
Robust Universal Inference


1
The Industrial Engineering Department, Tel Aviv University, Tel Aviv 6997801, Israel
2
The School of Electrical Engineering, Tel Aviv University, Tel Aviv 6997801, Israel
*
Author to whom correspondence should be addressed.
Entropy 2021, 23(6), 773; https://doi.org/10.3390/e23060773
Submission received: 2 May 2021
/
Revised: 14 June 2021
/
Accepted: 15 June 2021
/
Published: 18 June 2021
(This article belongs to the Special Issue Applications of Information Theory in Statistics)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Learning and making inference from a finite set of samples are among the fundamental problems in science. In most popular applications, the paradigmatic approach is to seek a model that best explains the data. This approach has many desirable properties when the number of samples is large. However, in many practical setups, data acquisition is costly and only a limited number of samples is available. In this work, we study an alternative approach for this challenging setup. Our framework suggests that the role of the train-set is not to provide a single estimated model, which may be inaccurate due to the limited number of samples. Instead, we define a class of “reasonable” models. Then, the worst-case performance in the class is controlled by a minimax estimator with respect to it. Further, we introduce a robust estimation scheme that provides minimax guarantees, also for the case where the true model is not a member of the model class. Our results draw important connections to universal prediction, the redundancy-capacity theorem, and channel capacity theory. We demonstrate our suggested scheme in different setups, showing a significant improvement in worst-case performance over currently known alternatives.
1. Introduction
One of the major challenges in statistics and machine learning is making predictions and inference from a limited number of samples. This problem is mostly evident in modern statistics (big data), where the dimension of the problem is very large compared to the number of samples in hand, or in cases where data acquisition is relatively costly, and only a small number of samples is available (such as in complicated clinical trails). The standard approach in many applications is to seek a model that best explains the data. For example, empirical risk minimization (ERM) [1] is a commonly used criterion in predictive modeling. Minimizing the empirical risk has many desirable properties. Under different loss functions, we may attain consistency, unbiasedness, and other favorable attributes. In parametric estimation, perhaps the most popular approach is maximum likelihood. Here, again, we seek parameters that maximize the likelihood of the given set of observations.
However, what happens if our specific instance of data does not represent the true model well enough (as happens in high-dimensional problems)? Is it still desirable to choose the single model that best explains it?
In this work, we study an alternative approach for this challenging setup. Here, instead of choosing a model that best describes the data, we define a class of models that describe it with high confidence. Then, we seek a scheme that minimizes the worst-case loss in the class. This way, we control the performance over a class of reasonable models and provide explicit worst-case guarantees, even when the given data fail to accurately represent the true model. This scheme is, in fact, a data-driven approach of minimax estimation, as later discussed. Further, we show it provides worst-case guarantees for the expected regret of future samples. This property makes our framework applicable both for inference and prediction tasks.
One of the major challenges of our suggested scheme is to characterize the model class. In this work, we consider a class of models that corresponds to a confidence region of the unknown parameters. This way we provide a PAC-like generalization bound, as the true model is a member of this class with high confidence. Then, we introduce a more robust approach which drops the model class assumptions and provides stronger performance guarantees for the derived estimator. We demonstrate our suggested approach in classical inference problems and more challenging large alphabet probability estimation. We further study a real-world example, motivated from the medical domain. Our suggested approach introduces favorable worst-case performance, for every given instance of data, at a typically low cost on the average. This demonstrates an “insurance-like” trade-off; we pay a small cost on the average to avoid a great loss if “something bad happens” (that is, the observed samples do not represent the true model well enough).
The rest of this manuscript is organized as follows. In Section 2, we review related work to our problem. We introduce our suggested framework and some of its basic properties in Section 3. Then, we extend the framework to a more robust estimation scheme in Section 4. We demonstrate our suggested scheme in several setups. In Section 5, we study the unknown normal mean problem, while in Section 6 we focus on multinomial probability estimation. We consider a more challenging large alphabet probability estimation problem in Section 7. Finally, we study a real-work breast cancer problem in Section 8. We conclude with a discussion in Section 9.
2. Previous Work
Minimax estimation has been extensively studied over the years. Here, we briefly review the more relevant results for our work. Let be a collection of n i.i.d. samples, drawn from a distribution , where is a fixed and unknown parameter. Let be a given class of parameters. Assume that . Let be an estimator of from . Let be a risk function which measures the expected error between the true parameter and its corresponding estimate . For example, is the mean squared error. The minimax risk [2] is defined as
A minimax estimator satisfies , if such exists. In words, minimizes the worst-case risk for a given class of parameters . Finding the minimax estimator is, in general, not an easy task. However, the optimal solution is characterized by several important properties.
Let be a Bayes estimator with respect to some prior over . In words, is a weighted average of , according to a given weight function . Let be the average risk with respect to . One of the basic results in the minimax theory suggests that if , then is a minimax estimator and is a least favorable prior (satisfying for any ) [2]. Importantly, if a Bayes estimator has a constant risk, it is minimax. Note that this is not a necessary condition.
For example, consider the problem of estimating the mean of a d-dimensional Gaussian vector. Here, it can be shown that the maximum likelihood estimator (MLE) is also the minimax estimator with respect to the squared error. Interestingly, in this example, the MLE is known to be inadmissible for ; assuming that the mean is finite, the famous James–Stein estimator [3] dominates the MLE, as it achieves a lower mean squared error (where the phenomenon is more evident as the mean is closer to zero) [2,3]. Additional examples for the minimax estimators are provided in [2].
The minimax formulation was studied in a variety of setups. In [4], the authors considered minimax estimation of parameters over loss and provided key analytical results. These results were further studied and generalized (for example, see in [5]). Bickel studied minimax estimation of the normal mean when the parameter space is restricted [6]. Later, Marchand and Perron considered the case where the norm of the normal mean is bounded [7]. The minimax approach is also applicable to supervised learning problems. In [8], the authors considered minimax classification with fixed first- and second-order moments. Eban et al. developed a classification approach by minimizing the worst-case hinge loss subject to fixed low-order marginals [9]. Razaviyayn et al. fitted a model that minimizes the maximal correlation under fixed pairwise marginals to design a robust classification scheme [10]. Farnia et al. described a minimax approach for supervised learning by generalizing the maximum entropy principle [11].
The minimax approach has many applications, as it defines a conservative estimate for a given class of models. A variety of examples spans different fields including optimization [12], signal processing [13,14], communications [15], and others [16].
It is important to emphasize that the minimax problem (1), and its corresponding solution, heavily depend on the assumption that the unknown parameter is a member of the given class of parameters . However, what happens if this assumption is false, and (as discussed, for example, in [17,18,19])? Furthermore, how do we choose in practice? If we choose to be too large, we might control a class of models that are unreasonable. On the other hand, if is too small, we may violate the assumption that . Finally, notice that the minimax problem is typically concerned with the expected worst-case performance (the risk). However, in many real-world applications we are given a single instance of data, which may be quite costly to acquire. Therefore, we require worst-case performance guarantees for this specific instance of data. In this work, we address these concerns and suggest a robust, data-driven, universal estimation scheme for a given set of observations.
3. The Suggested Inference Scheme
For the purpose of our presentation, we use the following additional notations. Let be a restricted class of parameters and denote as the corresponding restricted class of parametric distributions. Assume that the true model is a member of (or alternatively, ). For example, is a normal distribution with an unknown mean and a unit variance, while is a set of all normal distributions with (henceforth, restricted to ) and a unit variance. Let be the class of all probability measures. Let be a probability measure which estimates given the samples . Notice that as opposed to the presentation in (1), the estimator q is with respect to the entire probability distribution , and not just unknown parameter . We measure the estimate’s accuracy using the Kullback–Leibler () divergence between the true underlying distribution and q, formally defined as . The KL divergence is a widely used measure for the discrepancy between two probability distributions, with many desirable properties [20]. In addition, the KL divergence serves as an upper bound for a collection of popular discrepancy measures (for example, the Pinsker inequality [21] and the universality results in [22,23]). In this sense, by minimizing the KL divergence, we implicity bound from above a large set of common performance merits.
Ultimately, our goal is to find an estimate q that minimizes for the unknown . Thus, we consider a minimax formulation
where is the minimizer of the worst-case divergence over the class , if such exists. In words, q minimizes the worst possible divergence, over the restricted model class . To avoid an overload of notation, we assume that throughout the text, unless otherwise stated. We observe several differences between (1) and (2). First, the formulation in (1) considers an estimate , and by that implicitly restricts the solution to be a parametric distribution of the same family as . On the other hand, (2) considers the entire distribution and does not impose any restrictions on the solution. Second, the standard minimax formulation (1) focuses on the risk. Our approach considers the estimation accuracy for every given instance of data (, as defined above). Third, notice that can also be viewed as the expected log-loss regret, where the expectation is with respect to a future sample, and is the logarithmic loss. This means that while (1) focuses on the expected loss with respect to the given samples, (2) considers the expected performance of future samples. We further discussed these points in Section 5, Section 6 and Section 8.
