An Elementary Introduction to Information Geometry


Sony Computer Science Laboratories, Tokyo 141-0022, Japan
Entropy 2020, 22(10), 1100; https://doi.org/10.3390/e22101100
Submission received: 6 September 2020
/
Revised: 25 September 2020
/
Accepted: 27 September 2020
/
Published: 29 September 2020
(This article belongs to the Special Issue Review Papers for Entropy)
Abstract
:In this survey, we describe the fundamental differential-geometric structures of information manifolds, state the fundamental theorem of information geometry, and illustrate some use cases of these information manifolds in information sciences. The exposition is self-contained by concisely introducing the necessary concepts of differential geometry. Proofs are omitted for brevity.
Keywords:
differential geometry; metric tensor; affine connection; metric compatibility; conjugate connections; dual metric-compatible parallel transport; information manifold; statistical manifold; curvature and flatness; dually flat manifolds; Hessian manifolds; exponential family; mixture family; statistical divergence; parameter divergence; separable divergence; Fisher–Rao distance; statistical invariance; Bayesian hypothesis testing; mixture clustering; α-embeddings; mixed parameterization; gauge freedom
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
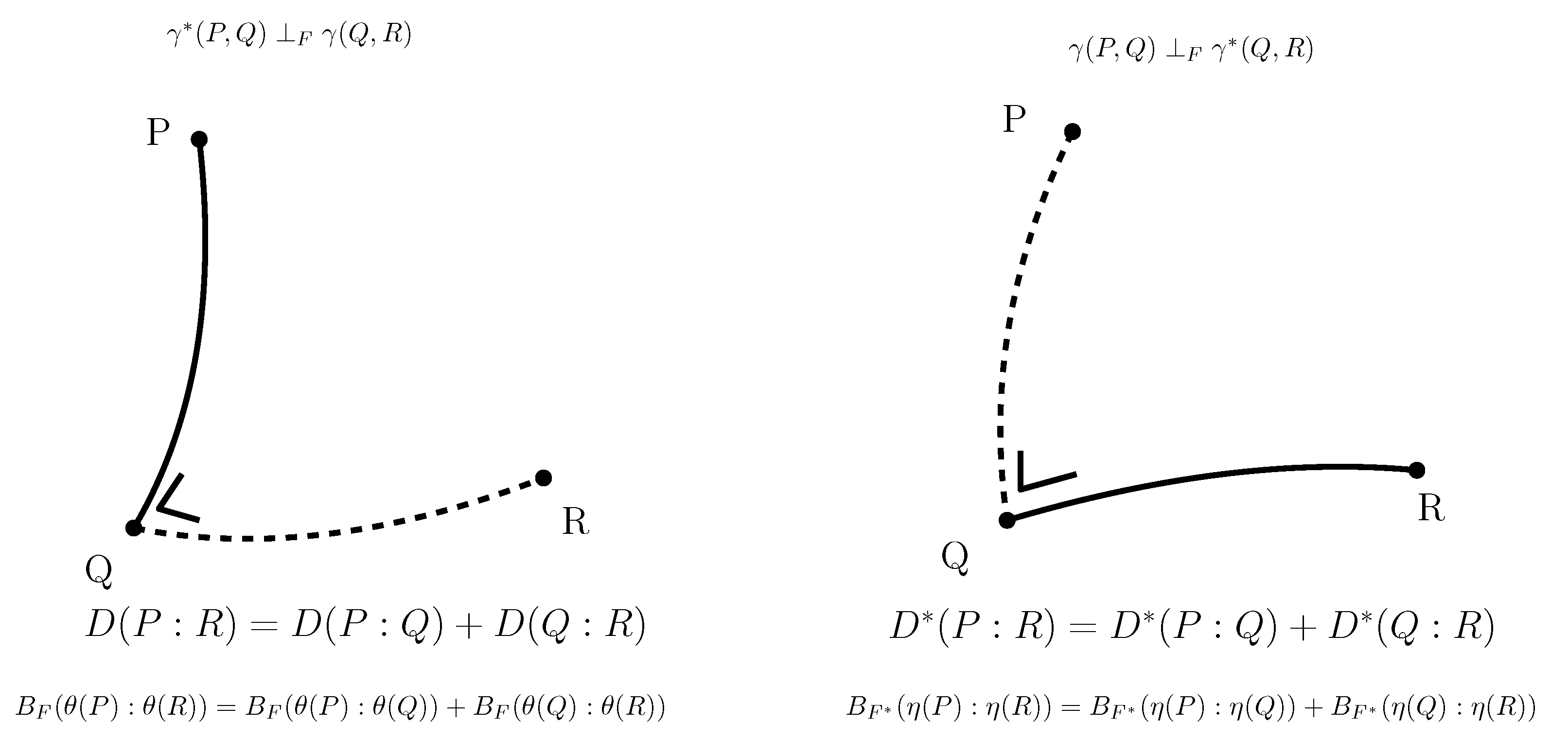{kind=link}
{kind=link}
{kind=link}
{kind=link}
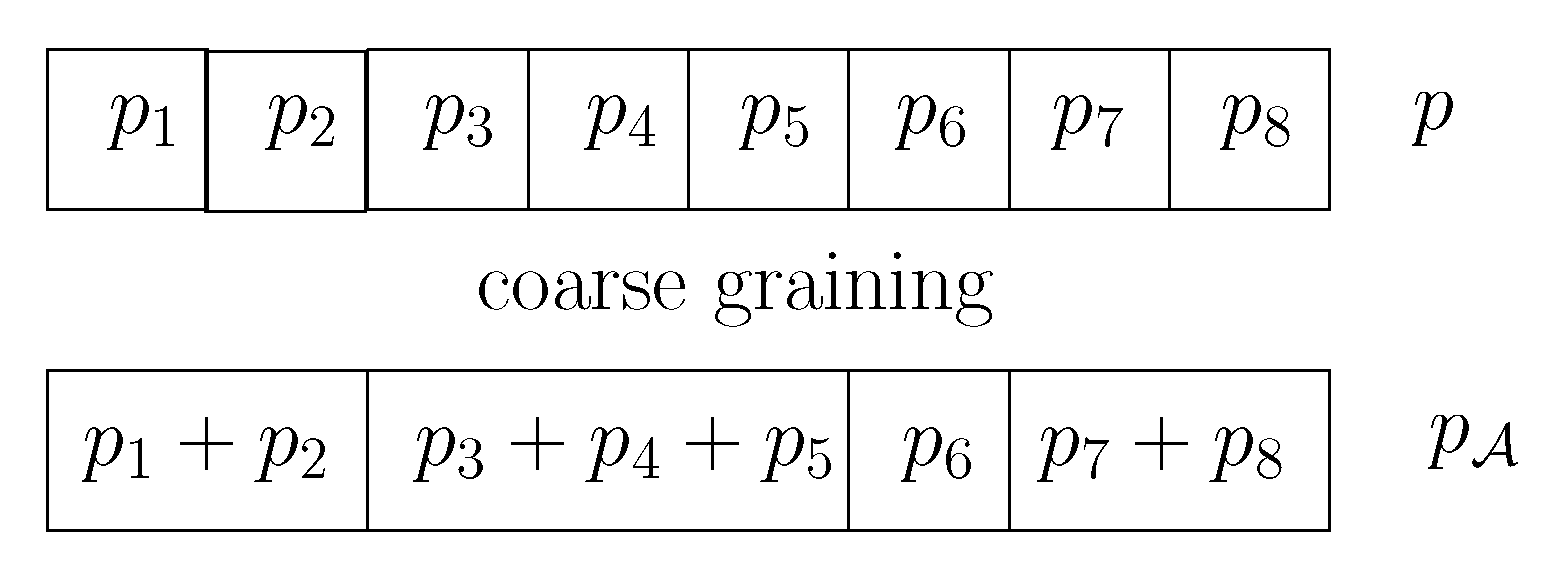{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
1.1. Overview of Information Geometry
We present a concise and modern view of the basic structures lying at the heart of Information Geometry (IG), and report some applications of those information-geometric manifolds (herein termed “information manifolds”) in statistics (Bayesian hypothesis testing) and machine learning (statistical mixture clustering).
By analogy to Information Theory (IT) (pioneered by Claude Shannon in his celebrated 1948 paper [1]) which considers primarily the communication of messages over noisy transmission channels, we may define Information Sciences (IS) as the fields that study “communication” between (noisy/imperfect) data and families of models (postulated as a priori knowledge). In short, information sciences seek methods to distill information from data to models. Thus information sciences encompass information theory but also include the fields of Probability and Statistics, Machine Learning (ML), Artificial Intelligence (AI), Mathematical Programming, just to name a few.
We review some key milestones of information geometry and report some definitions of the field by its pioneers in Section 5.2. Professor Shun-ichi Amari, the founder of modern information geometry, defined information geometry in the preface of his latest textbook [2] as follows: “Information geometry is a method of exploring the world of information by means of modern geometry.” In short, information geometry geometrically investigates information sciences. It is a mathematical endeavour to define and bound the term geometry itself as geometry is open-ended. Often, we start by studying the invariance of a problem (e.g., invariance of distance between probability distributions) and get as a result a novel geometric structure (e.g., a “statistical manifold”). However, a geometric structure is “pure” and thus may be applied to other application areas beyond the scope of the original problem (e.g., use of the dualistic structure of statistical manifolds in mathematical programming [3]): the method of geometry [4] thus yields a pattern of abduction [5,6].
A narrower definition of information geometry can be stated as the field that studies the geometry of decision making. This definition also includes model fitting (inference) which can be interpreted as a decision problem as illustrated in Figure 1; namely, deciding which model parameter to choose from a family of parametric models. This framework was advocated by Abraham Wald [7,8,9] who considered all statistical problems as statistical decision problems. Dissimilarities (also loosely called distances among others) play a crucial role not only for measuring the goodness-of-fit of data to model (say, likelihood in statistics, classifier loss functions in ML, objective functions in mathematical programming or operations research, etc.) but also for measuring the discrepancy (or deviance) between models.
One may ponder why adopting a geometric approach? Geometry allows one to study invariance of “figures” in a coordinate-free framework. The geometric language (e.g., line, ball or projection) also provides affordances that help us reason intuitively about problems. Note that although figures can be visualized (i.e., plotted in coordinate charts), they should be thought of as purely abstract objects, namely, geometric figures.
Geometry also allows one to study equivariance: For example, the centroid of a triangle is equivariant under any affine transformation A: . In Statistics, the Maximum Likelihood Estimator (MLE) is equivariant under a monotonic transformation g of the model parameter : , where the MLE of is denoted by .
1.2. Rationale and Outline of the Survey
The goal of this survey on information geometry [2] is to describe the core dualistic structures on manifolds without assuming any prior background on differential geometry [10], and explain several important related principles and concepts like invariance, covariance, projections, flatness and curvature, information monotonicity, etc. In doing so, we shall illustrate the basic underlying concepts with selected examples and applications, and shall make clear of some potential sources of confusion (e.g., a geometric statistical structure can be used in non-statistical applications [3], untangle the meaning of in the -connections, the -divergences, and the -representations, etc.). In particular, we shall name and state the fundamental theorem of information geometry in Section 3.5. We refer the reader to the books [2,4,11,12,13,14,15,16,17] for an indepth treatment of the field with its applications in information sciences.
This survey is organized as follows:
In the first part (Section 2), we start by concisely introducing the necessary background on differential geometry in order to define a manifold structure , i.e., a manifold M equipped with a metric tensor field g and an affine connection ∇. We explain how this framework generalizes the Riemannian manifolds by stating the fundamental theorem of Riemannian geometry that defines a unique torsion-free metric-compatible Levi–Civita connection which can be derived from the metric tensor.
In the second part (Section 3), we explain the dualistic structures of information manifolds: we present the conjugate connection manifolds , the statistical manifolds where C denotes a cubic tensor, and show how to derive a family of information manifolds for provided any given pair of conjugate connections. We explain how to get conjugate connections ∇ and coupled to the metric g from any smooth (potentially asymmetric) distances (called divergences), present the dually flat manifolds obtained when considering Bregman divergences, and define, when dealing with parametric family of probability models, the exponential connection and the mixture connection that are dual connections coupled to the Fisher information metric. We discuss the concept of statistical invariance for the metric tensor and the notion of information monotonicity for statistical divergences [2,18]. It follows that the Fisher information metric is the unique invariant metric (up to a scaling factor), and that the f-divergences are the unique separable invariant divergences.
In the third part (Section 4), we illustrate how to use these information-geometric structures in simple applications: First, we described the natural gradient descent method in Section 4.1 and its relationships with the Riemannian gradient descent and the Bregman mirror descent. Second, we consider two applications in dually flat spaces in Section 4.2: In the first application, we consider the problem of Bayesian hypothesis testing and show how Chernoff information (which defines the best error exponent) can be geometrically characterized on the dually flat structure of an exponential family manifold. In the second application, we show how to cluster statistical mixtures sharing the same component distributions on the dually flat mixture family manifold.
Finally, we conclude in Section 5 by summarizing the important concepts and structures of information geometry, and by providing further references and textbooks [2,16] for further readings to more advanced structures and applications of information geometry. We also mention recent studies of generic classes of principled distances and divergences.
In Appendix A, we show how to estimate the statistical f-divergences between two probability distributions in order to ensure that the estimates are non-negative in Appendix B, and report the canonical decomposition of the multivariate Gaussian family, an example of exponential family which admits a dually flat structure.
At the beginning of each part, we start by outlining its contents. A summary of the notations used throughout this survey is provided in Appendix C.
2. Prerequisite: Basics of Differential Geometry
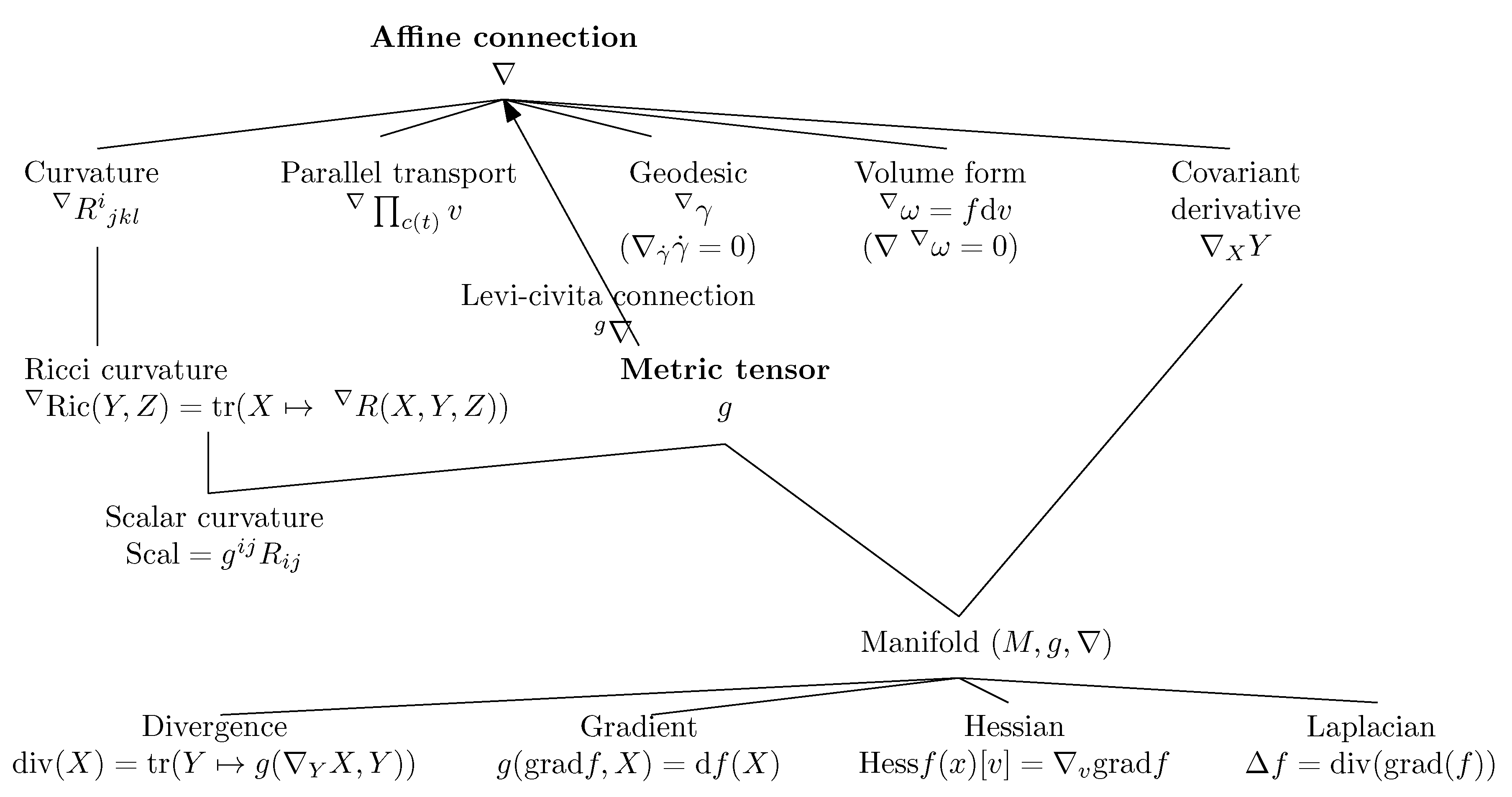
In Section 2.1, we review the very basics of Differential Geometry (DG) for defining a manifold equipped with both a metric tensor field g and an affine connection ∇. We explain these two independent metric/connection structures in Section 2.2 and Section 2.3, respectively. From an affine connection ∇, we show how to derive the notion of covariant derivative in Section 2.3.1, parallel transport in Section 2.3.2 and geodesics in Section 2.3.3. We further explain the intrinsic curvature and torsion of manifolds induced by the connection in Section 2.3.4, and state the fundamental theorem of Riemannian geometry in Section 2.4: the existence of a unique torsion-free Levi–Civita connection compatible with the metric (metric connection) that can be derived from the metric tensor g. Thus the Riemannian geometry is obtained as a special case of the more general manifold structure : . Information geometry shall further consider a dual structure associated to , and the pair of dual structures shall form an information manifold .
