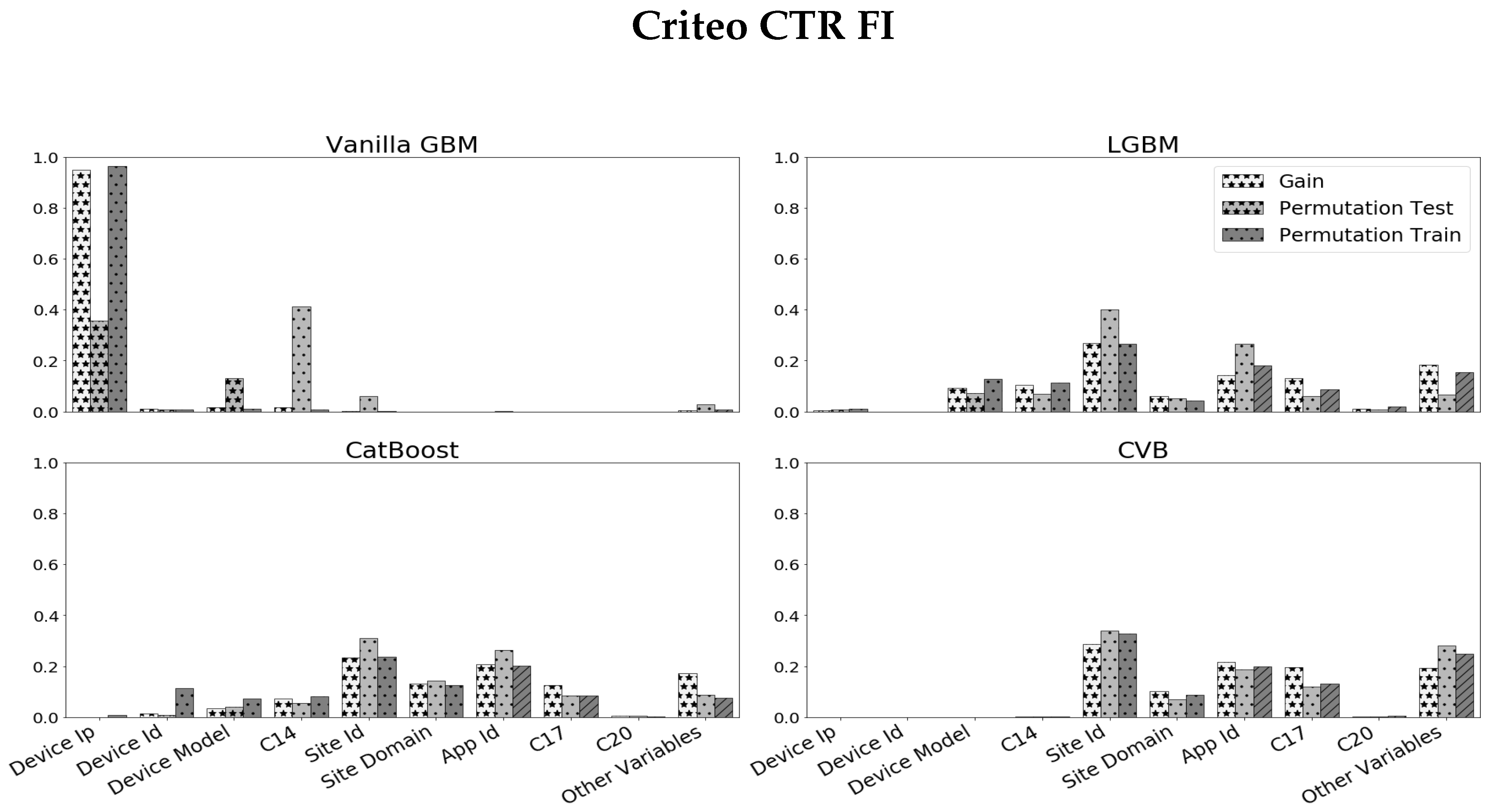
6.2. Criteo CTR Dataset
- As in the previous experiment, Vanilla GBM is biased towards high categorical variables and over-fits the train-set with Gain and PFI on train data close to one for the Device_ip feature.