In practice, one of the major challenges in applying any minimax formulation is the choice (or design) of the parametric class. Specifically, using the notations of (2), choosing a larger class is more likely to include the true model , but may also include unreasonable worst-case models (for example, in the unknown normal mean example above). On the other hand, choosing a more restrictive may violate our assumption that . Therefore, a trade-off between the two seems inevitable. In the following, we focus on the design and characterization of a set that depends on the given samples, . In other words, we use the train-set to construct a minimal-size restricted model class that contains the true parameter with high confidence. Then, we solve the minimax problem (2) with respect to it and attain an estimator that minimizes the maximal divergence in the class (or equivalently, the expected log-loss regret for future samples).
Designing and Controlling the Restricted Model Class
Our first objective is to construct a minimal-size such that with high confidence. For this purpose, we turn to classical statistics and construct a confidence region for the desired parameter . A confidence region of level is defined as a region such that . Notice that is random and depends on the samples , while is an unknown (non-random) parameter. Further, notice that a confidence region is data-dependent and does not require knowledge of the true parameter . Obviously, there are many ways to define to satisfy the above. We are interested in a confidence region that has a minimal expected volume. For example, consider n i.i.d. samples from , as discussed above. Let be the sample mean. Then, the minimal-size confidence interval is , where is the upper percentile of a standard normal distribution [24].
Given the restrictive model class, we would like to solve the minimax problem defined in (2). A general form of this problem was extensively studied over the years, mainly in the context of universal compression and universal prediction [15]. There, is the expected number of extra bits (over the optimal code-book), required to code samples from using a code designed for q. The celebrated redundancy-capacity theorem demonstrates a basic connection between the desired formulation (2) and channel capacity theory. Let be a source variable, X be a target variable and be the set of transition probabilities from X to T. In other words, T is a message, transmitted through a noisy channel, characterized by . The received (noisy) message is denoted by X. Let be the mutual information between T and X, and be the corresponding channel capacity. The redundancy-capacity theorem [25,26,27] suggests that for , the minimax formulation presented in (2) is equivalent to
where is a weight function for every and is a mixture distribution. In words, solving (2) is equivalent to solving a channel capacity problem. Furthermore, the source distribution which maximizes the mutual information between the source and the target (and henceforth achieves the channel capacity) is a mixture over . This solution is quite similar to the solution of (1); in both cases, we obtain a Bayes estimator over the given class, while the least favorable prior (or equivalently, the capacity achieving prior), if such exists, attains the maximal average risk (the channel capacity). See examples in Section 5 and Section 6 for further detail. It is important to emphasize that while is a fixed and unknown parameter, is a weight function for every , and is a weighted average over .
The redundancy-capacity theorem shows that the solution to the minimax problem (2) is achieved by solving the channel capacity problem (3). We apply the capacity-redundancy theorem to our suggested class to attain the desired solution. Theorem 1 below summarizes our parametric inference approach.
Theorem 1.
Let be a collection of n i.i.d. samples, drawn from an unknown distribution . Let be a confidence region for the parameter θ. Assume that . Then, with probability (over the samples), is the minimal worst-case divergence and is the corresponding minimax estimator, denoted as the mixture model.
Theorem 1 establishes a PAC-like generalization bound for parametric inference. It defines the worst-case expected performance of future samples (with respect to a logarithmic loss, as discussed above), at a confidence level of over the drawn samples. Specifically, with probability we have that for the entire parametric class. It is important to emphasize that the resulting minimax estimator is data-dependent, as it is a mixture over the data-driven restricted model class.
4. A Generalized Inference Scheme beyond the Restricted Class
In the previous section, we derive a minimax solution to (2) under the assumption that (equivalently, ), with high confidence. Unfortunately, it does not provide any guarantee for the event where . We now consider a general setup where is not necessarily in as well as introduce a more robust approach which addresses this case.
Let be a (non-restricted) model class that is known to contain the true parametric model . Here, we define as the set of all possible parameter values, such that . For example, is a class of all normal distributions with an unknown mean and a unit variance (), in the normal mean example above. As before, we would like to find a distribution q that minimizes . Simple calculus shows that
for any choice of . Specifically, (4) holds for any model in the restricted model class, . Notice that in this case, the first term of (4) is an error induced by the restrictive model class, independent of the choice of q. The second term is the residual, which depends on q. Notice that the first term only depends on and the reference distribution . This means that by choosing a model class that is too “far” (or from the true distribution), we face a large overhead term that is independent of the estimator q. On the other hand, the second term depends on q, and may be universally bounded. In other words, we are interested in a universal bound of the form
Interestingly, notice that (5) may be equivalently written as
This means that (5) is just a constrained variant of (2). Therefore, similarly to (2), we would like to represent (5) as a (constrained) channel capacity problem.
Definition 1.
Let be an unknown probability distribution. Let be a restrictive model class (that does not necessarily contain ). Assume that is bounded. Define
As in (2), is the mutual information between a source variable , and a target variable X, that is characterized by the transition probabilities . The constraint is simply the expected divergence (with respect to ) between and its closest projection in . The term is a mixture distribution over , according to the prior . Notice that here, the mixture is over the non-restricted model class, as opposed to (2), where the mixture is over . We denote this distribution, , as the projected mixture distribution.
Theorem 2.
Let be an unknown probability distribution. Let be a restrictive model class (that does not necessarily contain ). Assume that is bounded. Then, for the following holds:
A proof of Theorem 2 is provided in Appendix A. Theorem 2 establishes a redundancy-capacity result, similarly to (2). It shows that (5) may be obtained by solving a constrained channel capacity problem, and the distribution which achieves it is, again, a mixture distribution. This result is further discussed in [28] in a different (asymptotic) setup.
In addition, notice that for a bounded the formulation in (5) may be equivalently written as
where . In other words, is also the optimal universal minimizer of the second term of (4), for a specific (greedy) choice of that minimizes the first term. This result may be viewed as a “triangle inequality” for the KL divergence: given a reference set , the KL divergence is bounded from above by the closest projection in to , plus an overhead-term . It is important to emphasize that is not new to the universal coding literature. In fact, it was introduced in [17] as relative redundancy, in the context of robust codes for universal compression. However, it was mostly studied in an asymptotic regime, where n i.i.d. variables are simultaneously compressed. However, it was mostly studied in an asymptotic regime, where n i.i.d. variables Xn are simultaneously compressed [28].
Similarly to the channel capacity problem, the term holds a closed-form analytical expression only in several special cases. Therefore, we introduce a simple iterative algorithm, which provides an optimal solution to it (as indicated in [28]). Our suggested routine is similar in spirit to the Blahut–Arimoto algorithm [21], which is typically applied to intractable channel capacity problems.
Theorem 3.
Let and be two model classes. Let follow the definition above. Assume that is bounded. Then, for the following holds:
where and are probability distributions (over the variable θ, for any given x), and . Further, the solution to (9) may be attained by the following iterative projection algorithm:
- For a fixed , we set
- For a fixed , we set where .
Finally, the distribution q that achieves is given by , where is at the final iteration of the algorithm.
A proof for this theorem is provided in Appendix B.
In many practical cases, the choice of a model class is not a trivial task. For example, consider a real-world setup where a domain expert suggests that the underlying model follows a Normal distribution with an unknown mean. However, we would like to design a scheme that does not heavily rely on this assumption. Therefore, we may consider the general case where is the simplex of all possible probability distributions. This important special case described in the following section.
The Normalized Maximum Likelihood
Consider a model class . Here, the solution to (7) holds a closed form expression.
Theorem 4.
Let be an unknown probability distribution where . Let be a restrictive model class. Assume that is bounded and . Let . For ,
and the model q that achieves the minimum is the normalized maximum likelihood (NML) [29],
This theorem is an immediate application of Shtarkov’s NML result [29]. It suggests that given a model class which does not necessarily contain the true model p, the NML estimator minimizes the worst-case regret over all possible distributions and guarantees an overhead of at most bits, compared to the best model in the class , for any possible p. Further, it is shown that this result is tight, in the sense that there exist probability distributions and that achieve the term. Notice that for every and that satisfy the conditions above, we have that This means that under more restrictive assumptions we attain tighter worst-case performance guarantees, as expected. We now demonstrate our suggested methods in synthetic and real-world problems.
5. The Normal Distribution
Let us first study the classical unknown mean problem in the Gaussian case. Consider n i.i.d. samples, drawn from a d-dimensional multivariate normal distribution with an unknown mean and a known covariance matrix . The confidence region for is , where is the sample mean, and is a Chi-squared distribution with d degrees of freedom. First, we would like to solve the minimax problem (2) with respect to . We apply the redundancy-capacity theorem (3) and define a corresponding channel, , where M is a random vector, taking values over the domain , while , independent of M (see [30] for detail). This formulation is also known as an amplitude-constrained capacity problem. We show (Appendix C) that it is equivalent to the generic case where and where . Notice that the domain of M is now restricted to a d-dimensional ball (defined by ) and our goal is to find the capacity achieving distribution of M. It has been shown [31] that the solution to this problem is achieved when M is supported on a finite number of concentric spheres. Recently, the authors of [32] studied the necessary conditions under which the solution is a single sphere, centered at the origin. Specifically, they derived the largest radius for which the capacity achieving distribution is uniform on the sphere of the d-dimensional ball. This means that if the radius defined by is smaller than , then the solution to our minimax problem is immediate. Applying Dytso et al. analysis to our problem, we attain the following result.