2.1. Overview of Differential Geometry: Manifold
Informally speaking, a smooth D-dimensional manifold M is a topological space that locally behaves like the D-dimensional Euclidean space . Geometric objects (e.g., points, balls, and vector fields) and entities (e.g., functions and differential operators) live on M, and are coordinate-free but can conveniently be expressed in any local coordinate system of an atlas of charts ’s (fully covering the manifold) for calculations. Historically, René Descartes (1596–1650) allegedly invented the global Cartesian coordinate system while wondering how to locate a fly on the ceiling from his bed. In practice, we shall use the most expedient coordinate system to facilitate calculations. In information geometry, we usually handle a single chart fully covering the manifold.
A manifold is obtained when the change of chart transformations are . The manifold is said smooth when it is . At each point , a tangent plane locally best linearizes the manifold. On any smooth manifold M, we can define two independent structures:
- A metric tensor g, and
- An affine connection ∇.
The metric tensor g induces on each tangent plane an inner product space that allows one to measure vector magnitudes (vector “lengths”) and angles/orthogonality between vectors. The affine connection ∇ is a differential operator that allows one to define:
- The covariant derivative operator which provides a way to calculate differentials of a vector field Y with respect to another vector field X: namely, the covariant derivative ,
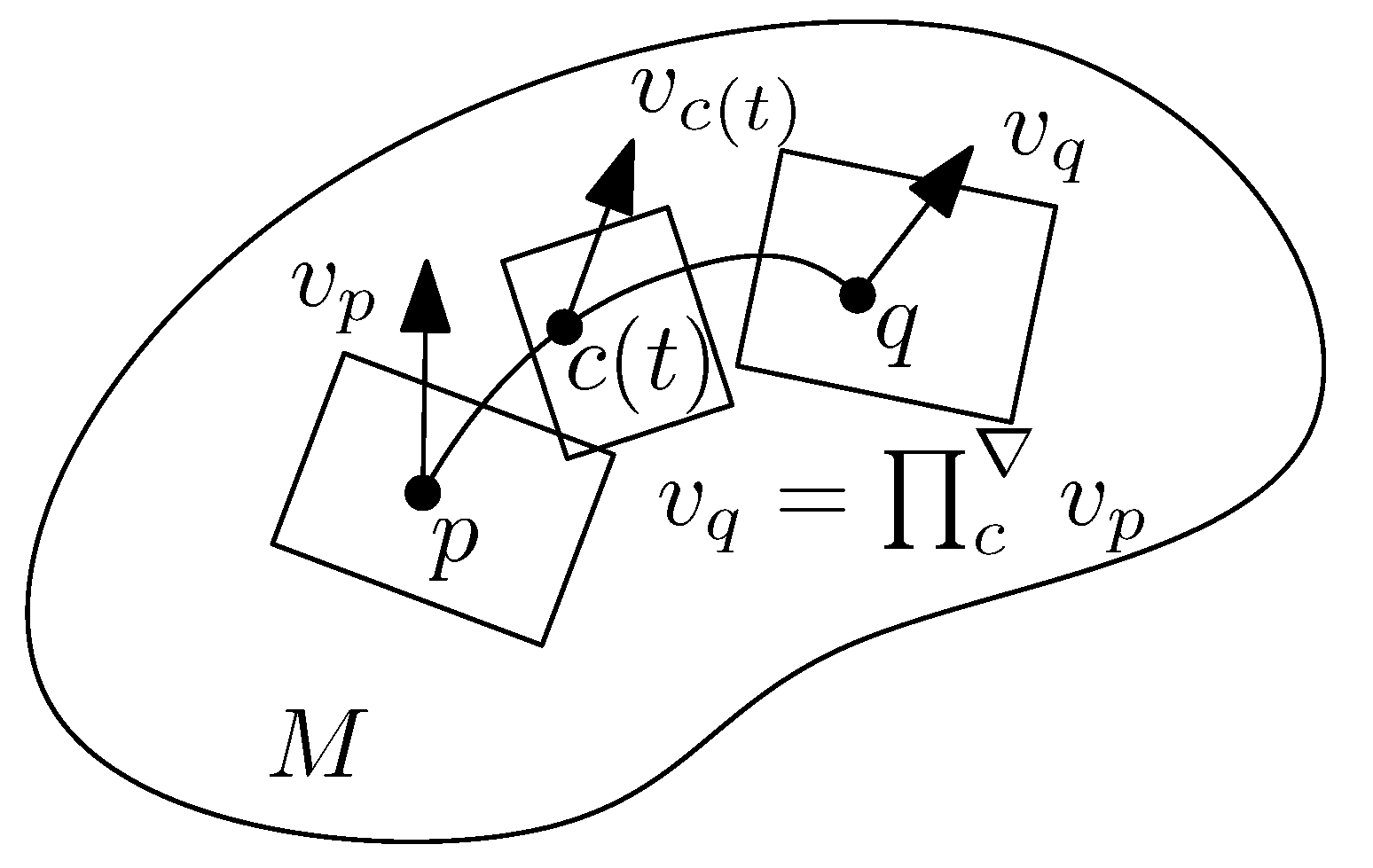
- The parallel transport which defines a way to transport vectors between tangent planes along any smooth curve c,
- The notion of ∇-geodesics which are defined as autoparallel curves, thus extending the ordinary notion of Euclidean straightness,
- The intrinsic curvature and torsion of the manifold.
2.2. Metric Tensor Fields g
The tangent bundle of M is defined as the “union” of all tangent spaces:
Thus the tangent bundle of a D-dimensional manifold M is of dimension (the tangent bundle is a particular example of a fiber bundle with base manifold M).
Informally speaking, a tangent vector v plays the role of a directional derivative, with informally meaning the derivative of a smooth function f (belonging to the space of smooth functions ) along the direction v. Since the manifolds are abstract and not embedded in some Euclidean space, we do not view a vector as an “arrow” anchored on the manifold. Rather, vectors can be understood in several ways in differential geometry like directional derivatives or equivalent class of smooth curves at a point. That is, tangent spaces shall be considered as the manifold abstract too.
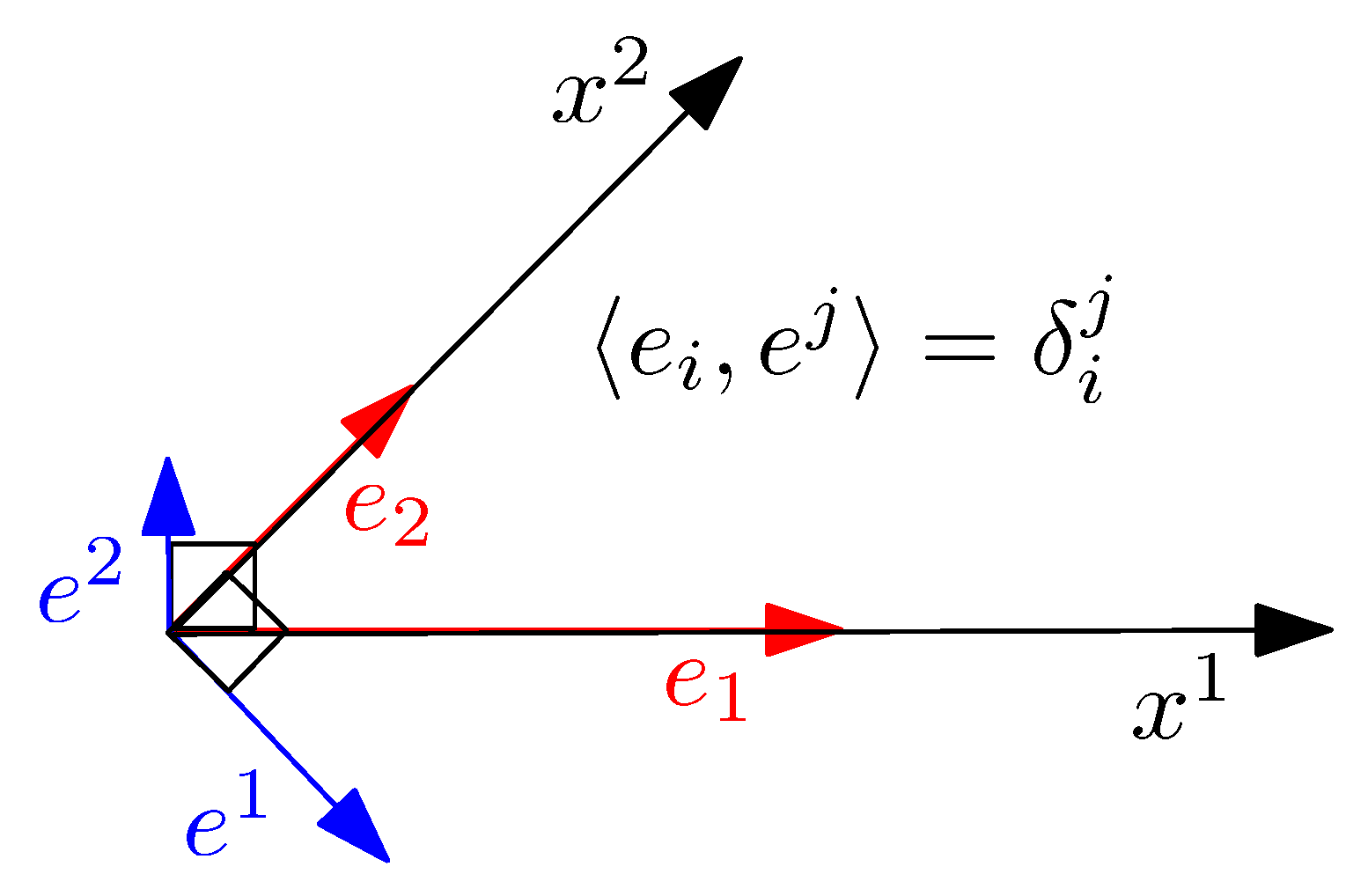
A smooth vector field X is defined as a “cross-section” of the tangent bundle: , where or denote the space of smooth vector fields. A basis of a finite D-dimensional vector space is a maximal linearly independent set of vectors: A set of vectors is linearly independent if and only if iff for all . That is, in a linearly independent vector set, no vector of the set can be represented as a linear combination of the remaining vectors. A vector set is linearly independent maximal when we cannot add another linearly independent vector. Tangent spaces carry algebraic structures of vector spaces. Furthermore, to any vector space V, we can associate a dual covector space which is the vector space of real-valued linear mappings. We do not enter into details here to preserve this gentle introduction to information geometry with as little intricacy as possible. Using local coordinates on a chart , the vector field X can be expressed as using Einstein summation convention on dummy indices (using notation ), where denotes the contravariant vector components (manipulated as “column vectors” in algebra) in the natural basis with . A tangent plane (vector space) equipped with an inner product yields an inner product space. We define a reciprocal basis of so that vectors can also be expressed using the covariant vector components in the natural reciprocal basis. The primal and reciprocal basis are mutually orthogonal by construction as illustrated in Figure 2.
For any vector v, its contravariant components ’s (superscript notation) and its covariant components ’s (subscript notation) can be retrieved from v using the inner product with the use of the reciprocal and primal basis, respectively:
The inner product defines a metric tensor g and a dual metric tensor :
Technically speaking, the metric tensor is a 2-covariant tensor field:
where ⊗ is the dyadic tensor product performed on pairwise covector basis (the covectors corresponding to the reciprocal vector basis). We do not describe tensors in details for sake of brevity. A tensor is a geometric entity of a tensor space that can also be interpreted as a multilinear map. A contravariant vector lives in a vector space while a covariant vector lives in the dual covector space. We recommend the textbook [19] for a concise and well-explained description of tensors.
Let and denote the matrices. It follows by construction of the reciprocal basis that . The reciprocal basis vectors ’s and primal basis vectors ’s can be expressed using the dual metric and metric g on the primal basis vectors ’s and reciprocal basis vectors ’s, respectively:
The metric tensor field g (“metric tensor” or “metric” for short) defines a smooth symmetric positive-definite bilinear form on the tangent bundle so that for . We can also write equivalently . Two vectors u and v are said orthogonal, denoted by , iff . The length of a vector is induced from the norm . Using local coordinates of a chart , we get the vector contravariant/covariant components, and compute the metric tensor using matrix algebra (with column vectors by convention) as follows:
since it follows from the primal/reciprocal basis that , the identity matrix. Thus on any tangent plane , we get a Mahalanobis distance:
The inner product of two vectors u and v is a scalar (a 0-tensor) that can be equivalently calculated as:
A metric tensor g of manifold M is said conformal when . That is, when the inner product is a scalar function of the Euclidean dot product. More precisely, we define the notion of a metric conformal to another metric g when these metrics define the same angles between vectors u and v of a tangent plane :
Usually is chosen as the Euclidean metric. In conformal geometry, we can measure angles between vectors in tangent planes as if we were in an Euclidean space, without any deformation. This is handy for checking orthogonality in charts. For example, the Poincaré disk model of hyperbolic geometry is conformal but Klein disk model is not conformal (except at the origin), see [20].
2.3. Affine Connections ∇
An affine connection ∇ is a differential operator defined on a manifold that allows us to define (1) a covariant derivative of vector fields, (2) a parallel transport of vectors on tangent planes along a smooth curve, and (3) geodesics. Furthermore, an affine connection fully characterizes the curvature and torsion of a manifold.
2.3.1. Covariant Derivatives of Vector Fields
A connection defines a covariant derivative operator that tells us how to differentiate a vector field Y according to another vector field X. The covariant derivative operator is denoted using the traditional gradient symbol ∇. Thus a covariate derivative ∇ is a function:
that has its own special subscript notation for indicating that it is differentiating a vector field Y according to another vector field X.
By prescribing smooth functions , called the Christoffel symbols of the second kind, we define the unique affine connection ∇ that satisfies in local coordinates of chart the following equations:
The Christoffel symbols can also be written as , where denotes the k-th coordinate. The k-th component of the covariant derivative of vector field Y with respect to vector field X is given by:
The Christoffel symbols are not tensors (fields) because the transformation rules induced by a change of basis do not obey the tensor contravariant/covariant rules.
2.3.2. Parallel Transport along a Smooth Curve c
Since the manifold is not embedded in a Euclidean space, we cannot add a vector to a vector as the tangent vector spaces are unrelated to each others without a connection (the Whitney embedding theorem [21] states that any D-dimensional Riemannian manifold can be embedded into ; when embedded, we can implicitly use the ambient Euclidean connection on the manifold, see [22]). Thus a connection ∇ defines how to associate vectors between infinitesimally close tangent planes and . Then the connection allows us to smoothly transport a vector by sliding it (with infinitesimal moves) along a smooth curve (with and ), so that the vector “corresponds” to a vector : this is called the parallel transport. This mathematical prescription is necessary in order to study dynamics on manifolds (e.g., study the motion of a particle on the manifold). We can express the parallel transport along the smooth curve c as:
The parallel transport is schematically illustrated in Figure 3.