- The results for LGBM and CatBoost are quite similar and score high cardinality features with larger scores compared to CVB results. They also over-estimate high cardinality features with a relatively small difference between the PFI on train data and PFI on test data for high cardinality features.
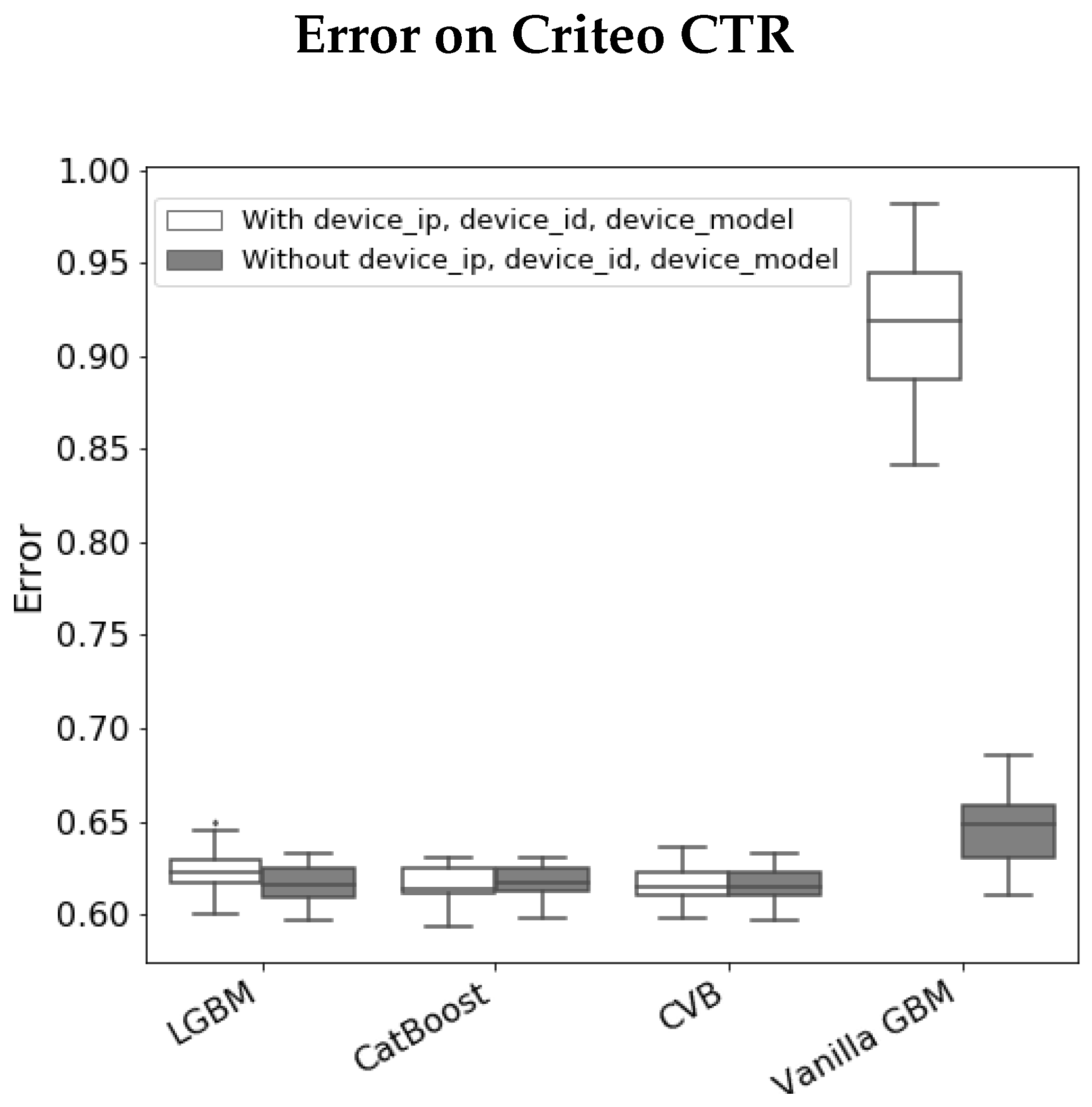
- In LGBM, Device_ip attains a large SHAP value in contrast to other FI measures, while in CatBoost SHAP FI is more consistent with other metrics, especially Gain and PFI on test data. As in the previous experiment, we examine whether CVB FI results are reliable by comparing the model errors with and without a feature set. Figure 6 demonstrates the results we achieve by comparing the set of all features to the set of features CVB scores with a positive FI. The results are quite similar to the Amazon data-set experiment.