Theorem 5.
Let be a collection of n i.i.d. samples from a d-dimensional multivariate normal distribution with an unknown mean μ and a known covariance matrix Σ. Let be a confidence region for μ. Let be the largest radius for which the capacity achieving distribution is uniform on the sphere of a d-ball, as defined in Table 1 of [32]. Then, for any , the solution to the minimax problem (2) over the confidence region is attained by a uniform mixture of Gaussians with means on the confidence region, where .
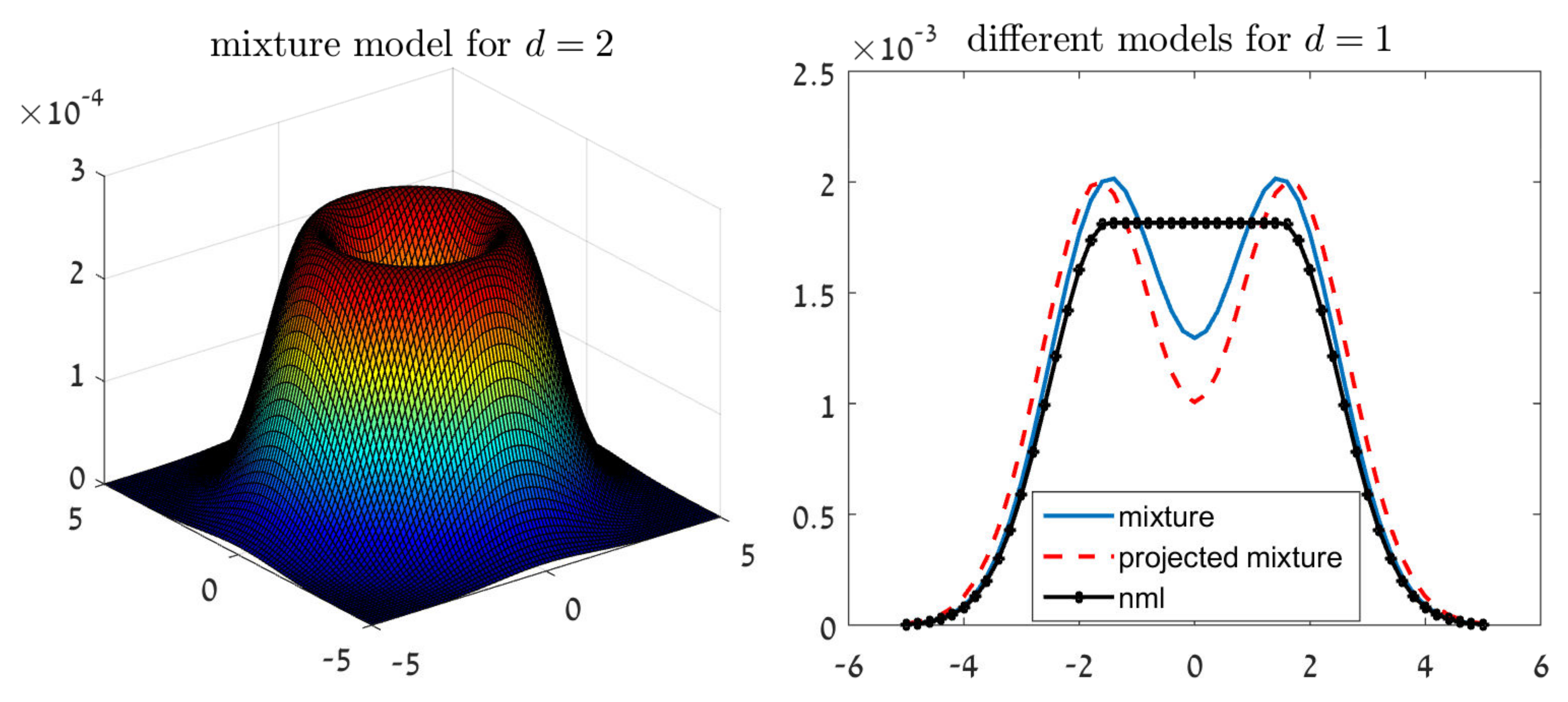
For example, let and . We have that (as appears in Table 1 of [32]), and the solution to (2) over is given by , for every . The left chart of Figure 1 illustrates the shape of in this case. This Gaussian mixture shape may seem counterintuitive at a first glance, as are known to be drawn from a normal distribution. However, the reason is quite clear. Our inference criterion strives to control a set of Gaussian models. Therefore, the optimal solution is not necessarily the most likely model in the set, but a mixture of models.
Let us now turn to the projected mixture distribution and the NML. The right chart of Figure 1 demonstrates the shape of these estimators for and .
First, we notice that the projected mixture is again a Gaussian mixture, with means outside of the confidence interval. On the other hand, the NML solution is not a Gaussian mixture; simple calculus shows that
for a symmetric confidence interval .
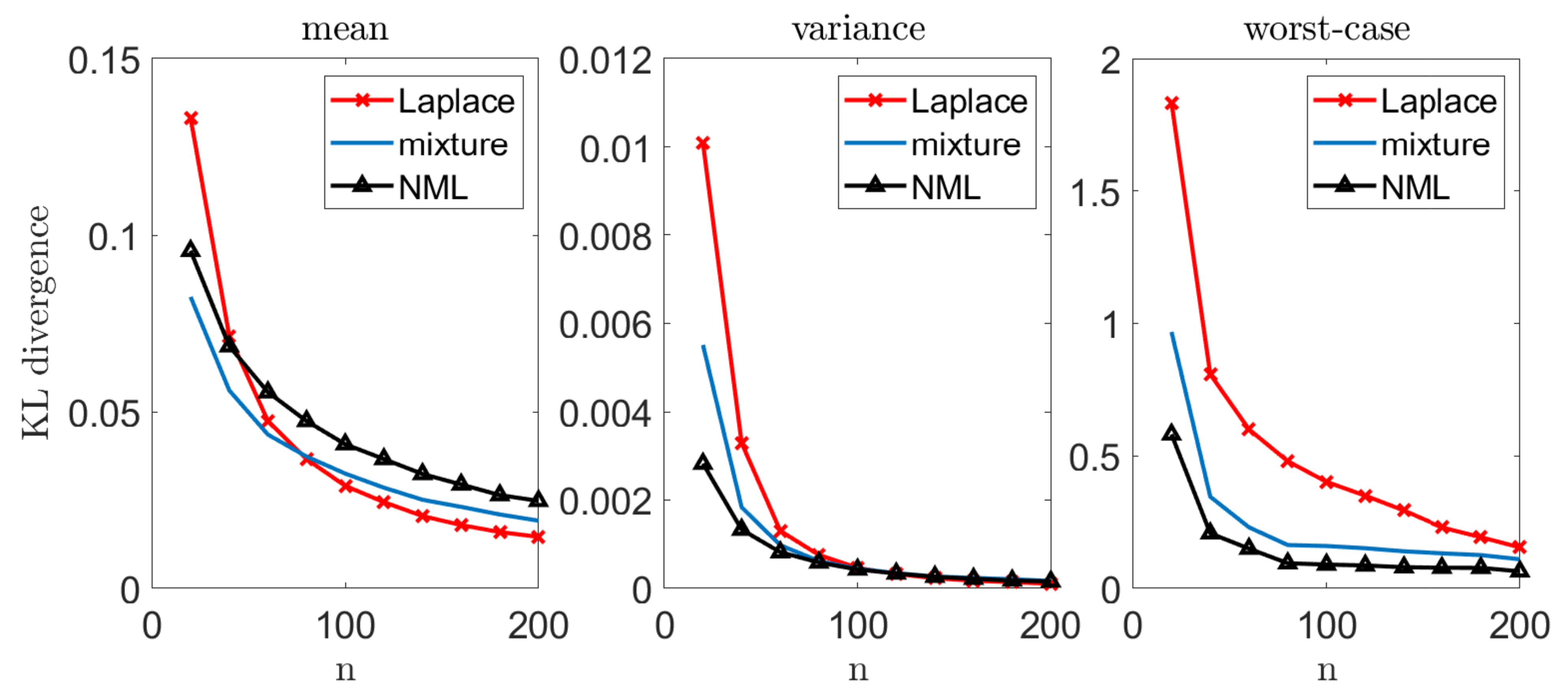
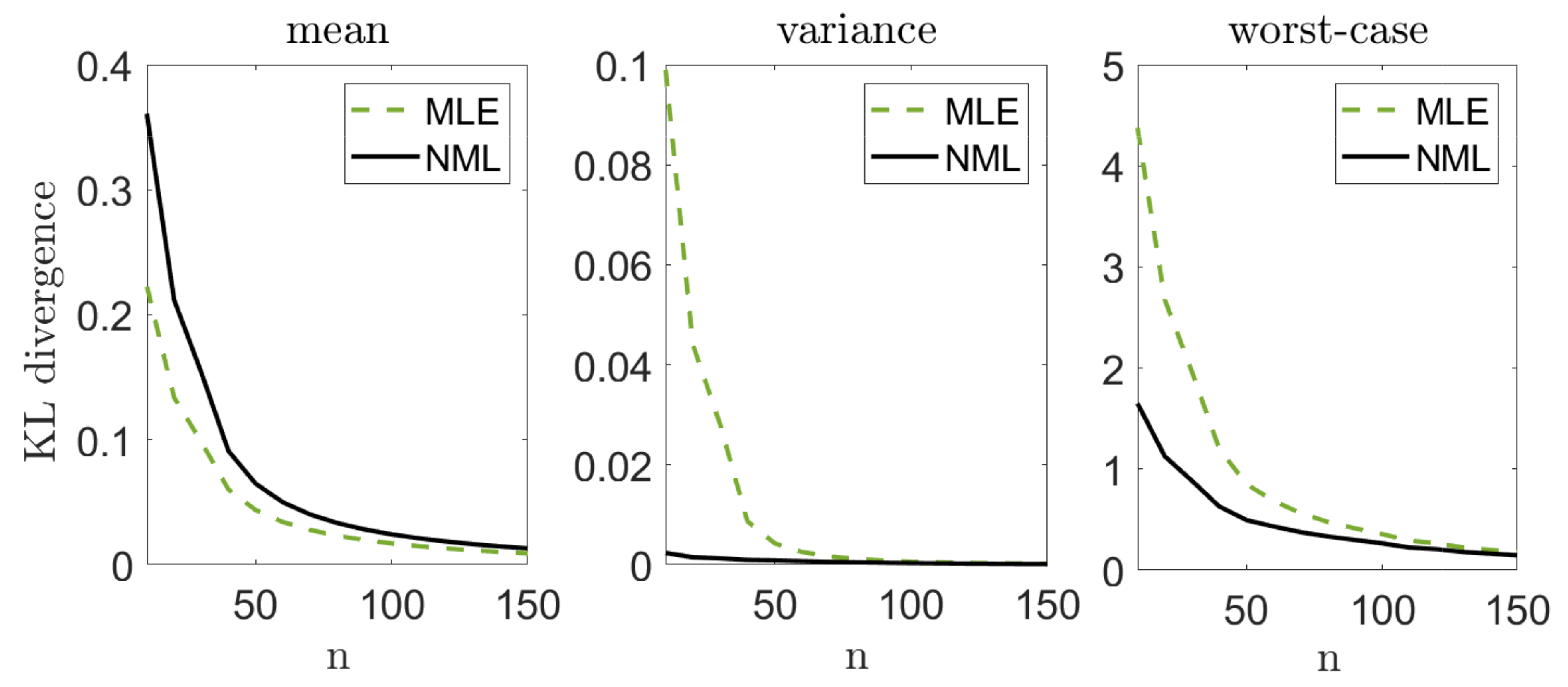
Let us illustrate the performance of our suggested methods. We draw n i.i.d. samples from a standard normal distribution where the mean is unknown and the variance is known. We apply our suggested methods (with ) and evaluate the divergence from the true distribution, . We compare our results with the performance of the MLE, , where . Notice that the MLE is also known to be the minimax solution to (1) in this setting. We repeat this experiment k = 10,000 times, for different sample sizes n. For each n we evaluate the mean , the variance and the worst-case , where is the set of k random draws of from . Figure 2 demonstrates our results. Notice that we lose some accuracy, on the average, with