2.3.3. ∇-Geodesics : Autoparallel Curves
A connection ∇ allows one to define ∇-geodesics as autoparallel curves, that are curves such that we have:
That is, the velocity vector is moving along the curve parallel to itself (and all tangent vectors on the geodesics are mutually parallel): In other words, ∇-geodesics generalize the notion of “straight Euclidean” lines. In local coordinates , , the autoparallelism amounts to solve the following second-order Ordinary Differential Equations (ODEs):
where are the Christoffel symbols of the second kind, with:
where the Christoffel symbols of the first kind. Geodesics are 1D autoparallel submanifolds and ∇-hyperplanes are defined similarly as autoparallel submanifolds of dimension . We may specify in subscript the connection that yields the geodesic : .
The geodesic equation may be either solved as an Initial Value Problem (IVP) or as a Boundary Value Problem (BVP):
- Initial Value Problem (IVP): fix the conditions and for some vector .
- Boundary Value Problem (BVP): fix the geodesic extremities and .
2.3.4. Curvature and Torsion of a Manifold
An affine connection ∇ defines a 4D curvature tensor R (expressed using components of a -tensor). The coordinate-free equation of the curvature tensor is given by:
where () is the Lie bracket of vector fields. When the connection is the metric Levi–Civita, the curvature is called Riemann–Christoffel curvature tensor. In a local coordinate system, we have:
Informally speaking, the curvature tensor as defined in Equation (20) quantifies the amount of non-commutativity of the covariant derivative. It follows from symmetry constraints that the number of independent components of the Riemann tensor is in D dimensions.
A manifold M equipped with a connection ∇ is said flat (meaning ∇-flat) when . This holds in particular when finding a particular coordinate system x of a chart such that , i.e., when all connection coefficients vanish. For example, the Christoffel symbols vanish in a rectangular coordinate system of a plane but not in the polar coordinate system of it.
A manifold is torsion-free when the connection is symmetric. A symmetric connection satisfies the following coordinate-free equation:
Using local chart coordinates, this amounts to check that . The torsion tensor is a -tensor defined by:
For a torsion-free connection, we have the first Bianchi identity:
and the second Bianchi identity:
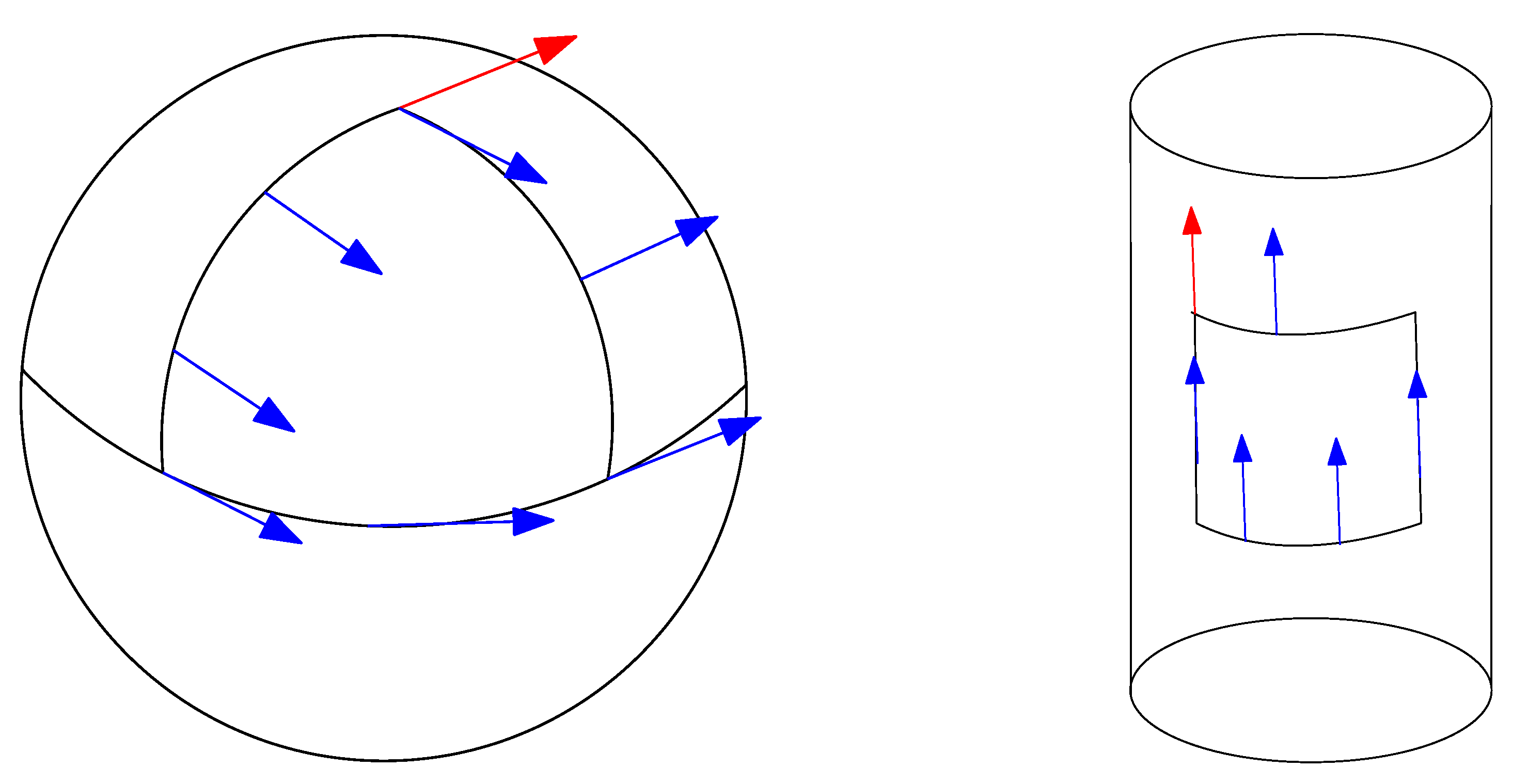
In general, the parallel transport is path-dependent. The angle defect of a vector transported on an infinitesimal closed loop (a smooth curve with coinciding extremities) is related to the curvature. However for a flat connection, the parallel transport does not depend on the path, and yields absolute parallelism geometry [25]. Figure 4 illustrates the parallel transport along a loop curve for a curved manifold (the sphere manifold) and a flat manifold (the cylinder manifold).
Historically, the Gaussian curvature at of point of a manifold has been defined as the product of the minimal and maximal sectional curvatures: . For a cylinder, since , it follows that the Gaussian curvature of a cylinder is 0. Gauss’s Theorema Egregium (meaning “remarkable theorem”) proved that the Gaussian curvature is intrinsic and does not depend on how the surface is embedded into the ambient Euclidean space.
An affine connection is a torsion-free linear connection. Figure 5 summarizes the various concepts of differential geometry induced by an affine connection ∇ and a metric tensor g.
Curvature is a fundamental concept inherent to geometry [26]: there are several notions of curvatures in differential geometry: scalar curvature, sectional curvature, Gaussian curvature of surfaces to Riemannian–Christoffel 4-tensor, Ricci symmetric 2-tensor, synthetic Ricci curvature in Alexandrov geometry, etc.
For example, the real-valued Gaussian curvature on a 2D Riemannian manifold with Riemann curvature -tensor R at a point p (with local basis on its tangent plane ) is defined by:
In general, the sectional curvatures are real values defined for 2-dimensional subspaces of the tangent plane (called tangent 2-planes) as:
where X and Y are linearly independent vectors of , and
denotes the squared area of the parallelogram spanned by vectors X and Y of . It can be shown that is independent of the chosen basis X and Y. In a local basis of D-dimensional tangent plane , we thus get the sectional curvatures at point as the following real values:
A Riemannian manifold is said of constant curvature if and only if for all and . In particular, the Riemannian manifold is said flat when it is of constant curvature 0. Notice that the definition of sectional curvatures relies on the metric tensor g but the Riemann–Christoffel curvature tensor is defined with respect to an affine connection (which can be taken as the default Levi–Civita metric connection induced by the metric g).
2.4. The Fundamental Theorem of Riemannian Geometry: The Levi–Civita Metric Connection
By definition, an affine connection ∇ is said metric compatible with g when it satisfies for any triple of vector fields the following equation:
which can be written equivalently as:
Using local coordinates and natural basis for vector fields, the metric-compatibility property amounts to check that we have:
A property of using a metric-compatible connection is that the parallel transport of vectors preserve the metric:
That is, the parallel transport preserves angles (and orthogonality) and lengths of vectors in tangent planes when transported along a smooth curve.
The fundamental theorem of Riemannian geometry states the existence of a unique torsion-free metric compatible connection:
Theorem 1
(Levi–Civita metric connection). There exists a unique torsion-free affine connection compatible with the metric called the Levi–Civita connection .
The Christoffel symbols of the Levi–Civita connection can be expressed from the metric tensor g as follows:
where denote the matrix elements of the inverse matrix .
The Levi–Civita connection can also be defined coordinate-free with the Koszul formula:
There exists metric-compatible connections with torsions studied in theoretical physics. See for example the flat Weitzenböck connection [27].
The metric tensor g induces the torsion-free metric-compatible Levi–Civita connection that determines the local structure of the manifold. However, the metric g does not fix the global topological structure: For example, although a cone and a cylinder have locally the same flat Euclidean metric, they exhibit different global structures.
2.5. Preview: Information Geometry versus Riemannian Geometry
In information geometry, we consider a pair of conjugate affine connections ∇ and (often but not necessarily torsion-free) that are coupled to the metric g: the structure is conventionally written as . The key property is that those conjugate connections are metric compatible, and therefore the induced dual parallel transport preserves the metric:
Thus the Riemannian manifold can be interpreted as the self-dual information-geometric manifold obtained for the unique torsion-free Levi–Civita metric connection: . However, let us point out that for a pair of self-dual Levi–Civita conjugate connections, the information-geometric manifold does not induce a distance. This contrasts with the Riemannian modeling which provides a Riemmanian metric distance defined by the length of the geodesic connecting the two points and :
This geodesic length distance can also be interpreted as the shortest path linking point p to point q: (with and ).
Usually, this Riemannian geodesic distance is not available in closed-form (and need to be approximated or bounded) because the geodesics cannot be explicitly parameterized (see geodesic shooting methods [28]).
We are now ready to introduce the key geometric structures of information geometry.
3. Information Manifolds
3.1. Overview
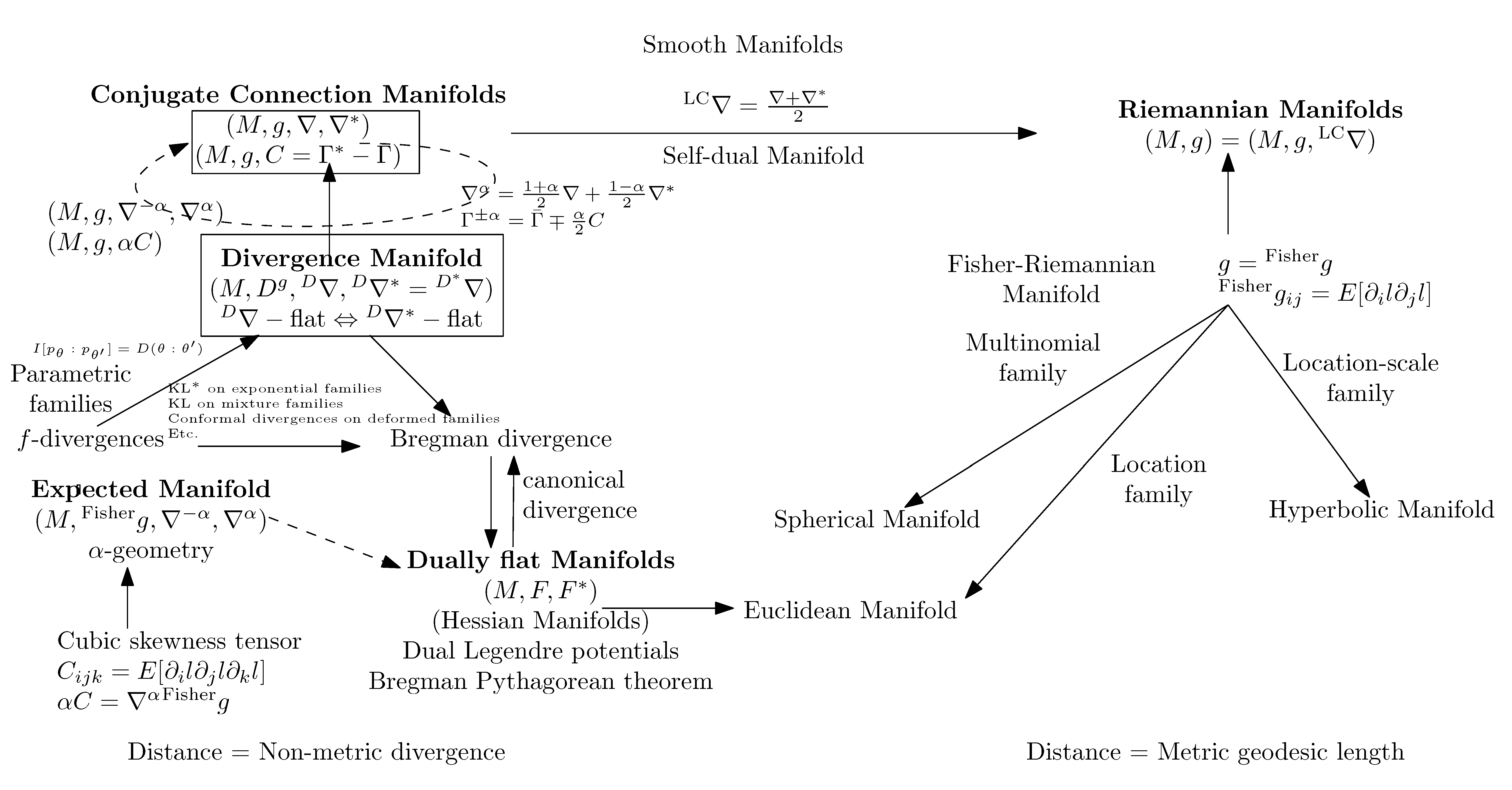
In this part, we explain the dualistic structures of manifolds in information geometry. In Section 3.2, we first present the core Conjugate Connection Manifolds (CCMs) , and show how to build Statistical Manifolds (SMs) from a CCM in Section 3.3. From any statistical manifold, we can build a 1-parameter family of CCMs, the information -manifolds. We state the fundamental theorem of information geometry in Section 3.5. These CCMs and SMs structures are not related to any distance a priori but require at first a pair of conjugate connections coupled to a metric tensor g. We show two methods to build an initial pair of conjugate connections. A first method consists of building a pair of conjugate connections () from any divergence D in Section 3.6. Thus we obtain self-conjugate connections when the divergence is symmetric: . When the divergences are Bregman divergences (i.e., for a strictly convex and differentiable Bregman generator), we obtain Dually Flat Manifolds (DFMs) in Section 3.7. DFMs nicely generalize the Euclidean geometry and exhibit Pythagorean theorems. We further characterize when orthogonal -projections and dual -projections of a point on submanifold a is unique. In Euclidean geometry, the orthogonal projection of a point p onto an affine subspace S is proved to be unique using the Pythagorean theorem. A second method to get a pair of conjugate connections consists of defining these connections from a regular parametric family of probability distributions . In that case, these ‘e’xponential connection and ‘m’ixture connection are coupled to the Fisher information metric . A statistical manifold can be recovered by considering the skewness Amari–Chentsov cubic tensor , and it follows a 1-parameter family of CCMs, , the statistical expected -manifolds. In this parametric statistical context, these information manifolds are called expected information manifolds because the various quantities are expressed from statistical expectations . Notice that these information manifolds can be used in information sciences in general, beyond the traditional fields of statistics. In statistics, we motivate the choice of the connections, metric tensors and divergences by studying statistical invariance criteria, in Section 3.10. We explain how to recover the expected -connections from standard f-divergences that are the only separable divergences that satisfy the property of information monotonicity. Finally, in Section 3.11, the recall the Fisher–Rao expected Riemannian manifolds that are Riemannian manifolds equipped with a geodesic metric distance called the Fisher–Rao distance, or Rao distance for short.
3.2. Conjugate Connection Manifolds:
We begin with a definition:
Definition 1
(Conjugate connections). A connection is said to be conjugate to a connection ∇ with respect to the metric tensor g if and only if we have for any triple of smooth vector fields the following identity satisfied:
We can notationally rewrite Equation (40) as:
and further explicit that for each point , we have:
We check that the right-hand-side is a scalar and that the left-hand-side is a directional derivative of a real-valued function, that is also a scalar.