6.3. Prediction Accuracy
7. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A



References
- Lundberg, S.M.; Nair, B.; Vavilala, M.S.; Horibe, M.; Eisses, M.J.; Adams, T.; Liston, D.E.; Low, D.K.W.; Newman, S.F.; Kim, J.; et al. Explainable machine-learning predictions for the prevention of hypoxaemia during surgery. Nat. Biomed. Eng. 2018, 2, 749–760. [Google Scholar] [CrossRef] [PubMed]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Richardson, M.; Dominowska, E.; Ragno, R. Predicting clicks: Estimating the click-through rate for new ads. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 521–530. [Google Scholar]
- Burges, C.J. From ranknet to lambdarank to lambdamart: An overview. Learning 2010, 11, 81. [Google Scholar]
- Strobl, C.; Boulesteix, A.L.; Zeileis, A.; Hothorn, T. Bias in random forest variable importance measures: Illustrations, sources and a solution. BMC Bioinform. 2007, 8, 25. [Google Scholar] [CrossRef] [Green Version]
- Painsky, A.; Rosset, S. Cross-validated variable selection in tree-based methods improves predictive performance. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2142–2153. [Google Scholar] [CrossRef] [Green Version]
- Loh, W.Y. Fifty years of classification and regression trees. Int. Stat. Rev. 2014, 82, 329–348. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Tyree, S.; Weinberger, K.Q.; Agrawal, K.; Paykin, J. Parallel boosted regression trees for web search ranking. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 387–396. [Google Scholar]
- Condie, T.; Conway, N.; Alvaro, P.; Hellerstein, J.M.; Elmeleegy, K.; Sears, R. MapReduce online. In Proceedings of the 7th USENIX Symposium on Networked Systems Design and Implementation (NSDI 2010), San Jose, CA, USA, 28–30 April 2010; Volume 10, p. 20. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. In Proceedings of the Advances in Neural Information Processing Systems 31 (NIPS 2018), Montreal, QC, Canada, 3–8 December 2018; pp. 6638–6648. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 3146–3154. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards a rigorous science of interpretable machine learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Molnar, C. Interpretable Machine Learning; Lulu Press: North Carolina, NC, USA, 2020. [Google Scholar]
- Pan, F.; Converse, T.; Ahn, D.; Salvetti, F.; Donato, G. Feature selection for ranking using boosted trees. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, Hong Kong, China, 2–6 November 2009; pp. 2025–2028. [Google Scholar]
- Kursa, M.B.; Rudnicki, W.R. Feature selection with the Boruta package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Gregorutti, B.; Michel, B.; Saint-Pierre, P. Correlation and variable importance in random forests. Stat. Comput. 2017, 27, 659–678. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Nicodemus, K.K.; Malley, J.D.; Strobl, C.; Ziegler, A. The behaviour of random forest permutation-based variable importance measures under predictor correlation. BMC Bioinform. 2010, 11, 110. [Google Scholar] [CrossRef] [Green Version]
- Lei, J.; G’Sell, M.; Rinaldo, A.; Tibshirani, R.J.; Wasserman, L. Distribution-free predictive inference for regression. J. Am. Stat. Assoc. 2018, 113, 1094–1111. [Google Scholar] [CrossRef]
- Saabas, A. Tree Interpreter. 2014. Available online: http://blog.datadive.net/interpreting-random-forests/ (accessed on 10 May 2022).