all of our methods, compared to the MLE. On the other hand, the variance of the MLE is significantly greater, which suggests that it is less reliable for a given instance of data. Finally, we notice a significant gain in the worst-case performance. This behavior is not surprising: our approach strives to control the worst-case performance for each given draw. In this sense, we may view our approach as an “insurance policy”—we pay a small cost on the average, but attain a more stable estimator and gain significantly if “something bad happens” (that is, we observe that do not represent the true model well enough). Notice that this phenomenon is more evident when the inference problem is more challenging (smaller n’s). As we compare our suggested models to each other, we notice that the mixture distribution is the most conservative (that is, smallest cost and smallest gain), while the projected mixture is the least conservative. The reason is quite clear: in about of the draws, the true parameter lies within the confidence region, and the mixture distribution is closer to it. This implies better performance on the average and worse performance in the extremes. Interestingly, the NML behaves as a compromise between the two. This is mostly as the NML does not assume that (better than the mixture in the worst-case). However, it also unnecessarily controls non-Gaussian models (worse than the projected mixture).
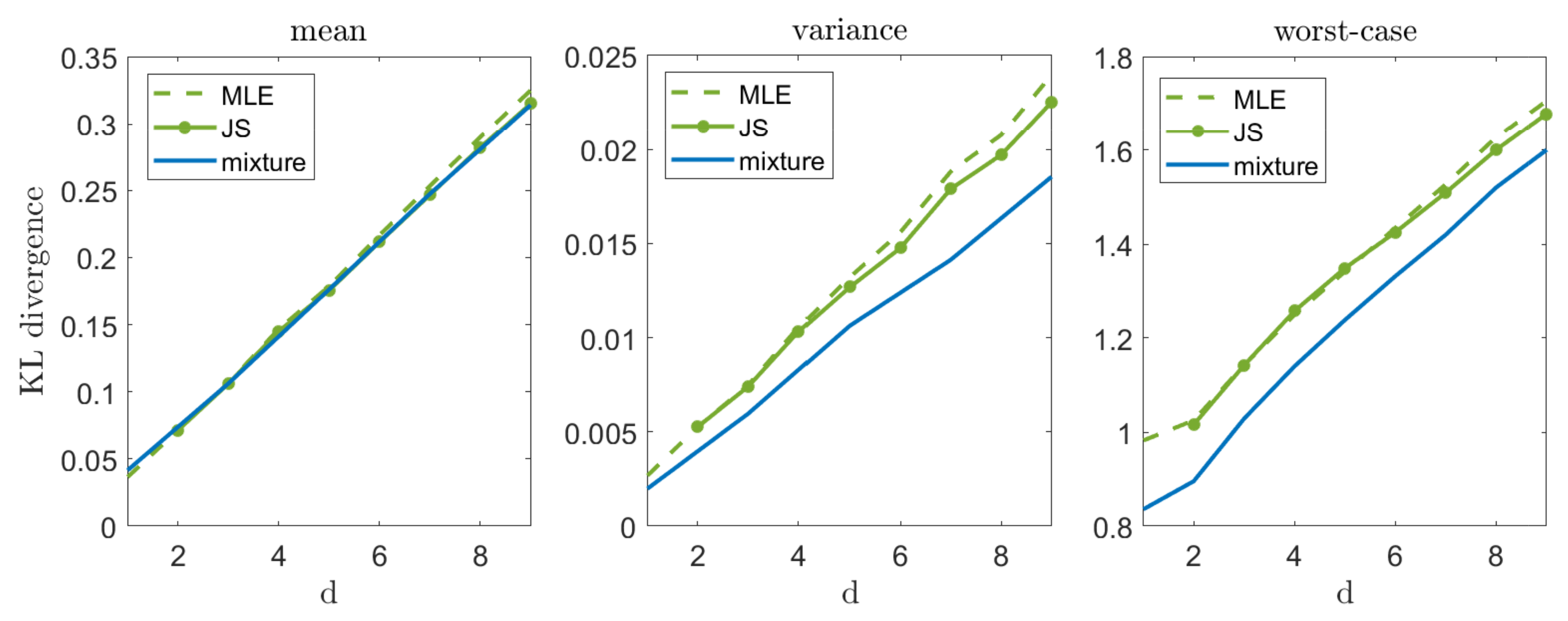
Let us now illustrate our suggested approach in a high-dimensional setting, . Figure 3 compares the mixture estimator (which demonstrates a reasonable compromise between mean and worst-case performance) with the MLE and the James–Stein (JS) estimator. As we can see, the JS estimator slightly outperforms MLE on the average (as discussed in [3]), while the mixture distribution is very close to them. However, as we focus on the variance and the worst-case performance, the mixture distribution demonstrates a significant improvement, as expected. It is important to mention that in a zero mean case, the JS estimator achieves a significantly lower mean error (as discussed in [2]) and a remarkable increase in variance and worst-case performance. These results are omitted for brevity.