Conjugation is an involution: .
Definition 2
(Conjugate Connection Manifold). The structure of the Conjugate Connection Manifold (CCM) is denoted by , where are conjugate connections with respect to the metric g.
A remarkable property is that the dual parallel transport of vectors preserves the metric. That is, for any smooth curve , the inner product is conserved when we transport one of the vector u using the primal parallel transport and the other vector v using the dual parallel transport .
Property 1
(Dual parallel transport preserves the metric). A pair of conjugate connections preserves the metric g if and only if:
Property 2.
Given a connection ∇ on (i.e., a structure ), there exists a unique conjugate connection (i.e., a dual structure ).
We consider a manifold M equipped with a pair of conjugate connections ∇ and that are coupled with the metric tensor g so that the dual parallel transport preserves the metric. We define the mean connection :
with corresponding Christoffel coefficients denoted by . This mean connection coincides with the Levi–Civita metric connection:
Property 3.
The mean connection is self-conjugate, and coincide with the Levi–Civita metric connection.
3.3. Statistical Manifolds:
Lauritzen introduced this corner structure [29] of information geometry in 1987. Beware that although it bears the name “statistical manifold”, it is a purely geometric construction that may be used outside of the field of Statistics. However, as we shall mention later, we can always find a statistical model corresponding to a statistical manifold [30]. We shall see how we can convert a conjugate connection manifold into such a statistical manifold, and how we can subsequently derive an infinite family of CCMs from a statistical manifold. In other words, once we have a pair of conjugate connections, we will be able to build a family of pairs of conjugate connections.
We define a cubic -tensor (i.e., 3-covariant tensor) called the Amari–Chentsov tensor:
or in coordinate-free equation:
The cubic tensor is totally symmetric, meaning that for any permutation . The metric tensor is totally symmetric.
Using the local basis, this cubic tensor can be expressed as:
Definition 3
(Statistical manifold [29]). A statistical manifold is a manifold M equipped with a metric tensor g and a totally symmetric cubic tensor C.
3.4. A Family of Conjugate Connection Manifolds
For any pair of conjugate connections, we can define a 1-parameter family of connections , called the -connections such that are dually coupled to the metric, with , and . By observing that the scaled cubic tensor is also a totally symmetric cubic 3-covariant tensor, we can derive the -connections from a statistical manifold as:
where are the Levi–Civita Christoffel symbols, and (by index juggling).
The -connection can also be defined as follows:
Theorem 2
(Family of information -manifolds). For any , is a conjugate connection manifold.
The -connections can also be constructed directly from a pair of conjugate connections by taking the following weighted combination:
3.5. The Fundamental Theorem of Information Geometry: ∇ -Curved ⇔ -Curved
We now state the fundamental theorem of information geometry and its corollaries:
Theorem 3
(Dually constant curvature manifolds). If a torsion-free affine connection ∇ has constant curvature κ then its conjugate torsion-free connection has necessarily the same constant curvature κ.
The proof is reported in [16] (Proposition 8.1.4, page 226).
A statistical manifold is said -flat if its induced -connection is flat. It can be shown that .
We get the following two corollaries:
Corollary 1
(Dually -flat manifolds). A manifold is -flat if and only if it is -flat.
Corollary 2
(Dually flat manifolds ()). A manifold is ∇-flat if and only if it is -flat.
Refer to Theorem 3.3 of [4] for a proof of this corollary.
Let us now define the notion of constant curvature of a statistical structure [31]:
Definition 4
(Constant curvature ). A statistical structure is said of constant curvature κ when
where denote the space of smooth vector fields.
It can be proved that the Riemann–Christoffel (RC) 4-tensors of conjugate -connections [16] are related as follows:
We have .
Thus once we are given a pair of conjugate connections, we can always build a 1-parametric family of manifolds. Manifolds with constant curvature are interesting from the computational viewpoint as dual geodesics have simple closed-form expressions.
3.6. Conjugate Connections from Divergences:
Loosely speaking, a divergence is a smooth distance [32], potentially asymmetric. In order to define precisely a divergence, let us first introduce the following handy notations: , , and , etc.
Definition 5(Divergence).
A divergence on a manifold M with respect to a local chart is a -function satisfying the following properties:
- for all with equality holding iff (law of the indiscernibles),
- for all ,
- is positive-definite.
The dual divergence is defined by swapping the arguments:
and is also called the reverse divergence (reference duality in information geometry). Reference duality of divergences is an involution: .
The Euclidean distance is a metric distance but not a divergence. The squared Euclidean distance is a non-metric symmetric divergence. The metric tensor g yields Riemannian metric distance but it is never a divergence.
From any given divergence D, we can define a conjugate connection manifold following the construction of Eguchi [33,34] (1983):
Theorem 4
(Manifold from divergence). is an information manifold with:
The associated statistical manifold is with:
Since is a totally symmetric cubic tensor for any , we can derive a one-parameter family of conjugate connection manifolds:
In the remainder, we use the shortcut to denote the divergence-induced information manifold . Notice that it follows from construction that:
3.7. Dually Flat Manifolds (Bregman Geometry):
We consider dually flat manifolds that satisfy asymmetric Pythagorean theorems. These flat manifolds can be obtained from a canonical Bregman divergence.
Consider a strictly convex smooth function called a potential function, with where is an open convex domain. Notice that the function convexity does not change by an affine transformation. We associate to the potential function F a corresponding Bregman divergence (parameter divergence):
We write also the Bregman divergence between point P and point Q as , where denotes the coordinates of a point P.
The information-geometric structure induced by a Bregman generator is with:
Here, we define a Bregman generator as a proper, lower semi-continuous, and strictly convex and differentiable real-valued function.
Since all coefficients of the Christoffel symbols vanish (Equation (64)), the information manifold is -flat. The Levi–Civita connection is obtained from the metric tensor (usually not flat), and we get the conjugate connection from .
The Legendre–Fenchel transformation yields the convex conjugate that is interpreted as the dual potential function:
A function f is lower semicontinous (lsc) at iff . A function f is lsc if it is lsc at x for all x in the function domain. The following theorem states that the conjugation of lower semicontinuous and convex functions is an involution:
Theorem 5
(Fenchel–Moreau biconjugation [35]). If F is a lower semicontinuous and convex function, then its Legendre–Fenchel transformation is involutive: (biconjugation).
In a dually flat manifold, there exists two global dual affine coordinate systems and , and therefore the manifold can be covered by a single chart. Thus if a probability family belongs to an exponential family then its natural parameters cannot belong to, say, a spherical space (that requires at least two charts).
We have the Crouzeix [36] identity relating the Hessians of the potential functions:
where I denote the identity matrix. This Crouzeix identity reveals that and are the primal and reciprocal basis, respectively.
The Bregman divergence can be reinterpreted using Young–Fenchel (in)equality as the canonical divergence [37]:
The dual Bregman divergence yields
Thus the information manifold is both -flat and -flat: This structure is called a dually flat manifold (DFM). In a DFM, we have two global affine coordinate systems and related by the Legendre–Fenchel transformation of a pair of potential functions F and . That is, , and the dual atlases are and .
In a dually flat manifold, any pair of points P and Q can either be linked using the ∇-geodesic (that is -straight) or the -geodesic (that is -straight). In general, there are types of geodesic triangles in a dually flat manifold.
On a Bregman manifold, the primal parallel transport of a vector does not change the contravariant vector components, and the dual parallel transport does not change the covariant vector components. Because the dual connections are flat, the dual parallel transports are path-independent.
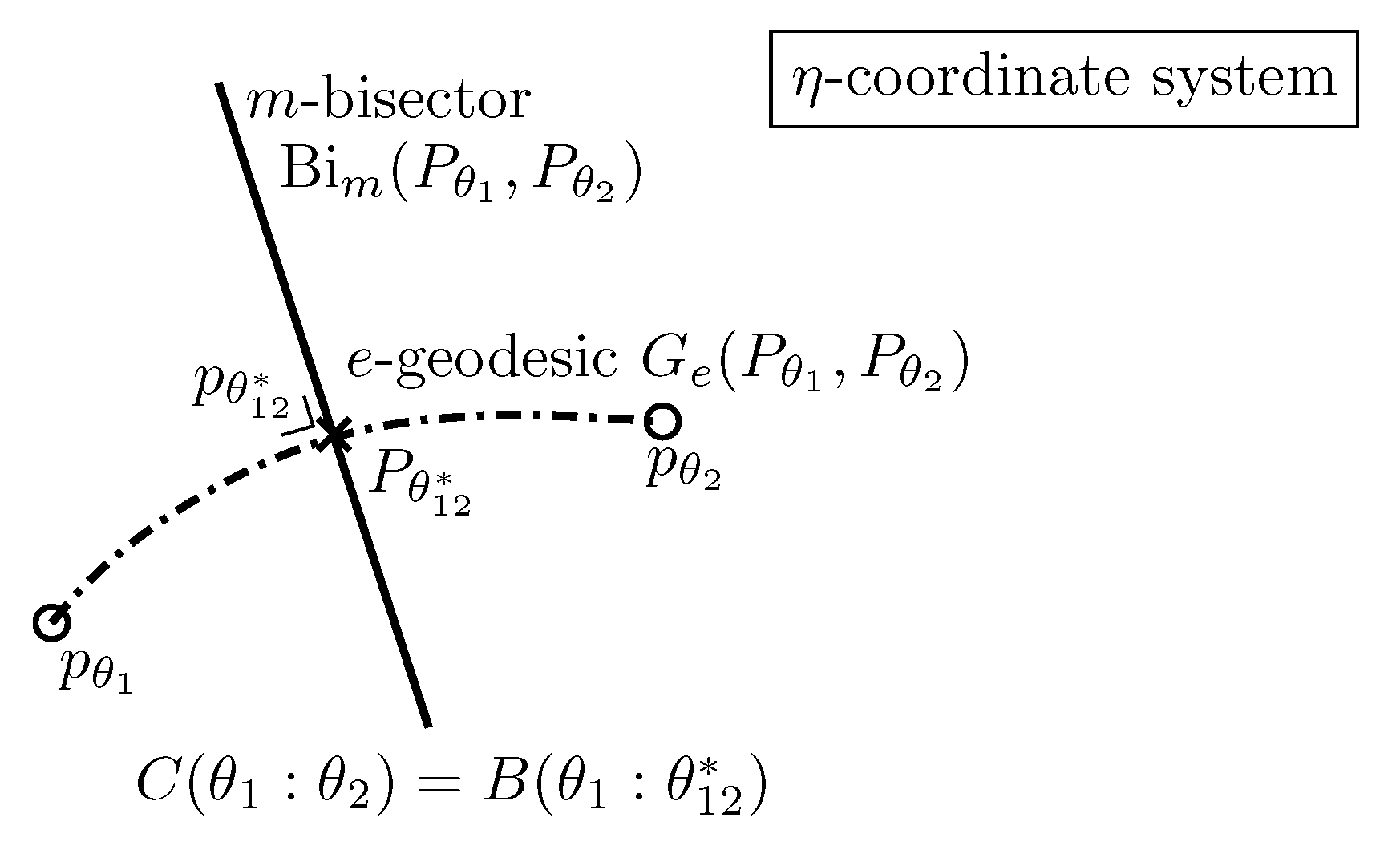
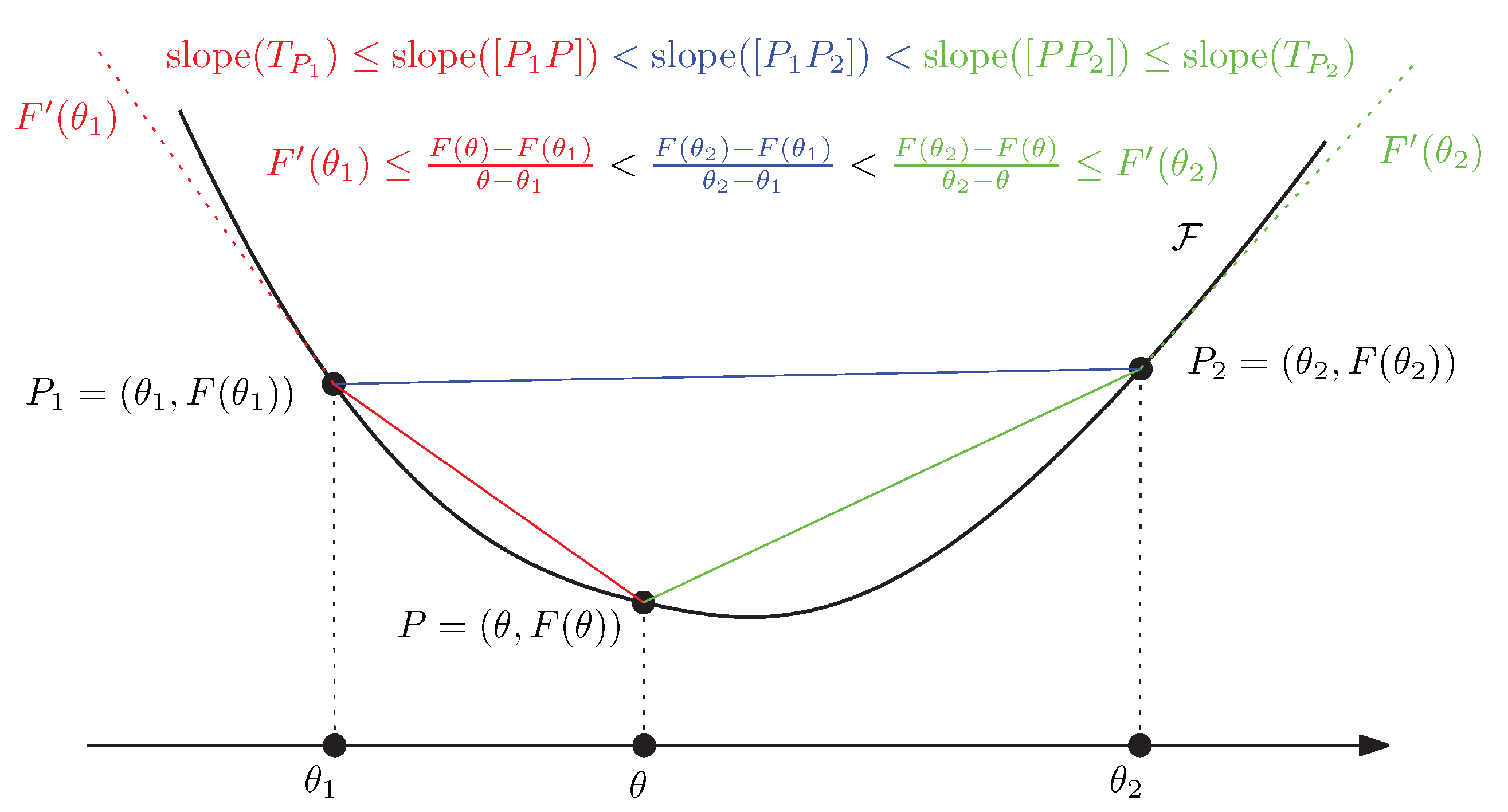
Moreover, the dual Pythagorean theorems [38] illustrated in Figure 6 holds. Let denote the ∇-geodesic passing through points P and Q, and denote the -geodesic passing through points P and Q. Two curves and are orthogonal at point with respect to the metric tensor g when .
Theorem 6
(Dual Pythagorean identities).
We can define dual Bregman projections and characterize when these projections are unique: A submanifold is said ∇-flat (-flat) iff. it corresponds to an affine subspace in the -coordinate system (in the -coordinate system, respectively).
Theorem 7
(Uniqueness of projections). The ∇-projection of P on S is unique if S is -flat and minimizes the divergence :
The dual -projection is unique if is ∇-flat and minimizes the divergence :
Let and , then we define the divergence between S and as
When S is a ∇-flat submanifold and -flat submanifold, the divergence between submanifold S and submanifold can be calculated using the method of alternating projections [2]. Let us remark that Kurose [39] reported a Pythagorean theorem for dually constant curvature manifolds that generalizes the Pythagorean theorems of dually flat spaces.