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 4765–4774. [Google Scholar]
- Lundberg, S.M.; Erion, G.G.; Lee, S.I. Consistent individualized feature attribution for tree ensembles. arXiv 2018, arXiv:1802.03888. [Google Scholar]
- Loh, W.Y. Regression tress with unbiased variable selection and interaction detection. Stat. Sin. 2002, 12, 361–386. [Google Scholar]
- Kim, H.; Loh, W.Y. Classification trees with bivariate linear discriminant node models. J. Comput. Graph. Stat. 2003, 12, 512–530. [Google Scholar] [CrossRef] [Green Version]
- Loh, W.Y.; Shih, Y.S. Split selection methods for classification trees. Stat. Sin. 1997, 7, 815–840. [Google Scholar]
- Hothorn, T.; Hornik, K.; Zeileis, A. Unbiased recursive partitioning: A conditional inference framework. J. Comput. Graph. Stat. 2006, 15, 651–674. [Google Scholar] [CrossRef] [Green Version]
- Sabato, S.; Shalev-Shwartz, S. Ranking categorical features using generalization properties. J. Mach. Learn. Res. 2008, 9, 1083–1114. [Google Scholar]
- Frank, E.; Witten, I.H. Selecting Multiway Splits in Decision Trees; Working Paper 96/31; University of Waikato, Department of Computer Science: Hamilton, New Zealand, 1996. [Google Scholar]
- Frank, E.; Witten, I.H. Using a permutation test for attribute selection in decision trees. In Proceedings of the 15th International Conference on Machine Learning, Madison, WI, USA, 24–27 July 1998. [Google Scholar]
- Painsky, A.; Wornell, G. On the universality of the logistic loss function. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 936–940. [Google Scholar]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data 2009, 21, 1263–1284. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Regression RMSE | ||||
|---|---|---|---|---|
| Dataset | CVB | CatBoost | LGBM | Vanilla GBM |
| Allstate | 0.3115 | 0.3242 | 0.3120 | 0.3123 |
| (0.0036) | (0.0036) | (0.0038) | (0.0041) | |
| Bike Rentals | 0.2554 | 0.4484 | 0.2376 | 0.2470 |
| (0.021) | (0.0415) | (0.0096) | (0.0173) | |
| Boston HP | 0.0276 | 0.0241 | 0.0238 | 0.0243 |
| (0.0143) | (0.0102) | (0.0108) | (0.0115) | |
| Kaggle HP | 0.0185 | 0.0187 | 0.0162 | 0.0159 |
| (0.0038) | (0.0042) | (0.0034) | (0.0034) | |
| Classification Log-Loss | ||||
|---|---|---|---|---|
| Dataset | CVB | CatBoost | LGBM | Vanilla GBM |
| KDD upselling | 0.1686 | 0.1681 | 0.1733 | 0.3416 |
| (0.0074) | (0.0072) | (0.0071) | (0.0145) | |
| Amazon | 0.1716 | 0.1606 | 0.1724 | 0.2795 |
| (0.0186) | (0.0216) | (0.0243) | (0.0355) | |
| Breast Cancer | 0.1091 | 0.0933 | 0.1080 | 0.1043 |
| (0.0872) | (0.0682) | (0.1008) | (0.1008) | |
| Don’t Get Kicked | 0.3425 | 0.3433 | 0.3416 | 0.3584 |
| (0.0064) | (0.0066) | (0.0071) | (0.0070) | |
| Criteo CTR | 0.6161 | 0.6157 | 0.6241 | 0.9150 |
| (0.0083) | (0.0095) | (0.0124) | (0.0376) | |
| Adult | 0.2982 | 0.3021 | 0.2892 | 0.2917 |
| (0.0043) | (0.0095) | (0.0088) | (0.0038) | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adler, A.I.; Painsky, A. Feature Importance in Gradient Boosting Trees with Cross-Validation Feature Selection. Entropy 2022, 24, 687. https://doi.org/10.3390/e24050687
Adler AI, Painsky A. Feature Importance in Gradient Boosting Trees with Cross-Validation Feature Selection. Entropy. 2022; 24(5):687. https://doi.org/10.3390/e24050687
Chicago/Turabian StyleAdler, Afek Ilay, and Amichai Painsky. 2022. "Feature Importance in Gradient Boosting Trees with Cross-Validation Feature Selection" Entropy 24, no. 5: 687. https://doi.org/10.3390/e24050687