6. The Multinomial Distribution
We now turn to an additional important example of finite alphabet distributions. Let be n i.i.d. draws from a multinomial distribution over an alphabet size m. Notice that here, the parametric family spans the entire simplex. Therefore, we omit the parametric subscript to avoid an overload of notation, and regard p as the unknown vector of parameters. As discussed above, we would first like to construct a minimal-volume confidence region for p, denoted as . Unfortunately, there exists no closed-form solution in the multinomial case. Therefore, we turn to an approximate confidence region suggested in [33]. As many other approximation techniques [34,35], Sison and Glaz derive a rectangular region which demonstrates a smaller expected volume compared to alternatives. Our first step is to define a subset of Sison and Glaz region, , which corresponds to valid probability distributions, . Notice that is a convex set, and denote its set of vertexes as . We show (Appendix D) that the solution to (2) over is attained by solving (3) over . This means that instead of considering the entire class , we only need to focus on the discrete set .
Unfortunately, there exists no closed-form solution to (3) in this setting. However, as the cardinality of is finite (as we optimize over ), we may apply the Blahut–Arimoto algorithm [21] and attain a numerical solution, at a relatively small computational cost. Finally, we derive the projected mixture and the NML. As mentioned above, the parametric family spans the entire simplex. This means that the two methods are identical, and obtained by applying the NML over .
We now demonstrate our suggested approach. Let be i.i.d. draws from a Zipf’s law distribution over an alphabet size and a parameter , . The Zipf’s law distribution is a commonly used benchmark distribution, mostly in modeling of natural (real-world) quantities. It is widely used in physical and social sciences, linguistics, economics, and many other fields [36,37,38]. As in Section 5, we compare our suggested methods to the MLE. In addition, we consider the popular Laplace estimator, which adds a single count to all events, followed by a MLE. In our experiments we focus on an enhanced variant of Laplace [39], which adds to all events, , where is the number of appearances of the ith symbol in . This variant holds important universality properties and is widely known as the Krichevsky–Trofimov estimator [39,40].
We repeat each experiment k = 10,000 times and report the estimated mean, variance, and worst-case performance, as in the Gaussian case. Figure 4 demonstrates the results we achieve. We omit the MLE as it typically results in an unbounded divergence (in cases where at least a single symbol fails to appear).
As in the unknown normal mean problem, we notice that in more challenging setups (small n), our worst-case gain is quite remarkable. This gain narrows down as n increases, and all the estimators converge to the same solution. In addition, we observe a significant gain in expectation when n is small. It is important to emphasize that when the underlying distribution is easier to infer (all are bounded away from zero, as with the uniform distribution), the advantage of using the minimax approach is less evident (similarly to the large n regime in the Zipf’s law example).
7. Large Alphabet Probability Estimation
In the large alphabet regime, we study a multinomial distribution where . This problem has been extensively studied over the years, with many applications ranging from language processing to biological studies [41]. Here, traditional methods like MLE are typically ineffective, as they assign a zero probability to unseen events. Several alternatives have been suggested over the years. In his seminal work, Laplace [42] suggested to add a single count to all events, followed by a maximum likelihood estimator. The work of Laplace was later generalized to a class of add-constant estimators [39], with the important special case of the Krichevsky–Trofimov estimator (as discussed in Section 6). A significant milestone in the history of large alphabet probability estimation was established in the work of Good and Turing [43]. Their approach suggests that unseen events shall be assigned a probability proportional to the number of events that appear once. To this day, Good–Turing estimators are the most commonly used methods in practical problems (see, for example, Section 1.4 in [41]). Despite the great interest in large alphabet estimation, provably-optimal schemes remain elusive [41]. Moreover, the accuracy of existing methods do not allow us to construct practical confidence regions. In fact, Paninski [44] showed that in the large alphabet setup, the minimal expected worst-case divergence is unbounded, and grows like . Therefore, it is quite difficult to define a small enough restrictive model class that contains p with high confidence. In this case, we introduce an alternative approach for the design of , followed by an NML estimator.
The Leave-One-Out Hypothesis Class
Define the convergence rate of as We say that an estimator is proper if it satisfies, for every p,
- for all
- for all
- is monotonically non-increasing for all
The first condition states that the expected loss is finite for any n. The second condition indicates that asymptotically, adding more samples only improves the expected accuracy. The third condition says that the rate of the improvement is non-increasing in the number of samples. For example, the improvement from 100 to 101 samples is greater than the improvement from 1000 to 1001 samples, on the average. We now define the leave-one-out model class. Let be the leave-one-out set of , excluding the sample. Let be the corresponding proper estimate. The leave-one-out (loo) model class is defined as . Theorem 6 below establishes that on the average, the accuracy of the best model in is bounded from above by accuracy of , plus an additional vanishing overhead term.
Theorem 6.
Let q be a proper estimator. Then,
A proof for this Theorem is provided in Appendix E. Notice that the inequality is due to the convexity of the different operators. This means that typically, we expect the inequality to be strict. In other words, given a proper estimator q, Theorem 6 shows that on the average, there exists at least a single model in that is better than , up to a vanishing overhead term of . In Appendix F we show that any add-constant (Laplace) estimator satisfies (11). Further, our experiments indicate that the same property holds for the Good–Turing estimator. This motivates the use of these estimators in the design of , as suggested by (4).
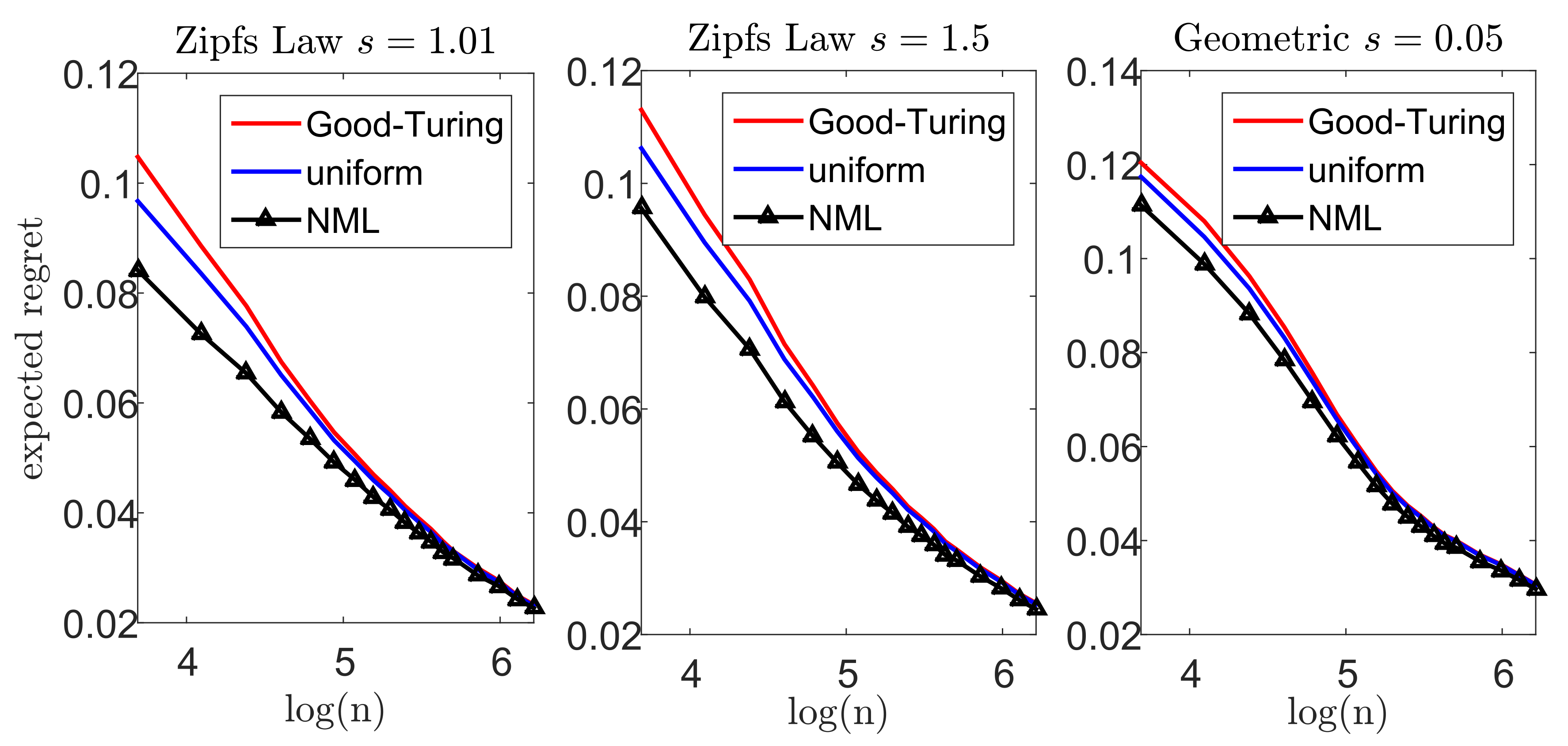
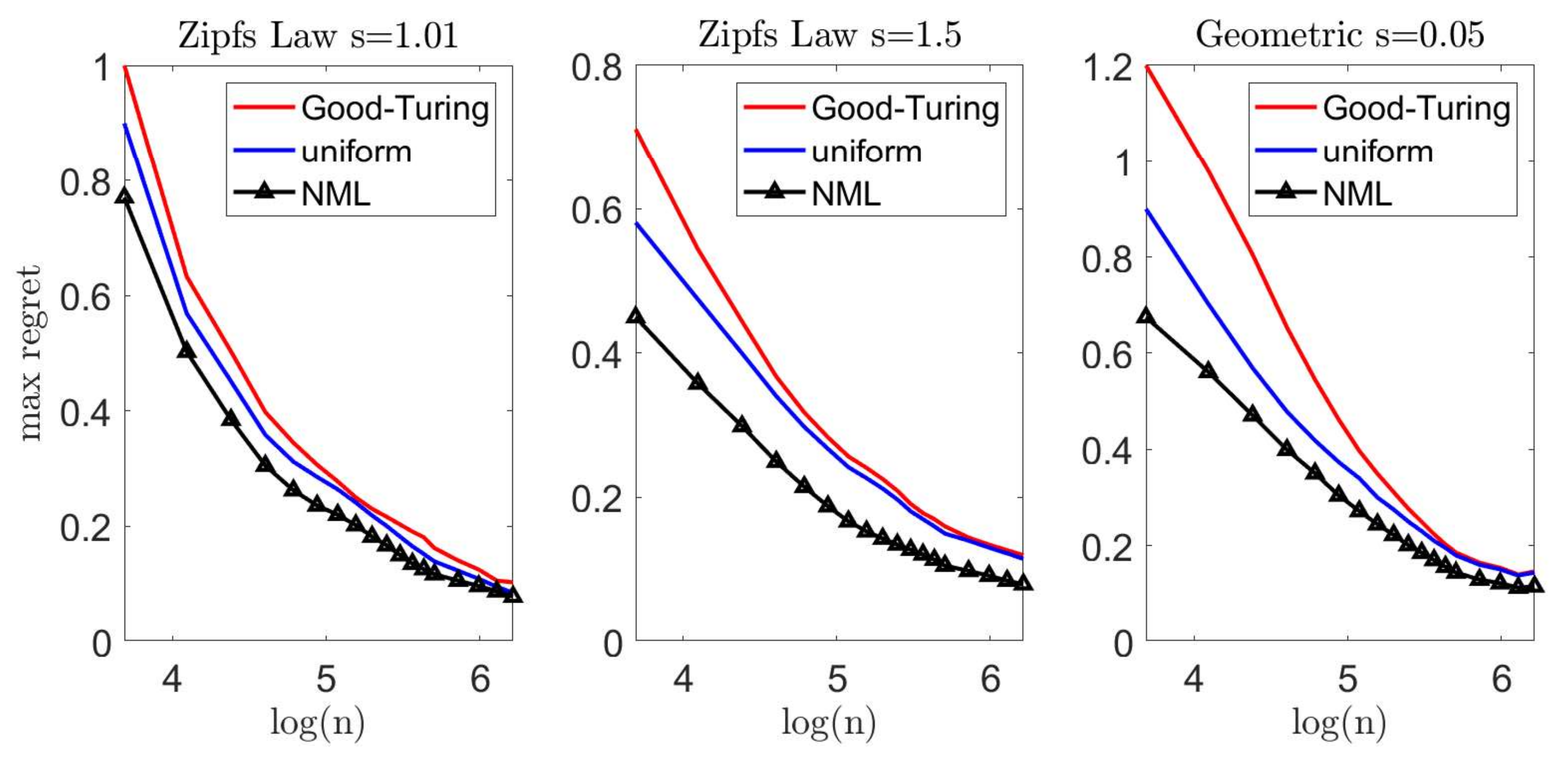