We shall concisely explain the space of Bregman spheres explained in details in [40]. Let D denote the dimension of . We define the lifting of primal coordinates to the primal potential function using an extra dimension . A Bregman ball
can then be lifted to : . The boundary Bregman sphere is lifted to , and the lifted points are all supported by a supporting -dimensional hyperplane (of dimension D):
Let denotes the halfspaces bounded by and containing . A point P belongs to a Bregman ball iff , see [40]. Reciprocally, a -dimensional hyperplane cutting the potential function yields a Bregman sphere of center C with and radius , where . It follows that the intersection of k Bregman balls is a -dimensional Bregman ball, and that a Bregman sphere can be defined by points in general position since an hyperplane in the augmented space is defined by points. We can test whether a point P belongs to a Bregman ball with bounding Bregman sphere passing through points or not by checking the sign of a determinant:
We have:
Similarly, a dual-type Bregman ball can be defined by
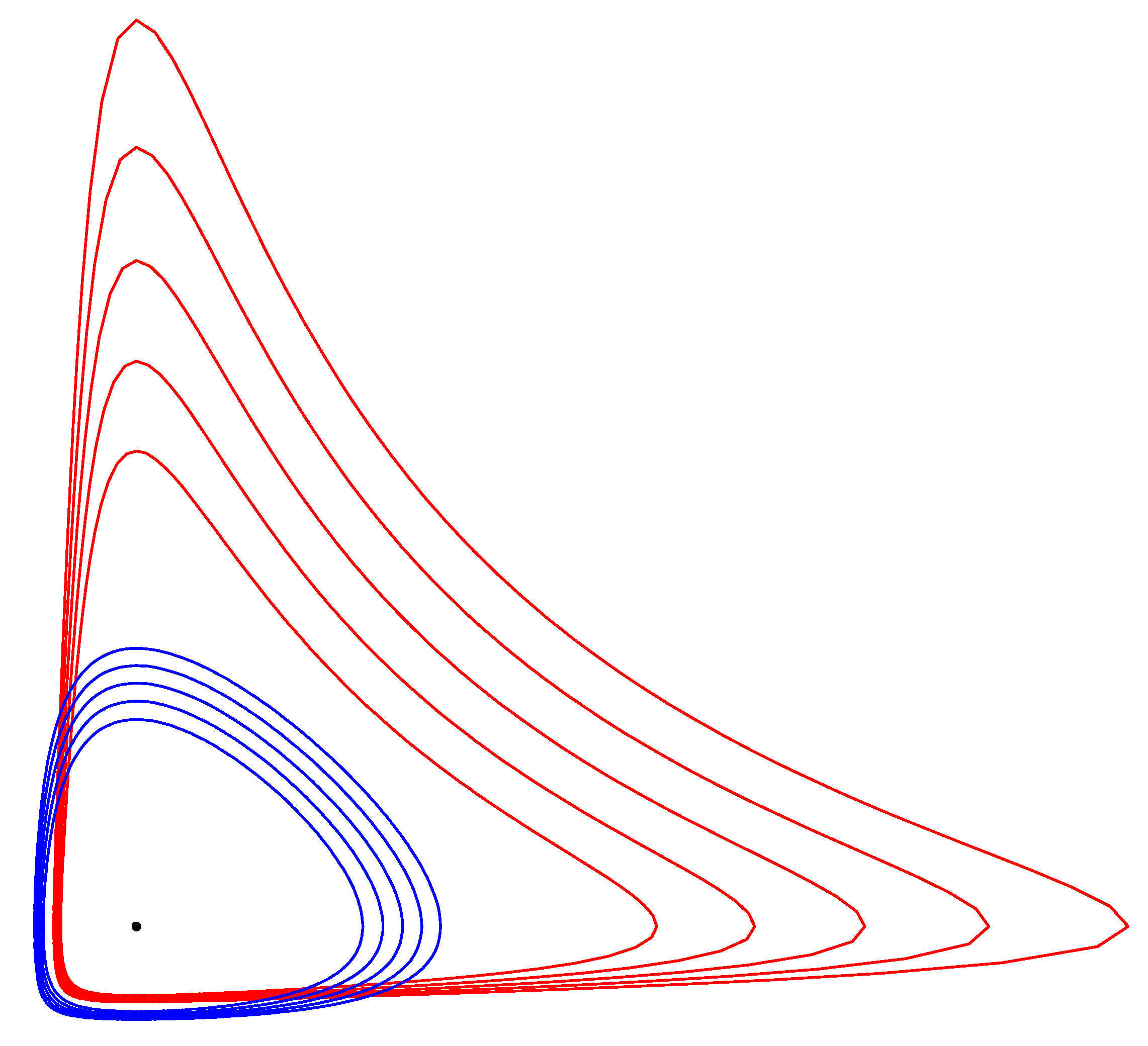
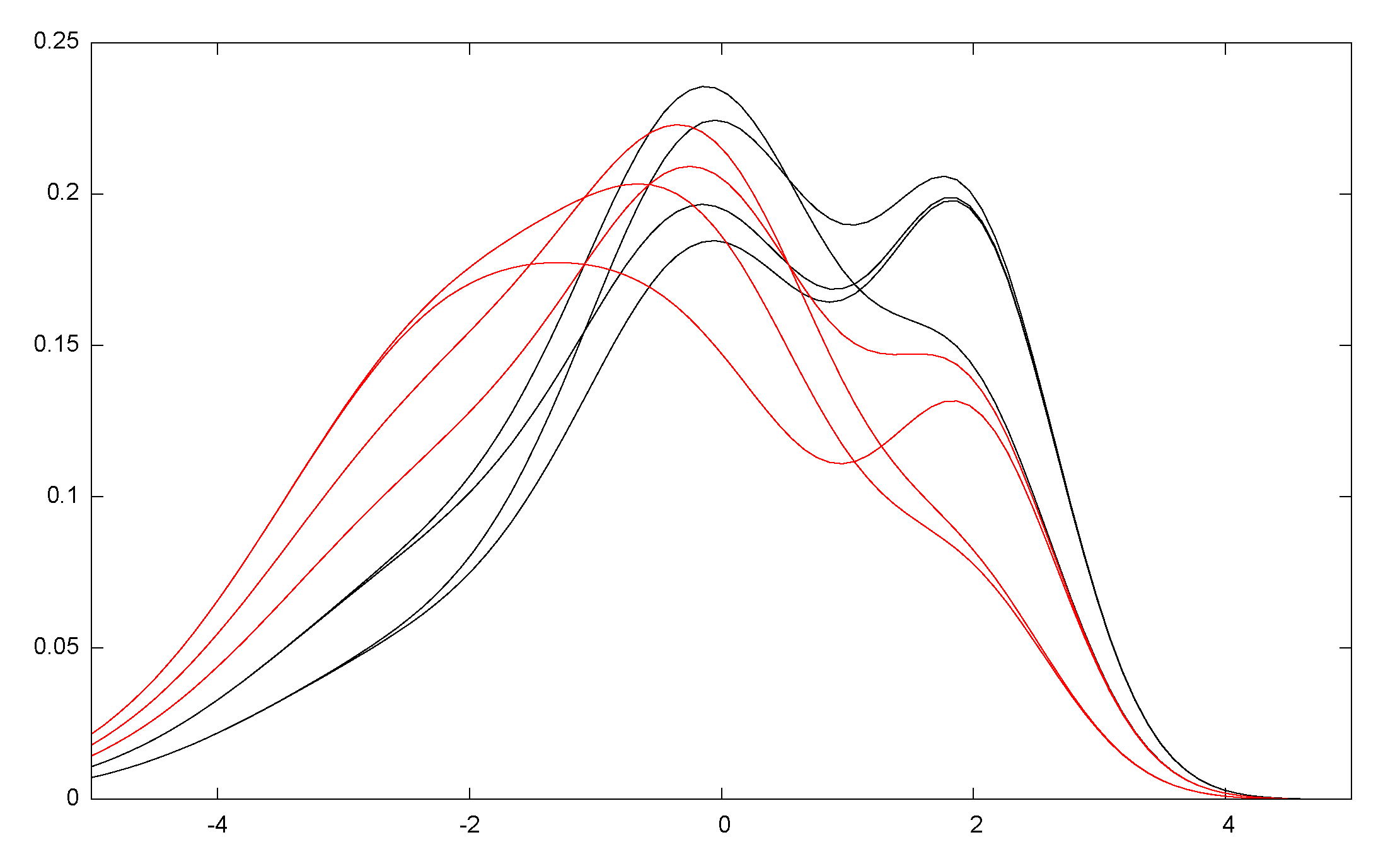
and be lifted to the dual potential function . Notice that . Figure 7 displays five concentric pairs of dual Itakura–Saito circles obtained for the separable Burg negentropy generator (with corresponding Bregman divergence the Itakura–Saito divergence).
Using the space of spheres, it is easy to design algorithms for calculating the union or intersection of Bregman spheres [40], or data-structures for proximity queries [41] (relying on the radical axis of two Bregman spheres). The Bregman spheres are considered for building Bregman Voronoi diagrams in [40,42].
The smallest enclosing Bregman ball [43,44] (SEBB) of a set of points (with respective -coordinates ) can also be modeled as a convex program; indeed, point belongs to the lower halfspace of equation (parameterized by vector and scalar ) iff . Thus we seek to minimize such that for all . This is a convex program since is the convex conjugate of a convex generator F. When (i.e., Euclidean geometry), we recover the fact that the smallest enclosing ball of a point set in Euclidean geometry can be solved using quadratic programming [45]. Faster approximation algorithms for the smallest enclosing Bregman ball can be built based on core-sets [43].
In general, we have the following quadrilateral relation for Bregman divergences:
Property 4
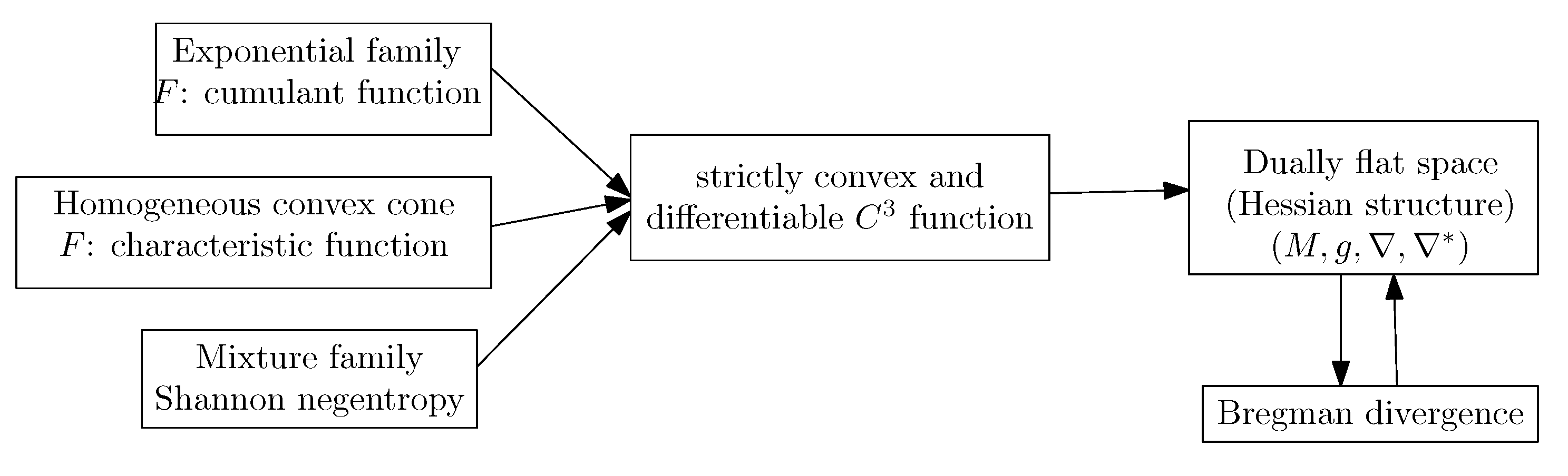
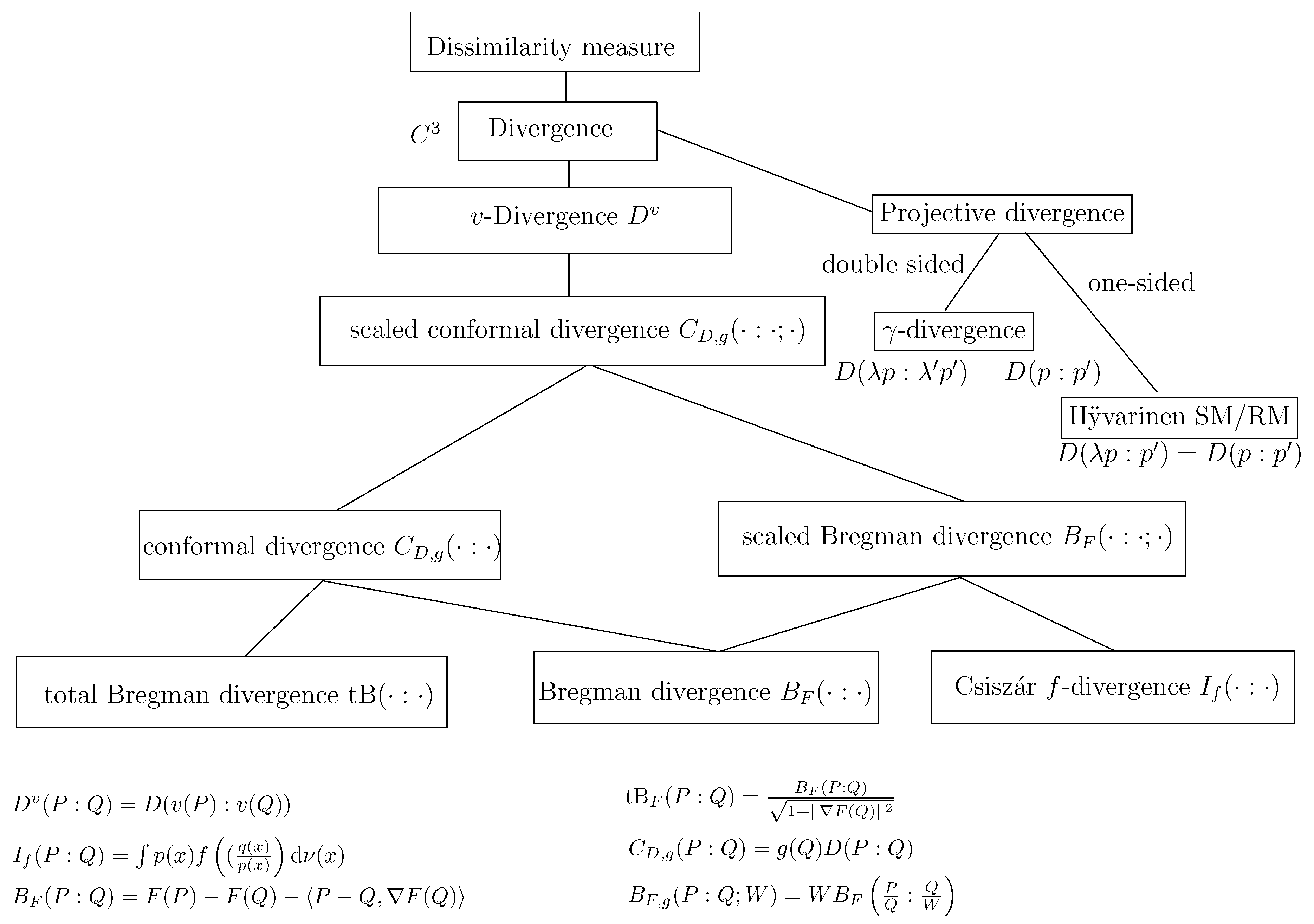
In summary, to define a dually flat space, we need a convex Bregman generator. When the -geometries are neither dually flat (e.g., Cauchy manifolds [47], we may still build a dually flat structure on the manifold by considering some Bregman generator (e.g., Bregman- -Tsallis generator for the dually flat Cauchy manifold [47]). The dually flat geometry can be investigated under the wider scope of Hessian manifolds [48] which consider locally potential functions. In general, a dually flat space can be built from any smooth strictly convex generator F. For example, a dually flat geometry can be built on homogeneous cones with the characteristic function F of the cone [48]. Figure 8 illustrates several common constructions of dually flat spaces.
3.8. Hessian -Geometry: )
The dually flat manifold is also called a manifold with a Hessian structure [48] induced by a convex potential function F. Since we built two dual affine connections and , we can build a family of -geometry as follows:
and
Thus when , the Hessian -geometry is dually flat since and .
We now consider information manifolds induced by parametric statistical models.
3.9. Expected -Manifolds of a Family of Parametric Probability Distributions:
Informally speaking, an expected manifold is an information manifold built on a regular parametric family of distributions. It is sometimes called “expected” manifold or “expected” geometry in the literature [49] because the components of the metric tensor g and the Amari–Chentsov cubic tensor C are expressed using statistical expectations.
Let be a parametric family of probability distributions:
with belonging to the open parameter space . The order of the family is the dimension of its parameter space. We define the likelihood function as a function of , and its corresponding log-likelihood function:
More precisely, the likelihood function is an equivalence class of functions defined modulo a positive scaling factor.