Let us now demonstrate our suggested scheme. In each experiment, we draw n samples from a multinomial distribution over an alphabet size . We apply the Krichevsky–Trofimov estimator, , and a Good–Turing estimator, following the implementation of Gale [45]. We compare these estimators to our suggested scheme; we construct a loo model class using Good–Turing, followed by an NML estimator. In addition, we compare the NML with a simple uniform average over the loo model class. A comprehensive description of our suggested scheme is provided in Appendix G. To emphasize the difference between the suggested schemes, we compare each estimator with a natural oracle; an estimator who knows the true model p, but is restricted to assign the same probability to symbols that appear the same number of times in . The performance of this oracle serves as a lower bound [41]. Figure 5 and Figure 6 demonstrate the results we achieve for a Zipf’s law distribution with a parameter value of (left) and (center). In addition, we consider a geometric distribution with (right). We report the expected difference (regret) between and in Figure 5, while the worst-case regret is presented in Figure 6. We omit the uncompetitive performance of the Krichevsky–Trofimov estimator.
As we observe Figure 5, we notice that our suggested NML method outperforms Good–Turing when the alphabet size is relatively small. As n increases, the improvement becomes less evident as the restrictive model class converges to . Further, we notice that a uniform average over the loo model class is also favorable, but demonstrates a slighter improvement. Finally, we compare the worst-case performance in Figure 6. Here, again, we notice a significant improvement as in the previous experiments. For example, for and a Zipf’s law distribution (), the Good–Turing results in a regret of bits while the uniform mixture is bits and the NML is only bits.
8. Real-World Example
Let us now introduce a real-world example. The Wisconsin breast cancer study (https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Diagnostic), accesed on 14 June 2021) considers 569 diagnosed tumors, of which 357 are benign (B) and 212 are malignant (M) [46]. Each tumor is characterized by 32 features, including its size, texture, surface, and more. We would like to study the radius of benign tumors and assess its probability function. This probability is of high interest as it allows us, for example, to control type-I error in a future hypothesis testing (the probability of deciding a tumor is malignant, given that it is benign).
The medical domain knowledge suggests that the size of the tumor follows a normal distribution, with different parameters for the B and M tumors. Therefore, the standard approach is to estimate the parameters from the given data. For simplicity, we assume the true variance is known (estimated from the entire population) and focus on the unknown mean.
As in the previous sections, we study the performance of different estimation schemes. We draw n samples from the B class, and apply the MLE and the suggested NML scheme. Notice that we focus on the NML as it is the most robust approach for the modeling assumption (and henceforth most suitable for such a clinical trail). We repeat this experiment 10,000 times for every value of n and report the mean, variance, and worst-case KL divergence between the “true empirical distribution” (based on all the B samples that we have) and each estimator that we examine. Figure 7 demonstrates the results we achieve. As we can see, our suggested approach attains a significantly better worst-case results.
It is important to emphasize that the MLE is the solution to the classical minimax estimation scheme (1), under the assumption that the data is generated from normal distribution (see Section 2). Our approach with the NML relaxes this strong restriction and attains a significant improvement in the worst-case performance.
9. Discussion and Conclusions
In this work, we study a minimax inference framework. Our suggested scheme considers a class of models, defined by the parametric confidence region of the given samples. Then, we control the worst-case performance within this class. Our formulation relaxes some strong modeling assumptions of the classical minimax framework and considers a robust inference scheme for the complete unknown distribution. The attained solution draws fundamental connections to basic concepts in information theory. We demonstrate the performance of our suggested framework in classical inference problems, including normal and multinomial distributions. In addition, we demonstrate our suggested scheme on more challenging large alphabet probability estimation problems. Finally, we study a real-world breast cancer example. In all of these settings we introduce a significant improvement in the worst-case, at a typically low cost on the average. This demonstrates an “insurance-like” trade-off; we pay a small cost on the average to avoid a great loss if “something bad happens” (that is, the observed samples do not represent the true model well enough).
It is important to emphasize that our suggested scheme is not limited to confidence region model classes. In fact, in many cases, exact confidence regions are difficult to attain, or result in model classes that are too large to control (for example, large alphabet problems with many unseen symbols). In these cases, we consider alternative forms of “reasonable” classes of models. One possible solution is the leave-one-out (LOO) class, discussed in Section 7. Additional alternatives are bootstrap confidence regions, Markov Chain Monte Carlo (MCMC) sampling and others.
Finally, our suggested scheme may be generalized to a supervised learning framework. For example, consider a linear regression problem. The standard approach is to estimate the regression coefficients that best explain the data (typically by least squares analysis). However, notice we may also construct confidence intervals for the sought coefficients. This way, we can define a restricted model class (similarly to Section 3), and seek minimax estimates with respect to it. This idea may be generalized to more complex learning schemes such as deep neural networks. Specifically, we may construct a restricted model class as the vicinity of some class of parameters that the network converges to, and control the corresponding worst-case performance. We consider this direction for our future work.
Author Contributions
Conceptualization, A.P. and M.F.; methodology, A.P. and M.F.; software, A.P.; validation, A.P. and M.F.; formal analysis, A.P. and M.F.; investigation, A.P.; resources, M.F.; data curation, A.P.; writing–original draft preparation, A.P.; writing–review and editing, A.P. and M.F.; visualization, A.P.; supervision, M.F.; project administration, M.F.; funding acquisition, A.P. and M.F. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Not applicable.
Acknowledgments
The authors would like to thank Yury Polyanskiy for helpful discussions.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. A Proof of Theorem 2
Let be an unknown probability distribution. Let be a restrictive model class that corresponds to a restricted set of parameters . We would like to solve the minimax problem
where . Let us now define an equivalent problem to (A1),
where is a weight function satisfying and . Notice that the equivalence holds since for a fixed q, a weight function which puts all probability mass on the worst is a least favorable function. Let us now change the order of the minimum and supremum, similarly to the redundancy-capacity theorem (3).
Let be the collection of all measures (on X) that can be obtained as mixtures of the measures. Let be the closure of . Define
Notice that if , then . This holds as for every , the mixture , which minimizes is (see, for example, [27]). Therefore, we would like to show that . Here, we follow the steps of [27] and Sion’s minimax theorem [47].
Theorem A1
(Sion’s Minimax Theorem [47]). Let be a compact convex subset of a linear topological space and be a convex subset of a linear topological space. If is a real-valued function on with
- is upper semi-continuous and quasi-concave on for all
- is lower semi-continuous and quasi-convex on for all
then, .
Let us first assume that is uniformally tight. In other words, for every there exists a compact set such that for all . Haussler showed that if is uniformally tight, then it is totally bounded, and thus is compact [27]. Therefore, for we have that
where:
- (a)
- follows from definition
- (b)
- follows from Sion’s minimax theorem
- (c)
- for every , the distribution q which minimizes is a mixture distribution [27]. Notice that does not depend on q.
This means that . On the other hand, it is easy to verify that due to the max-min inequality [48]. This means that as desired.
Let us now assume that that is not uniformally tight. Haussler showed that in this case, (Lemma 4 in [27]). Therefore, given that for all (as is bounded), we have that . However, this contradicts .
Appendix B. A Proof of Theorem 3
Assume that is bounded. Let . Then,
Similarly to the channel capacity problem, this optimization does not hold a closed form solution in the general case. Therefore, we introduce an alternating projection algorithm, similar in spirit to the Blahut–Arimoto algorithm [49,50]. For this purpose, we apply the well-known alternating maximization theorem (Lemma and in [51]).
Lemma A1 (The Alternating Maximization Theorem [51]).
Let be a real, concave and bounded-from-above function that is continuous and has continuous partial derivatives. Let and be two convex sets. Consider an optimization problem
Denote = and = . The alternating maximization algorithm is an iterative process where in each iteration k we maximize over one of the variables. Let be an arbitrary starting point in . For let and let . Assume that and are unique for all and , then .
Let us reformulate (A5) according to the requirements of Lemma A1. First, we multiply the numerator and the denominator in the log by . We attain
Define the following maximization problem:
where and are convex sets. We now show that (A8) satisfies the conditions of the alternating maximization algorithm. First, we notice that our objective is real, concave, and bounded from above (as ). Lemmas A2 and A3 below show that there exists a unique maximum for every and , similarly to the Blahut–Arimoto algorithm for the channel capacity problem.
Lemma A2.
Proof.
Define . Further, define . We have that
where the second equality follows from the definition of above. □
Lemma A3.
where
Proof.
We apply calculus of variations and attain the optimality condition. Define the Lagrangian as
Then, the Euler–Lagrange condition requires that the partial derivative of the integrand with respect to is zero. This yields
where . Therefore, as desired. □
Appendix C
Let be a d-dimensional Gaussian vector where is unknown and is known. Let be a collection of n i.i.d. draws from X. Define a confidence region for as a collection , as defined in Section 5. As previously established (and shown in [30]), our minimax problem is equivalent to a channel capacity problem where and , independent of M.
Let be the singular value decomposition (SVD) of and be the diagonalizing transformation of Z, such that . Define . Notice that , given that A is invertible. Let us study . We have that and
This means that satisfies where
Therefore, the channel is again a standard amplitude constrained Gaussian channel, where the input is now a sphere around , instead of .
Finally, we define . Let and . We have that where Further, we have that . This means that our original minimax problem is equivalent to a standard, centered, amplitude-constrained channel capacity problem.
Appendix D
Let be convex combination of . Assume that satisfies for all . Notice that every can be described as a convex combination of the vertexes (since is a convex set). Therefore, we have that . This means that satisfies that optimality conditions over the set . In other words, the solution to the minimax problem (2) over the confidence region is attained by solving the capacity-redundancy problem (3) over its finite set of vertexes .
Appendix E. A Proof for Theorem 6
Let us first introduce the following Lemma.
Lemma A4.
Let q be a proper estimator. Then,
Proof.
Applying a simple mathematical induction,
where the finiteness is due to Condition A. Therefore, we necessarily have that the series converges. Conditions B and C state that is non-negative and monotonically non-increasing. Therefore, simple calculus shows that , which implies that . □
Now, define the leave-one-out model class as . We have that
where the first inequality is due to Jensen inequality and the second inequality is due to Lemma A4.
Appendix F
Define the expected convergence rate of an estimator as
The add-constant estimator follows where is the added constant. We have
For we have that . Further, . Therefore, , leading to
Appendix G
One of the basic properties of most widely used finite alphabet estimators (MLE, add-constant, Good–Turing, and others) is the natural assumption; symbols that appear the same number of times are assigned the same probability estimate. This is not surprising, as it is easy to show that natural estimators maximize the expected estimation accuracy for a given set of samples (for example, see the work of Orlitsky and Suresh [41]). A natural estimator has degrees of freedom where k is the number of symbols with a unique frequency values (the cardinality of the frequency of frequencies, as denoted by Good [43]).
Our suggested estimation scheme is also in the natural domain. First, we choose a natural estimator (for example, Good–Turing). Then, given a set of samples , we identify sets of symbols with the same frequency values . Denote the number of unique frequencies as k. Define the mass of all the symbols with the same frequency r as for . We construct a leave-one-out (loo) model class by first excluding a single sample at a time and applying our chosen estimator, . Then, we set . In words, the loo estimator of the mass is attained by excluding a single sample, applying the chosen estimator, and accumulating the estimates of all the symbols of the original mass r. Finally, the estimate of a single symbol in a mass simply . Notice that the size of the model class is k (and not n).
For example, consider the set and a maximum likelihood estimator (which is simpler to illustrate then Good-Turing). We would like to find the loo class given . We seek loo estimates for symbols that appear twice, , for , and three times, , for . We first remove the first symbol , and get . This leads to and . Notice that we get the same estimates as we remove . Finally, by removing we attain , leading to and . Therefore, our corresponding loo model class consists of two estimates, and and its cardinality is .