The score vector:
indicates the sensitivity of the likelihood .
The Fisher information matrix (FIM) of for is defined by:
where ⪰ denotes the Löwner order. That is, for two symmetric positive-definite matrices A and B, if and only if matrix is positive semidefinite. For regular models [16], the FIM is positive definite: , where if and only if matrix is positive-definite.
The FIM is invariant by reparameterization of the sample space , and covariant by reparameterization of the parameter space , see [16]. That is, let . Then we have:
Matrix is the Jacobian matrix.
Let us give illustrate the covariance of the Fisher information matrix with the following example:
Example 1.
Consider the family
of univariate normal distributions. The 2D parameter vector is with μ denoting the mean and σ the standard deviation. Another common parameterization of the normal family is . The parameterization extends naturally to d-variance normal distributions with , where Σ denotes the covariance matrix (with when ). For multivariate normal distributions, the λ-parameterization can be interpreted as where is the upper triangular matrix in the Cholesky decomposition (when , ). We have the following Fisher information matrices in the λ-parameterization and -parameterization:
and
Since the FIM is covariant, we have the following the change of transformation:
with
Thus we check that
Notice that the infinitesimal length elements are invariant: .
As a corollary, notice that we can recognize the Euclidean metric in any other coordinate system if the metric tensor g can be written . For example, the Riemannian geometry induced by a dually flat space with a separable potential function is Euclidean [50].
In statistics, the FIM plays a role in the attainable precision of unbiased estimators. For any unbiased estimator, the Cramér–Rao lower bound [51] on the variance of the estimator is:
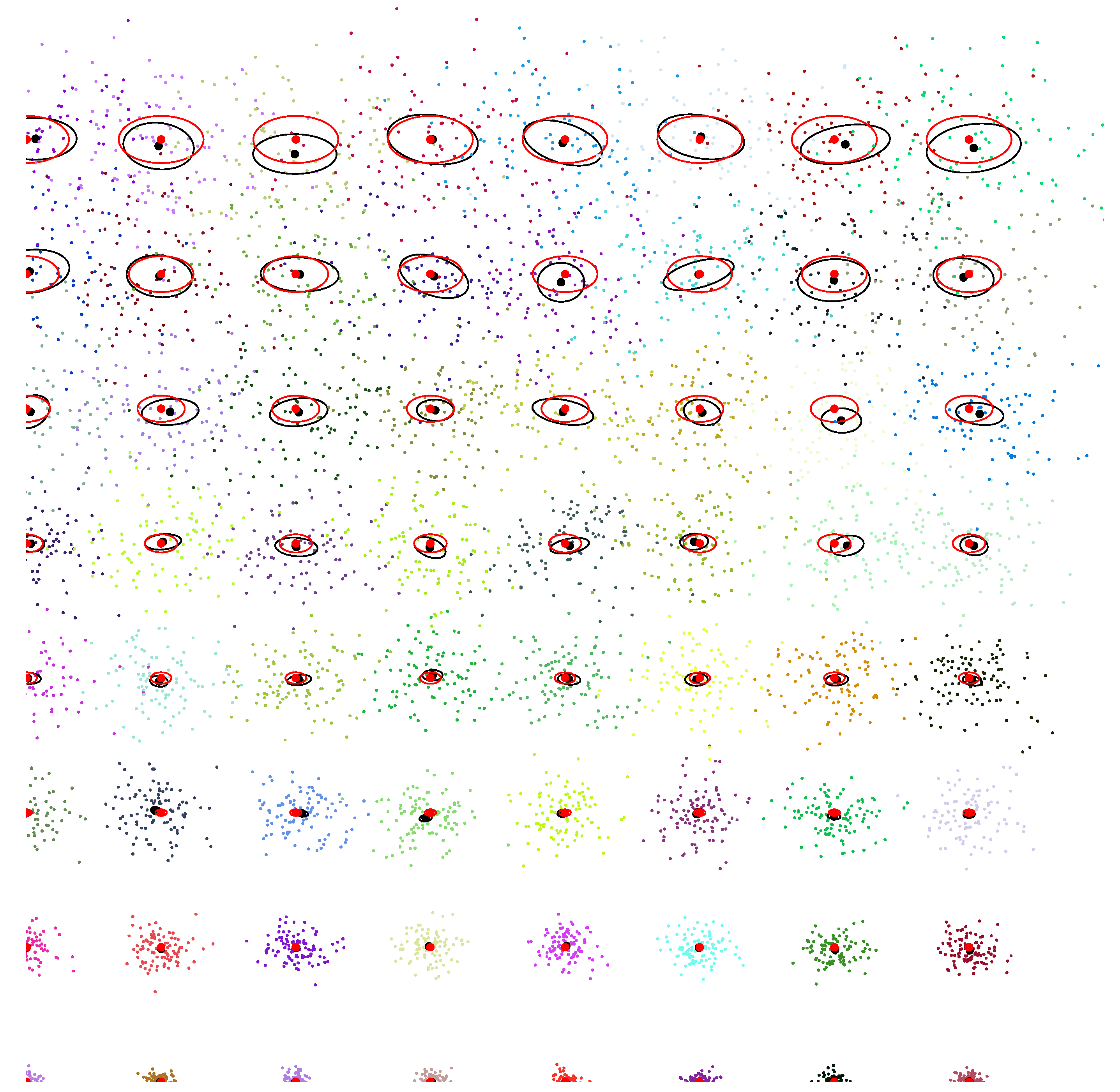
Figure 9 illustrates the Cramér–Rao lower bound (CRLB) for the univariate distributions: At regular grid locations of the upper space of normal parameters, we repeat 200 runs (trials) of estimating the normal parameters using the MLE on 100 iid samples . The sample mean and the sample covariance matrix are calculated for the number of trials and displayed as back ellipses. The Fisher information matrix is plotted as red ellipses at the grid locations: the red ellipses have semi-axes parallel to the coordinate system since the parameters and are orthogonal (diagonal FIM). This is not true anymore for the sample covariance matrix of the MLE estimator, and the centers of the sample covariance matrices deviate from the grid locations.
We report the expression of the FIM for two important generic parametric family of probability distributions: (1) an exponential family (with its prominent multivariate normal family), and (2) a mixture family.
Example 2
(FIM of an exponential family ). An exponential family [52] is defined for a sufficient statistic vector , and an auxiliary carrier measure by the following canonical density:
where F is the strictly convex cumulant function (also called log-normalizer, and log partition function or free energy in statistical mechanics). Exponential families include the Gaussian family, the Gamma and Beta families, the probability simplex Δ, etc. The FIM of an exponential family is given by:
Indeed, under mild conditions [2], we have . Since , it follows that . Natural parameters beyond vector types can also be used in the canonical decomposition of the density of an exponential family. For example, we may use a matrix type for defining the zero-centered multivariate Gaussian family or the Wishart family, a complex numbers for defining the complex-valued Gaussian distribution family, etc. We then replace the term in Equation (94) by an inner product defined for the natural parameter type (e.g., dot product for vectors, matrix product trace for matrices, etc.). Furthermore, natural parameters can be of compound types: For example, the multivariate Gaussian distribution can be written using where is a vector part and a matrix part, see [52].
Let denote the covariance matrix and the precision matrix of a multivariate normal distribution. The Fisher information matrix of the multivariate Gaussian [53,54] is given by
Notice that the lower right block matrix is a 4D tensor of dimension . The zero subblock matrices in the FIM indicate that the parameters μ and Σ are orthogonal to each other. In particular, when , since , we recover the Fisher information matrix of the univariate Gaussian:
We refer to [55] for the FIM of a Gaussian distribution using other canonical parameterizations (natural/expectation parameters of exponential family).
Example 3
(FIM of a mixture family ). A mixture family is defined for functions and C as:
where the functions are linearly independent on the common support and satisfying . Function C is such that . Mixture families include statistical mixtures with prescribed component distributions and the probability simplex Δ. The FIM of a mixture family is given by:
The family of Gaussian mixture model (GMM) with prescribed component distributions (i.e., convex weight combinations of Gaussian densities) form a mixture family [56].
Notice that the probability simplex of discrete distributions can be both modeled as an exponential family or a mixture family [2].
The expected -geometry is built from the expected dual -connections. The Fisher “information metric” tensor is built from the FIM as follows:
The expected exponential connection and expected mixture connection are given by
The dualistic structure is denoted by with Amari–Chentsov cubic tensor called the skewness tensor:
It follows that we can build a one-family of expected information -manifolds:
with
The Levi–Civita metric connection is recovered as follows:
The -Riemann–Christoffel curvature tensor is:
with . We check that the expected -connections are coupled with the metric: .
In case of an exponential family or a mixture family equipped with the dual exponential/mixture connection, we get dually flat manifolds (Bregman geometry).
Indeed, for the exponential/mixture families, it is easy to check that the Christoffel symbols of and vanish:
3.10. Criteria for Statistical Invariance
So far we have explained how to build an information manifold (or information -manifold) from a pair of conjugate connections. Then we reported two ways to obtain such a pair of conjugate connections: (1) from a parametric divergence, or (2) by using the predefined expected exponential/mixture connections. We now ask the following question: which information manifold makes sense in Statistics? We can refine the question as follows:
- Which metric tensors g make sense in statistics?
- Which affine connections ∇ make sense in statistics?
- Which statistical divergences make sense in statistics (from which we can get the metric tensor and dual connections)?
By definition, an invariant metric tensor g shall preserve the inner product under important statistical mappings called Markov embeddings. Informally, we embed into with and the induced metric should be preserved (see [2], page 62).
Theorem 8
A D-dimensional parameter (discrete) divergence satisfies the information monotonicity if and only if:
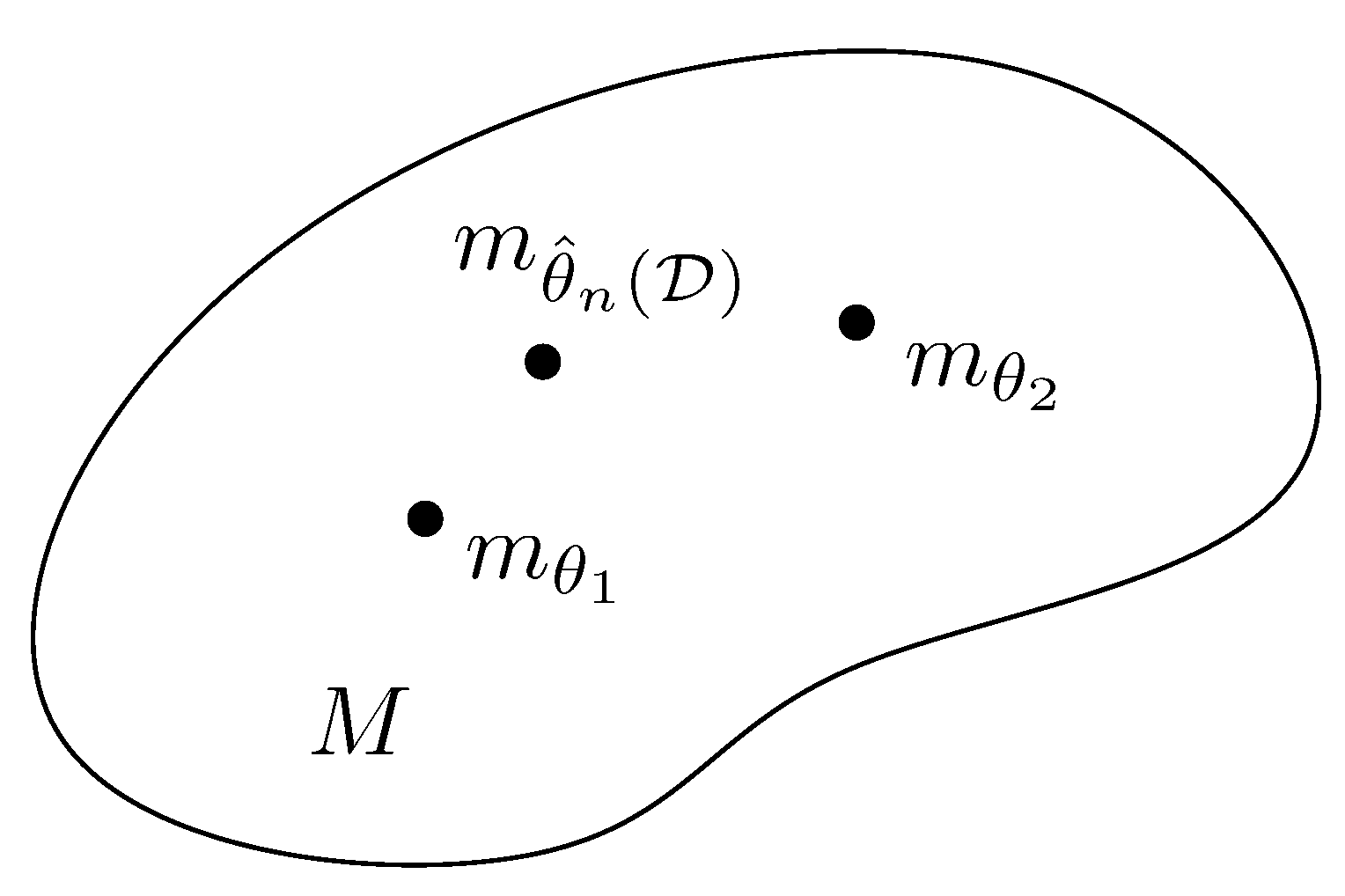
for any coarse-grained partition of (-lumping [59]) with , where for . This concept of coarse-graining is illustrated in Figure 10. This information monotonicity property could be renamed as the “distance coarse-binning inequality property.”
A separable divergence is a divergence that can be expressed as the sum of elementary scalar divergences :
For example, the squared Euclidean distance is a separable divergence for the scalar Euclidean divergence . The Euclidean distance is not separable because of the square root operation.
The only invariant and decomposable divergences when are f-divergences [60] defined for a convex functional generator f:
The standard f-divergences are defined for f-generators satisfying (choose since ), and (scale fixed).
Statistical f-divergences are invariant [61] under one-to-one/sufficient statistic transformations of sample space: :
The dual f-divergences for reference duality is
for the standard conjugate f-generator (diamond generator) with:
One can check that is a standard f-generator when f is standard.
Let us report some common examples of f-divergences:
- The family of -divergences:obtained for . The -divergences include:
- –
- The Kullback–Leibler when :for .
- –
- The reverse Kullback–Leibler :for .
- –
- The symmetric squared Hellinger divergence:for (corresponding to )
- –
- The Pearson and Neyman chi-squared divergences [62], etc.
- The Jensen–Shannon divergence:for .
- The Total Variationfor . The total variation distance is the only metric f-divergence (up to a scaling factor).
The f-topology is the topology generated by open f-balls, open balls with respect to f-divergences. A topology T is said to be stronger than a topology if T contains all the open sets of . Csiszar’s theorem [63] states that when , the -topology is equivalent to the topology induced by the total variation metric distance. Otherwise, the -topology is stronger than the TV topology.
Let us state an important feature of f divergences:
Theorem 9.
The f-divergences are invariant by diffeomorphisms of the sample space : Let , and with . Then we have .
Example 4.
Consider the exponential distributions and the Rayleigh distributions which are related by:
The densities of the exponential distributions are defined by
and the densities of the Rayleigh distributions are defined by
We have
It follows that
A remarkable property is that invariant standard f-divergences yield the Fisher information matrix and the -connections. Indeed, the invariant standard f-divergences is related infinitesimally to the Fisher metric as follows:
A statistical parameter divergence D on a parametric family of distributions yields an equivalent parameter divergence :
Thus we can build the information manifold induced by this parameter divergence . For , the induced -divergence connections and are precisely the expected -connections (derived from the exponential/mixture connections) with:
Thus the invariant connections which coincide with the connections induced by the invariant statistical divergences are the expected -connections. Note that the curvature of an expected -connection depends both on and on the considered statistical model [64].
3.11. Fisher–Rao Expected Riemannian Manifolds:
Historically, a first manifold modeling of a regular parametric family of distributions was to consider the Fisher Information Matrix (FIM) as the Riemannian metric tensor g (see [65,66]), with:
where . Under some regularity conditions, we can rewrite the FIM:
The Riemannian geodesic metric distance is commonly called the Fisher–Rao distance:
where denotes the geodesic passing through and . The Fisher–Rao distance can also be defined as the shortest path length: .
Definition 6
(Fisher–Rao distance). The Fisher–Rao distance is the geodesic metric distance of the Fisher–Riemannian manifold .