References
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Lehmann, E.L.; Casella, G. Theory of Point Estimation; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Stein, C.M. Estimation of the mean of a multivariate normal distribution. Ann. Stat. 1981, 9, 1135–1151. [Google Scholar] [CrossRef]
- Ghosh, M. Uniform approximation of minimax point estimates. Ann. Math. Stat. 1964, 35, 1031–1047. [Google Scholar] [CrossRef]
- Donoho, D.L.; Liu, R.C.; MacGibbon, B. Minimax risk over hyperrectangles, and implications. Ann. Stat. 1990, 18, 1416–1437. [Google Scholar] [CrossRef]
- Bickel, P. Minimax estimation of the mean of a normal distribution when the parameter space is restricted. Ann. Stat. 1981, 9, 1301–1309. [Google Scholar] [CrossRef]
- Marchand, É.; Perron, F. On the minimax estimator of a bounded normal mean. Stat. Probab. Lett. 2002, 58, 327–333. [Google Scholar] [CrossRef]
- Lanckriet, G.R.; Ghaoui, L.E.; Bhattacharyya, C.; Jordan, M.I. A robust minimax approach to classification. J. Mach. Learn. Res. 2002, 3, 555–582. [Google Scholar]
- Eban, E.; Mezuman, E.; Globerson, A. Discrete chebyshev classifiers. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; PMLR: Beijing, China, 2014; pp. 1233–1241. [Google Scholar]
- Razaviyayn, M.; Farnia, F.; Tse, D. Discrete rényi classifiers. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; pp. 3276–3284. [Google Scholar]
- Farnia, F.; Tse, D. A minimax approach to supervised learning. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2016; pp. 4240–4248. [Google Scholar]
- Bennett, W.R. Spectra of Quantized Signals. Bell Syst. Tech. J. 1948, 27, 446–472. [Google Scholar] [CrossRef]
- Nisar, M.D. Minimax Robustness in Signal Processing for Communications; Shaker Verlag GmbH: Aachen, Germany, 2011. [Google Scholar]
- Kassam, S.A.; Poor, H.V. Robust techniques for signal processing: A survey. Proc. IEEE 1985, 73, 433–481. [Google Scholar] [CrossRef] [Green Version]
- Merhav, N.; Feder, M. Universal prediction. IEEE Trans. Inf. Theory 1998, 44, 2124–2147. [Google Scholar] [CrossRef] [Green Version]
- Verdu, S.; Poor, H. On minimax robustness: A general approach and applications. IEEE Trans. Inf. Theory 1984, 30, 328–340. [Google Scholar] [CrossRef] [Green Version]
- Takeuchi, J.I.; Barron, A.R. Robustly minimax codes for universal data compression. In Proceedings of the ISITA, Mexico City, Mexico, 14–16 October 1998. [Google Scholar]
- Rissanen, J. Strong optimality of the normalized ML models as universal codes and information in data. IEEE Trans. Inf. Theory 2001, 47, 1712–1717. [Google Scholar] [CrossRef] [Green Version]
- Grünwald, P. The safe bayesian. In International Conference on Algorithmic Learning Theory; Springer: Berlin/Heidelberg, Germany, 2012; pp. 169–183. [Google Scholar]
- Harremoës, P.; Tishby, N. The information bottleneck revisited or how to choose a good distortion measure. In Proceedings of the 2007 IEEE International Symposium on Information Theory, Nice, France, 24–29 June 2007; pp. 566–570. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Painsky, A.; Wornell, G. On the universality of the logistic loss function. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 936–940. [Google Scholar]
- Painsky, A.; Wornell, G.W. Bregman Divergence Bounds and Universality Properties of the Logarithmic Loss. IEEE Trans. Inf. Theory 2019, 66, 1658–1673. [Google Scholar] [CrossRef] [Green Version]
- Altman, D.; Machin, D.; Bryant, T.; Gardner, M. Statistics with Confidence: Confidence Intervals and Statistical Guidelines; John Wiley Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Gallager, R.G. Information Theory and Reliable Communication; Springer: Berlin/Heidelberg, Germany, 1968; Volume 588. [Google Scholar]
- Kemperman, J. On the Shannon capacity of an arbitrary channel. In Indagationes Mathematicae (Proceedings); Elsevier: North-Holland, The Netherlands, 1974; Volume 77, pp. 101–115. [Google Scholar]
- Haussler, D. A general minimax result for relative entropy. IEEE Trans. Inf. Theory 1997, 43, 1276–1280. [Google Scholar] [CrossRef]
- Feder, M.; Polyanskiy, Y. Sequential prediction under log-loss and misspecification. arXiv 2021, arXiv:2102.00050. [Google Scholar]
- Shtarkov, Y.M. Universal sequential coding of single messages. Probl. Inform. Transm. 1988, 23, 3–17. [Google Scholar]
- Raginsky, M. On the information capacity of Gaussian channels under small peak power constraints. In Proceedings of the 2008 46th Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 23–26 September 2008; pp. 286–293. [Google Scholar]
- Chan, T.H.; Hranilovic, S.; Kschischang, F.R. Capacity-achieving probability measure for conditionally Gaussian channels with bounded inputs. IEEE Trans. Inf. Theory 2005, 51, 2073–2088. [Google Scholar] [CrossRef]
- Dytso, A.; Al, M.; Poor, H.V.; Shitz, S.S. On the capacity of the peak power constrained vector Gaussian channel: An estimation theoretic perspective. IEEE Trans. Inf. Theory 2019, 65, 3907–3921. [Google Scholar] [CrossRef]
- Glaz, J.; Sison, C.P. Simultaneous confidence intervals for multinomial proportions. J. Stat. Plan. Inference 1999, 82, 251–262. [Google Scholar] [CrossRef]
- Goodman, L.A. Simultaneous confidence intervals for contrasts among multinomial populations. Ann. Math. Stat. 1964, 35, 716–725. [Google Scholar] [CrossRef]
- Quesenberry, C.P.; Hurst, D. Large sample simultaneous confidence intervals for multinomial proportions. Technometrics 1964, 6, 191–195. [Google Scholar] [CrossRef]
- Powers, D.M. Applications and explanations of Zipf’s law. In New Methods in Language Processing and Computational Natural Language Learning; ACL: New York, NY, USA, 1998. [Google Scholar]
- Okuyama, K.; Takayasu, M.; Takayasu, H. Zipf’s law in income distribution of companies. Phys. A Stat. Mech. Appl. 1999, 269, 125–131. [Google Scholar] [CrossRef]
- Saichev, A.I.; Malevergne, Y.; Sornette, D. Theory of Zipf’s Law and Beyond; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009; Volume 632. [Google Scholar]
- Krichevsky, R.; Trofimov, V. The performance of universal encoding. IEEE Trans. Inf. Theory 1981, 27, 199–207. [Google Scholar] [CrossRef]
- Witten, I.H.; Bell, T.C. The zero-frequency problem: Estimating the probabilities of novel events in adaptive text compression. IEEE Trans. Inf. Theory 1991, 37, 1085–1094. [Google Scholar] [CrossRef] [Green Version]
- Orlitsky, A.; Suresh, A.T. Competitive distribution estimation: Why is good-turning good. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2015; pp. 2143–2151. [Google Scholar]
- Laplace, P.S. Pierre-Simon Laplace Philosophical Essay on Probabilities: Translated from the Fifth French Edition of 1825 with Notes by the Translator; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1825; Volume 13. [Google Scholar]
- Good, I.J. The population frequencies of species and the estimation of population parameters. Biometrika 1953, 40, 237–264. [Google Scholar] [CrossRef]
- Paninski, L. Estimation of entropy and mutual information. Neural Comput. 2003, 15, 1191–1253. [Google Scholar] [CrossRef] [Green Version]
- Gale, W.A.; Sampson, G. Good-turing frequency estimation without tears. J. Quant. Linguist. 1995, 2, 217–237. [Google Scholar] [CrossRef]
- Mangasarian, O.L.; Street, W.N.; Wolberg, W.H. Breast cancer diagnosis and prognosis via linear programming. Oper. Res. 1995, 43, 570–577. [Google Scholar] [CrossRef] [Green Version]
- Sion, M. On general minimax theorems. Pac. J. Math. 1958, 8, 171–176. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Blahut, R. Computation of channel capacity and rate-distortion functions. IEEE Trans. Inf. Theory 1972, 18, 460–473. [Google Scholar] [CrossRef] [Green Version]
- Arimoto, S. An algorithm for computing the capacity of arbitrary discrete memoryless channels. IEEE Trans. Inf. Theory 1972, 18, 14–20. [Google Scholar] [CrossRef] [Green Version]
- Yeung, R.W. Information Theory and Network Coding; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
Figure 1.
The shape of our suggested solutions in the unknown normal mean problem. (Left)—the mixture distribution for . (Right)—all methods for and an example confidence interval of .
Figure 1.
The shape of our suggested solutions in the unknown normal mean problem. (Left)—the mixture distribution for . (Right)—all methods for and an example confidence interval of .

Figure 2.
Mean, variance, and worst-case performance in the Gaussian unknown mean problem. We draw n samples from and compute . We repeat this experiment 10,000 times and evaluate the mean (left), variance (middle), and worst-case (right) performance.
Figure 2.
Mean, variance, and worst-case performance in the Gaussian unknown mean problem. We draw n samples from and compute . We repeat this experiment 10,000 times and evaluate the mean (left), variance (middle), and worst-case (right) performance.

Figure 3.
Mean, variance, and worst-case performance in high-d Gaussian unknown mean problem. In each experiment we draw samples from and compute . We repeat this experiment 10,000 times and evaluate the mean (left), variance (middle), and worst-case (right) performance.
Figure 3.
Mean, variance, and worst-case performance in high-d Gaussian unknown mean problem. In each experiment we draw samples from and compute . We repeat this experiment 10,000 times and evaluate the mean (left), variance (middle), and worst-case (right) performance.

Figure 4.
Multinomial inference. In each experiment, we draw n samples from a Zipf’s law distribution with and . We evaluate for different estimators. We repeat this experiment 10,000 times and report the mean (left), variance (middle), and worst-case (right) performance.
Figure 4.
Multinomial inference. In each experiment, we draw n samples from a Zipf’s law distribution with and . We evaluate for different estimators. We repeat this experiment 10,000 times and report the mean (left), variance (middle), and worst-case (right) performance.

Figure 5.
Large alphabet probability estimation- the expected regret (difference) between and the performance of the natural oracle, .
Figure 5.
Large alphabet probability estimation- the expected regret (difference) between and the performance of the natural oracle, .

Figure 6.
Large alphabet probability estimation—the worst-case regret between and the performance of the natural oracle, .
Figure 6.
Large alphabet probability estimation—the worst-case regret between and the performance of the natural oracle, .

Figure 7.
Breast cancer tumor study. Mean, variance, and worst-case performance of different estimators, based on n samples.
Figure 7.
Breast cancer tumor study. Mean, variance, and worst-case performance of different estimators, based on n samples.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Painsky, A.; Feder, M. Robust Universal Inference. Entropy 2021, 23, 773. https://doi.org/10.3390/e23060773
AMA Style
Painsky A, Feder M. Robust Universal Inference. Entropy. 2021; 23(6):773. https://doi.org/10.3390/e23060773
Chicago/Turabian StylePainsky, Amichai, and Meir Feder. 2021. "Robust Universal Inference" Entropy 23, no. 6: 773. https://doi.org/10.3390/e23060773
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.