Let us give some examples of Fisher–Riemannian manifolds:
- The Fisher–Riemannian manifold of the family of bivariate location-scale families amount to hyperbolic geometry (hyperbolic manifold).
- The Fisher–Riemannian manifold of the family of location families amount to Euclidean geometry (Euclidean manifold).
The first fundamental form of the Riemannian geometry is where denotes the line element. Let us give an example of Fisher–Rao geometry for location-scale families:
Example 5.
Consider the location-scale family induced by a symmetric probability density with respect to 0 such that , and (with support ):
The density is called the standard density of the location-scale family, and corresponds to the parameter : . The parameter space corresponds to the upper plane, and the Fisher information matrix can be structurally calculated [67] as the following diagonal matrix:
with scalars:
By rescaling as with and , we get the FIM with respect to expressed as:
We recognize that this metric is a constant time the metric of the Poincaré upper plane. Thus the Fisher–Rao manifold of a location-scale family (with symmetric standard probability density f) is isometric to the planar hyperbolic space of negative curvature . In practice, the Klein non-conformal model of hyperbolic geometry is often used to implement computational geometric algorithms [20].
This Riemannian geometric structure applied to a family of parametric probability distributions was first proposed by Harold Hotelling [65] (in a handwritten note of 1929, reprinted typeset in [68]) and independently later by C. R. Rao [66] (1945, reprinted in [69]). In a similar vein, Jeffreys [70] proposed to use the volume element of a manifold as an invariant prior to 1946.
Notice that for a parametric family of probability distributions , the Riemannian structure coincides with the self-dual conjugate connection manifold induced by a symmetric f-divergence like the squared Hellinger divergence.
The exponential map at point provides a way to map back a vector to a point (when well-defined). The exponential map can be used to parameterize a geodesic with and unit tangent vector : . For geodesically complete manifolds, the exponential map is defined everywhere.
3.12. The Monotone -Embeddings and the Gauge Freedom of the Metric
Another common mathematically equivalent expression of the FIM [16] is given by:
This form of the FIM is well-suited to prove that the FIM is always a positive semi-definite matrix [16] (). It turns out that we can define a family of equivalent representations of the FIM using the -embedding [71] of the parametric family.
First, we define the -representation of densities with:
The function is called the -likelihood function. Then the -representation of the FIM, the -FIM for short, is expressed as:
We can rewrite compactly the -FIM, as . Expanding the -FIM, we get:
The 1-representation of the density is called the logarithmic representation (or e-representation), the -representation the mixture representation (or m-representation), and its 0-representation is called the square root representation. The set of -scores vectors are interpreted as the tangent basis vectors of the -base . Thus the FIM is -independent.
Furthermore, the -representation of the FIM can be rewritten under mild conditions [16] as:
Since we have:
it follows that:
Notice that when , we recover the equivalent expression of the FIM (under mild conditions):
In particular, when the family is an exponential family [52] with cumulant function (satisfying the mild conditions), we have:
Zhang [71,72] further discussed the representation/reference biduality which was confounded in the -geometry.
Gauge freedom of the Riemannian metric tensor has been investigated under the framework of -monotone embeddings [71,72,73] in information geometry: let and be two strictly increasing functions, and f a strictly convex function such that (with denoting its convex conjugate). Observe that the set of strictly increasing real-valued univariate functions has a group structure for the group operation chosen as the functional composition ∘. Let us write .
The -metric tensor can be derived from the -divergence:
We have:
3.13. Dually Flat Spaces and Canonical Bregman Divergences
We have described how to build a dually flat space from any strictly convex and smooth generator F: A Hessian structure is built from with Riemannian Hessian metric , and the convex conjugate (obtained by the Legendre–Fenchel duality) yields the dual Hessian structure with Riemannian Hessian metric . The dual connections ∇ and are coupled with the metric. The connections are defined by their respective Christoffel symbols and , showing that they are flat connections.
Conversely, it can be proved [2] that given two dually flat connections ∇ and , we can reconstruct two dual canonical strictly convex potential functions and such that and . The canonical divergence yields the dual Bregman divergences and .
The only symmetric Bregman divergences are squared Mahalanobis distances [40] with the Mahalanobis distance defined by:
Let be the Cholesky decomposition of a positive-definite matrix . It is well-known that the Mahalanobis distance amounts to the Euclidean distance on affinely transformed points:
where .
The squared Mahalanobis distance does not satisfy the triangle inequality, but the Mahalanobis distance is a metric distance. We can convert a Mahalanobis distance into another Mahalanobis distance , and vice versa, as follows:
Proof.
Let us write matrix using the Cholesky decomposition. Then we have
Then we have for two symmetric positive-definite matrices and :
It follows that we have:
□
We have (Bregman divergence) with for a positive-definite matrix . The convex conjugate (with ). We have and . We have the following identity between the dual Mahalanobis divergences and :
When the Bregman generator is based on an integral, i.e., the log-normalizer for exponential families , or the negative Shannon entropy for mixture families , the associated Bregman divergences or can be relaxed and interpreted as a statistical distance. We explain how to obtain the reconstruction below:
- Consider an exponential family of order D with densities defined according to a dominating measure :where the natural parameter and the sufficient statistic vector belong to . We have the integral-based Bregman generator:and the dual convex conjugatewhere denotes Shannon’s entropy.Let denotes the i-th coordinates of vector , and let us calculate the inner product of the Legendre–Fenchel divergence. We have . Using the linear property of the expectation , we find that . Moreover, we have . Thus we have:It follows that we getBy relaxing the exponential family densities and to be arbitrary densities and , we obtain the reverse KL divergence between and from the dually flat structure induced by the integral-based log-normalizer of an exponential family:Thus we have recovered the reverse Kullback–Leibler divergence from .The dual divergence is obtained by swapping the distribution parameter orders. We have:and .To summarize, the canonical Legendre–Fenchel divergence associated with the log-normalizer of an exponential family amounts to the statistical reverse Kullback–Leibler divergence between and (or the KL divergence between the swapped corresponding densities): . Notice that it is easy to check that [74,75]. Here, we took the opposite direction by constructing from .We may consider an auxiliary carrier term so that the densities write . Then the dual convex conjugate writes [76] as .Notice that since the Bregman generator is defined up to an affine term, we may consider the equivalent generator instead of the integral-based generator. This approach yields ways to build formula bypassing the explicit use of the log-normalizer for calculating various statistical distances [77].
- In this second example, we consider a mixture familywhere are linearly independent probability densities. The integral-based Bregman generator F is chosen as Shannon negentropy:We haveand the dual convex potential function isi.e., the cross-entropy between the density and the mixture . Let us calculate the inner product of the Legendre–Fenchel divergence as follows:That isThus it follows that we have the following statistical distance:Thus we have . By relaxing the mixture densities and to arbitrary densities and , we find that the dually flat geometry induced by the negentropy of densities of a mixture family induces a statistical distance which corresponds to the (forward) KL divergence. That is, we have recovered the statistical distance from . Note that in general the entropy of a mixture is not available in closed-form (because of the log sum term), except when the component distributions have pairwise disjoint supports. This latter case includes the case of Dirac distributions whose mixtures represent the categorical distributions.
Let us consider the dually flat spaces induced by the family of discrete Poisson distributions and the family of continuous gamma distributions:
Example 6.
Consider the family of Poisson distributions with rate parameter :
This family is a univariate discrete exponential family of order one (i.e., and ) with the following canonical decomposition of its probability mass function :
- Base measure: where μ is the counting measure and represents an auxiliary measure carrier term for defining the base measure ν,
- Sufficient statistics: ,
- Natural parameter: ,
- Log-normalizer: since .
Thus we can rewrite the Poisson family as the following Discrete Exponential Family (DEF):
The expectation is , or equivalently . The variance , or or equivalently . The Kullback–Leibler divergence between two Poisson distributions and is:
We recognize the expression of the univariate Kullback–Leibler divergence extended to the positive scalars.
We have and where is the convex conjugate of . Since , we deduce that the Fisher information is . Notice that . Thus we check the Crouzeix identity: . Beware that although , this is not the FIM . Using the covariance equation of the FIM of Equation (86), we have:
The Fisher–Rao distance [78] between two Poisson distributions and is:
In general, it is easy to get the Fisher–Rao distance of uniorder families because both the length elements and the geodesics are available in closed forms.
The following example demonstrates the computational intractability of the Fisher–Rao distance.
Example 7.
Consider the parametric family of Gamma distributions [79] with probability density:
for shape parameter , rate parameter and support . Function is the Gamma function defined for , and satisfying for integers n. The Gamma distributions form an univariate exponential family of order 2 (i.e., and ) with the following canonical decomposition:
- Natural parameters: with with source parameter ,
- Sufficient statistics: ,
- Log-normalizer: ,
- Dual parameterization: , where denotes the digamma function.
It follows that the Kullback–Leibler divergence between two Gamma distributions and with respective source parameters and is:
The Fisher information matrix is . It can be expressed using the λ-parameterization [80] as:
where is the trigamma function defined for by:
Because the Fisher information matrix is not diagonal using the λ-parameterization, we deduce that the parameters α and β are correlated (non-orthogonal). In general, by mixing the natural parameters θ with the expectation parameters η of an exponential family, we obtain a block-diagonal Fisher information matrix [2,80]. That is, let be a mixed primal/dual coordinate system for where D is the order of the family (or the dimension of the dually flat space). Then the Fisher information matrix for the mixed parameterization is block diagonal. Thus we can always diagonalize the Fisher information matrix of an exponential family of order 2. For example, for the gamma manifold, let us choose the reparameterization and . Then we have the Fisher information matrix that rewrites as:
The parameters and are not correlated and orthogonal since the FIM is diagonal.
The numerical evaluation of the Fisher–Rao distance between two gamma distributions has been studied in [81]. Let . The length element is shown to be in this parameterization:
However, no closed-form expression is known for the Fisher–Rao distance between two gamma distributions because of the intractability of the geodesic equations on the gamma Fisher–Rao manifold [81]. This example highlights the fact that computing the Fisher–Rao distance for simple family of distributions can be challenging. In fact, we do not know the Fisher–Rao distance between any two multivariate Gaussian distibutions [82] (except in a few cases including the univariate case).
In general, dually flat spaces can be built from any strictly convex generator F. Vinberg and Koszul [48] showed how to obtain such a convex generator for homogeneous cones. A cone in a vector space V yields a dual cone of positive linear functionals in the dual vector space :
The characteristic function of the cone is defined by
and the function defines a Bregman generator which induces a Hessian structure and a dually flat space.
Figure 11 displays the main types of information manifolds encountered in information geometry with their relationships.
4. Some Applications of Information Geometry
Information geometry [2] found broad applications in information sciences. For example, we can mention:
- Statistics: Asymptotic inference, Expectation-Maximization (EM and the novel information-geometric em), time series (AutoRegressive Moving Average model, ARMA) models,
- Signal processing: Principal Component Analysis (PCA), Independent Component Analysis (ICA), Non-negative Matrix Factorization (NMF),
- Mathematical programming: Barrier function of interior point methods,
- Game theory: Score functions.
Next, we shall describe a few applications, starting with the celebrated natural gradient descent.
4.1. Natural Gradient in Riemannian Space
The Natural Gradient [86] (NG) is an extension of the ordinary (Cartesian) gradient of Euclidean geometry to the gradient in a Riemannian space analyzed in an arbitrary coordinate system. We explain the natural gradient
4.1.1. The Vanilla Gradient Descent Method
Given a real-valued function parameterized by a a D-dimensional vector on parameter space , we wish to minimize , i.e., solve . The gradient descent (GD) method, also called the steepest descent method, is a first-order local optimization procedure which starts by initializing the parameter to an arbitrary value (say, ), and then iteratively updates at stage t the current location of to as follows:
The scalar is called the step size or learning rate in machine learning. The ordinary gradient (OG) (vector of partial derivatives) represents the steepest vector at of the function graph . The GD method was pioneered by Cauchy [87] (1847) and its convergence proof to a stationary point was first reported in Curry [88] (1944).
If we reparameterize the function using a one-to-one and onto differentiable mapping (with reciprocal inverse mapping ), the GD update rule transforms as:
where
Thus in general, the two gradient descent location sequences and (initialized at and ) are different (because usually ), and the two GDs may potentially reach different stationary points. In other words, the GD local optimization depends on the choice of the parameterization of the function L (i.e., or ). For example, minimizing with the gradient descent a temperature function with respect to Celsius degrees may yield a different result than minimizing the same temperature function expressed with respect to Fahrenheit degrees . That is, the GD optimization is extrinsic since it depends on the choice of the parameterization of the function, and does not take into account the underlying geometry of the parameter space .
The natural gradient precisely addresses this problem and solves it by choosing intrinsically the steepest direction with respect to a Riemannian metric tensor field on the parameter manifold. We shall explain the natural gradient descent method and highlight its connections with the Riemannian gradient descent, the mirror descent and even the ordinary gradient descent when the parameter space is dually flat.
4.1.2. Natural Gradient and Its Connection with the Riemannian Gradient
Let be a D-dimensional Riemannian space [10] equipped with a metric tensor g, and a smooth function to minimize on the manifold M. The Riemannian gradient [89] uses the Riemannian exponential map to update the sequence of points ’s on the manifold as follows:
where the Riemannian gradient is defined according to a directional derivative by:
with
However, the Riemannian exponential mapping is often computationally intractable since it requires to solve a system of second-order differential equations [10,22]. Thus instead of using , we shall rather use a computable Euclidean retraction of the exponential map expressed in a local -coordinate system as:
Using the retraction [22] which corresponds to a first-order Taylor approximation of the exponential map, we recover the natural gradient descent [86]:
The natural gradient [86] (NG)
encodes the Riemannian steepest descent vector, and the natural gradient descent method yields the following update rule
Notice that the natural gradient is a contravariant vector while the ordinary gradient is a covariant vector. Recall that a covariant vector is transformed into a contravariant vector by , that is by using the dual Riemannian metric . The natural gradient is invariant under an invertible smooth change of parameterization. However, the natural gradient descent does not guarantee that the locations ’s always stay on the manifold: Indeed, it may happen that for some t, when .
Property 5
([89]). The natural gradient descent approximates the intrinsic Riemannian gradient descent using a contravariant gradient vector induced by the Riemannian metric tensor g. The natural gradient is invariant to coordinate transformations.
Next, we shall explain how the natural gradient descent is related to the mirror descent and the ordinary gradient when the Riemannian space is dually flat.
4.1.3. Natural Gradient in Dually Flat Spaces: Connections to Bregman Mirror Descent and Ordinary Gradient
Recall that a dually flat space is a manifold M equipped with a pair of dual torsion-free flat connections which are coupled to the Riemannian metric tensor g [2,90] in the sense that , where denotes the unique metric torsion-free Levi–Civita connection.
On a dually flat space, there exists a pair of dual global Hessian structures [48] with dual canonical Bregman divergences [2,91]. The dual Riemannian metrics can be expressed as the Hessians of dual convex potential functions F and . Examples of Hessian manifolds are the manifolds of exponential families or the manifolds of mixture families [92]. On a dually flat space induced by a strictly convex and function F (Bregman generator), we have two dual global coordinate system: and , where denotes the Legendre–Fenchel convex conjugate function [51,93]. The Hessian metric expressed in the primal -coordinate system is , and the dual Hessian metric expressed in the dual coordinate system is . Crouzeix’s identity [36] shows that , where I denotes the matrix identity.
The ordinary gradient descent method can be extended using a proximity function as follows:
When , the PGD update rule becomes the ordinary GD update rule.
Consider a Bregman divergence [91] for the proximity function : . Then the PGD yields the following mirror descent (MD):
This mirror descent can be interpreted as a natural gradient descent as follows:
Property 6
([94]). Bregman mirror descent on the Hessian manifold is equivalent to natural gradient descent on the dual Hessian manifold , where F is a Bregman generator, and .
Indeed, the mirror descent rule yields the following natural gradient update rule:
where and .
The method is called mirror descent [95] because it performs that gradient step in the dual space (i.e., mirror space) , and thus solves the inconsistency contravariant/covariant type problem of subtracting a covariant vector from a contravariant vector of the ordinary GD (Equation (194)).
Let us prove now the following property of the natural gradient in a dually flat space or Bregman manifold [90]:
Property 7
([96]). In a dually flat space induced by potential convex function F, the natural gradient amounts to the ordinary gradient on the dually parameterized function: where and .
Proof.
Let be a dually flat space. We have since . The function to minimize can be written either as or as . Recall the chain rule in the calculus of differentiation:
Thus we have:
□
It follows that the natural gradient descent on a loss function amounts to an ordinary gradient descent on the dually parameterized loss function . In short, .
4.1.4. An Application of the Natural Gradient: Natural Evolution Strategies (NESs)
A nice family of applications of the natural gradient is the Natural Evolution Strategies (NESs) for black-box minimization [97]. Let for be a real-valued function to minimize. Berny [98] proposed to relax the optimization problem by considering a parametric search distribution , and minimize instead:
where denotes the parameter space of the search distributions. Let . Minimizing instead of is particularly useful when is a discrete space: Indeed, the combinatorial optimization [98] is replaced by a continuous optimization when is a continuous parameter, and the ordinary or natural GD methods can be used. The gradient is called the search gradient, and it can be approximated stochastically using the log-likelihood trick [99] as
where . Similarly, the Fisher information matrix (FIM) may be approximated by the following empirical FIM:
where denote the log-likelihood function. Notice that the approximated FIM may potentially be degenerated and may not respect the structure of the true FIM. For example, we have and . The non-diagonal of the approximate FIM are close to but usually non-zero although the expected FIM is diagonal . Thus we may estimate the FIM until the non-diagonal elements have absolute values less than a prescribed . For multivariate normals, we have and .
4.2. Some Illustrating Applications of Dually Flat Manifolds
In this part, we describe how to use the dually flat structures for handling an exponential family (in a hypothesis testing problem detailed in Section 4.3) and the mixture family (clustering statistical mixtures Section 4.4). Note that for a general divergence, neither nor is dually flat. However, when , the Kullback–Leibler divergence, we get dually flat spaces that are computationally attractive since the primal/dual geodesics are straight lines in the corresponding global affine coordinate system.
4.3. Hypothesis Testing in the Dually Flat Exponential Family Manifold
Given two probability distributions and , we ask to classify a set of iid. observations as either sampled from or from ? This is a statistical decision problem [100]. For example, can represent the signal distribution and the noise distribution. Figure 12 displays the probability distributions and the unavoidable error that is made by any statistical decision rule (on observations and ).
Assume that both distributions and belong to the same exponential family , and consider the exponential family manifold with the dually flat structure . That is, the manifold equipped with the Fisher information metric tensor field and the expected exponential connection and conjugate expected mixture connection. More generally, the expected -geometry of an exponential family with cumulant function F is given by:
When , and is flat, and so is by using the fundamental theorem of information geometry.
The -structure can also be derived from a divergence manifold structure by choosing the reverse Kullback–Leibler divergence :
Therefore, the Kullback–Leibler divergence amounts to a Bregman divergence (for the cumulant function of the exponential family):
The best exponent error of the best Maximum A Priori (MAP) decision rule is found by minimizing the Bhattacharyya distance to get the Chernoff information [101]:
On the exponential family manifold , the Bhattacharyya distance:
amounts to a skew Jensen parameter divergence [102] (also called Burbea-Rao divergence):
It can be shown that the Chernoff information [100,103,104] (that minimizes ) is equivalent to a Bregman divergence: Namely, the Bregman divergence for exponential families at the optimal exponent value .
Theorem 10
(Chernoff information [100]). The Chernoff information between two distributions belonging to the same exponential family amount to a Bregman divergence:
where , and denote the best exponent error.
Let denote the best exponent error. The geometry [100] of the best error exponent can be explained on the dually flat exponential family manifold as follows:
where denotes the exponential geodesic and the m-bisector:
Figure 13 illustrates how to retrieve the best error exponent from an exponential arc (-geodesic) intersecting the m-bisector.
Furthermore, instead of considering two distributions for this statistical binary decision problem, we may consider a set of n distributions of . The geometry of the error exponent in this multiple hypothesis testing setting has been investigated in [105]. On the dually flat exponential family manifold, it corresponds to check the exponential arcs between natural neighbors (sharing Voronoi subfaces) of a Bregman Voronoi diagram [40]. See Figure 14 for an illustration.
4.4. Clustering Mixtures in the Dually Flat Mixture Family Manifold
Given a set of k prescribed statistical distributions , all sharing the same support (say, ), a mixture family of order consists of all strictly convex combinations of these component distributions [56]:
Figure 15 displays two mixtures obtained as convex combinations of prescribed Laplacian, Gaussian and Cauchy component distributions (). When considering a set of prescribed Gaussian component distributions, we obtain a w-Gaussian Mixture Model, or w-GMM for short.
We consider the expected information manifold which is dually flat and equivalent to . That is, the KL between two mixtures with prescribed components (w-mixtures, for short) is equivalent to a Bregman divergence for , where is the differential Shannon information (negative entropy) [56]:
Consider a set of nw-mixtures [56]. Because is the negative differential entropy of a mixture (not available in closed form [106]), we approximate the untractable F by another close tractable generator . We use Monte Carlo stochastic sampling to get Monte-Carlo convex for an independent and identically distributed sample .
Thus we can build a nested sequence of tractable dually flat manifolds for nested sample sets converging to the ideal mixture manifold : (where convergence is defined with respect to the induced canonical Bregman divergence). A key advantage of this approach is that for a given sample , all computations carried inside the dually flat manifold are consistent, see [56].
For example, we can apply Bregman k-means [107] on these Monte Carlo dually flat spaces [108] of w-GMMs (Gaussian Mixture Models) to cluster a set of w-GMMs. Figure 16 displays the result of such a clustering.
We have briefly described two applications using dually flat manifolds: (1) the dually flat exponential manifold induced by the statistical reverse Kullback–Leibler divergence on an exponential family (structure ), and (2) the dually flat mixture manifold induced by the statistical Kullback–Leibler divergence on a mixture family (structure ). There are many other dually flat structures that can be met in a statistical context. For example, two other dually flat structures for the D-dimensional probability simplex are reported in Amari’s textbook [2]: (1) the conformally deforming of the -geometry (page 88, Equation 4.95 of [2]), and (2) the -escort geometry (page 91, Equation 4.114 of [2]).
5. Conclusions: Summary, Historical Background, and Perspectives
5.1. Summary
We explained the dualistic nature of information manifolds in information geometry. The dualistic structure is defined by a pair of conjugate connections coupled with the metric tensor that provides a dual parallel transport that preserves the metric. We showed how to extend this structure to a 1-parameter family of structures. From a pair of conjugate connections, the pipeline to build this 1-parameter family of structures can be informally summarized as:
We stated the fundamental theorem of information geometry on dual constant-curvature manifolds, including the special but important case of dually flat manifolds on which there exists two potential functions and global affine coordinate systems related by the Legendre–Fenchel transformation. Although, information geometry historically started with the Riemannian modeling of a parametric family of probability distributions by letting the metric tensor be the Fisher information matrix, we have emphasized the dualistic view of information geometry which considers non-Riemannian manifolds that can be derived from any divergence, and not necessarily tied to a statistical context (e.g., information manifold can be used in mathematical programming [109]). Let us notice that for any symmetric divergence (e.g., any symmetrized f-divergence like the squared Hellinger divergence), the induced conjugate connections coincide with the Levi–Civita connection but the Fisher–Rao metric distance does not coincide with the squared Hellinger divergence.
On one hand, a Riemannian metric distance is never a divergence because the rooted distance functions fail to be smooth at the extremities but a squared Riemmanian metric distance is always a divergence. On the other hand, taking the power of a divergence D (i.e., ) for some may yield a metric distance (e.g., the square root of the Jensen–Shannon divergence [110]), but this may not always be the case: the powered Jeffreys divergence is never a metric distance (see [111], page 889). Recently, the Optimal Transport (OT) theory [112] gained interest in statistics and machine learning. However, the optimal transport between two members of a same elliptically-contoured family has the same optimal transport formula distance (see [113] Eq. 16 and Eq. 17, although they have different Kullback–Leibler divergences). Another essential difference is that the Fisher–Rao manifold of location-scale families is hyperbolic but the Wasserstein manifold of location-scale families has positive curvature [113,114].
Notice that we may convert back and forth a similarity to a dissimilarity as follows:
When the dissimilarity satisfies the (additive) triangle inequality (i.e., for any triple ) then the corresponding similarity satisfies the multiplicative triangle inequality: . A metric transform on a metric distance D is a transformation T such that is a metric. The transformation is a metric transform which bounds potentially unbounded metric distances; that is, if D is an unbounded metric, then is a bounded metric distance. The transformation is not a metric transform since the squared of the Euclidean metric distance is not a metric distance.
5.2. A Brief Historical Review of Information Geometry
The field of Information Geometry (IG) was historically motivated by providing some differential-geometric structures to statistical models in order to reason geometrically about statistical problems with the endeavor goal of geometrizing mathematical statistics [4,12,13,14,115,116,117,118]: Professor Harold Hotelling [65] first considered in the late 1920s the Fisher Information Matrix (FIM) I as a Riemannian metric tensor g (i.e., the Fisher Information metric, FIm), and interpreted a parametric family of probability distributions M as a Riemannian manifold . Historically speaking, Hotelling attended the American Mathematical Society’s Annual Meeting in Bethlehem (Bethlehem, PA, USA) on 26–29 December 1929, but left before his scheduled talk on December 27. His handwritten notes on the “Spaces of Statistical Parameters” was read by a colleague and are fully typeset in [68]. We warmly thank Professor Stigler for sending us the scanned handwritten notes and for discussing by emails some historical aspects of the birth of information geometry. In this pioneering work, Hotelling mentioned that location-scale probability families yield Riemannian manifolds of constant non-positive curvatures. This Riemannian modeling of parametric family of densities was further independently studied by Calyampudi Radhakrishna Rao (C.R. Rao) in his celebrated paper [66] (1945) that also includes the Cramér–Rao lower bound [51] and the Rao–Blackwellization technique used in statistics. Nowadays the induced Riemannian metric distance is often called the Fisher–Rao distance [119] or Rao distance [81]. Yet another use of Riemannian geometry in statistics was pioneered by Harold Jeffreys [70] that proposed to use as an invariant prior the normalized volume element of the Fisher–Riemannian manifold. In those seminal papers, there was no theoretical justification of using the Fisher information matrix as a metric tensor (besides the fact that it is a well-defined positive-definite matrix for regular identifiable models). Nowadays, this Riemmanian metric tensor is called the information metric for short. Modern information geometry considers a generalization of this approach using a non-Riemannian dualistic modeling which coincides with the Riemannian manifold when , the Levi–Civita connection (the unique torsion-free affine connection compatible with the metric tensor). The Fisher–Rao geometry has also been explored in thermodynamics yielding the Ruppeiner geometry [120], and the geometry of thermodynamics is called nowadays called geometrothermodynamics [121].
In the 1960s, Nikolai Chentsov (also commonly written Čencov) studied the algebraic category of all statistical decision rules with its induced geometric structures: Namely, the -geometries (“equivalent differential geometry”) and the dually flat manifolds (“Nonsymmetric Pythagorean geometry” of the exponential families with respect to the Kullback–Leibler divergence). In the preface of the english translation of his 1972 russian monograph [115], the field of investigation is defined as “geometrical statistics.” However in the original Russian monograph, Chentsov used the russian term geometrostatistics. According to Professor Alexander Holevo, the geometrostatistics term was coined by Andrey Kolmogorov to define the field of differential geometry of statistical models. In the monograph of Chentsov [115], the Fisher information metric is shown to be the unique metric tensor (up to a scaling factor) yielding statistical invariance under Markov morphisms (see [57] for a simpler proof that generalizes to positive measures).
The dual nature of the information geometry was thoroughly investigated by Professor Shun-ichi Amari [122]. In the preface of his 1985 monograph [116], Professor Amari coined the term information geometry as follows: “The differential-geometrical method developed in statistics is also applicable to other fields of sciences such as information theory and systems theory... They together will open a new field, which I would like to call information geometry.” Professor Amari mentioned in [116] that he considered the Gaussian Riemannian manifold as a hyperbolic manifold in 1959, and was strongly influenced by Efron’s paper on statistical curvature [123] (1975) to study the family of -connections in the 1980s [122,124]. Professor Amari prepared his PhD under the supervision of Professor Kondo [125], an expert of differential geometry in touch with Professor Kawaguchi [126]. The role of differential geometry in statistics has been discussed in [127].
Note that the dual affine connections of information geometry have also been investigated independently in affine differential geometry [128] which considers invariance under volume-preserving affine transformations by defining a volume form instead of a metric form for Riemannian geometry. The notion of dual parallel transport compatible with the metric is due to Aleksandr Norden [129] and Rabindra Nath Sen [130,131,132] (see the Senian geometry in http://insaindia.res.in/detail/N54-0728).
We summarize the main fundamental structures of information manifolds below:
| Riemannian manifold | |
| Fisher–Riemannian (expected) Riemannian manifold | |
| Riemannian manifold with affine connection ∇ | |
| Chentsov’s manifold with affine exponential -connection | |
| Amari’s dualistic information manifold | |
| Amari’s (expected) information -manifold, -geometry | |
| Lauritzen’s statistical manifold [29] | |
| Eguchi’s conjugate connection manifold induced by divergence D | |
| Chentsov/Amari’s dually flat manifold induced by convex potential F |
We use the ≡ symbol to denote the equivalence of geometric structures. For example, we have .
5.3. Perspectives
We recommend the two recent textbooks [2,16] for an indepth covering of (parametric) information geometry, and the book [133] for a thorough description of some infinite-dimensional statistical models. (Japanese readers may refer to [134,135]) We did not report the various coefficients of the metric tensors, Christoffel symbols and skewness tensors for the expected -geometry of common parametric models like the multivariate Gaussian distributions, the Gamma/Beta distributions, etc. They can be found in [15,16] and in various articles dealing with less common family of distributions [15,64,136,137,138,139,140]. Although we have focused on the finite parametric setting, information geometry is also considering non-parametric families of distributions [141], and quantum information geometry [142].
We have shown that we can always create an information manifold from any divergence function D. It is therefore important to consider generic classes of divergences in applications, that are ideally axiomatized and shown to have exhaustive characteristics. The -skewed Jensen divergences [102] are defined by for a real-valued strictly convex function by:
where both and belong to the parameter space . Clearly, we have . We have the following asymptotic properties of skewed Jensen divergences [102]:
where is the Bregman divergence [91] induced by a strictly convex and differentiable function :
Appendix C further reports how to interpret geometrically these Jensen/Bregman divergences from the chordal slope theorem. Beyond the three main Bregman/Csiszár/Jensen classes (theses classes overlap [143]), we may also mention the class of conformal divergences [73,144,145], the class of projective divergences [146,147], etc. Figure 17 illustrates the relationships between the principal classes of distances.
There are many perspectives on information geometry as attested by the new Springer journal (see online at https://www.springer.com/mathematics/geometry/journal/41884), and the biannual international conference “Geometric Sciences of Information” (GSI) [148,149,150] with its collective post-conference edited books [151,152]. We also mention the edited book [153] on the Occasion of Shun-ichi Amari’s 80th birthday.
Additional materials are available online at https://FrankNielsen.github.io/SurveyIG/.
Funding
This research received no external funding.
Acknowledgments
FN would like to thank the organizers of the Geometry In Machine Learning workshop in 2018 (GiMLi, http://gimli.cc/2018/) for their kind keynote talk invitation, and specially Professor Søren Hauberg (Technical University of Denmark, DTU). This survey is based on the talk given at GiMLi. I am very thankful to Professor Stigler (University of Chicago, USA) and Professor Holevo (Steklov Mathematical Institute, Russia) for providing me feedback on some historical aspects of the field of information geometry. Finally, I would like to express my sincere thanks to Gaëtan Hadjeres (Sony Computer Science Laboratories Inc., Paris) for his careful proofreading and feedback.
Conflicts of Interest
The author declare no conflict of interest.
Appendix A. Monte Carlo Estimations of f-Divergences
Let be a probability space [154] with X denoting the sample space, F the -algebra, and a reference positive measure. The f-divergence [62,63] between two probability measures P and Q both absolutely continuous with respect to a positive measure for a convex generator strictly convex at 1 and satisfying is
where and (i.e., p and q denote the Radon-Nikodym derivatives with respect to ). We use the following conventions:
When , we retrieve the Kullback–Leibler divergence (KLD):
The KLD is usually difficult to calculate in closed-form, say, for example, between statistical mixture models [155]. A common technique is to estimate the KLD using Monte Carlo sampling using a proposal distribution r:
where . When r is chosen as p, the KLD can be estimated as:
Monte Carlo estimators are consistent under mild conditions: .
In practice, one problem when implementing Equation (A5), is that we may end up potentially with . This may have disastrous consequences as algorithms implemented by programs consider non-negative divergences to execute a correct workflow. The potential negative value problem of Equation (A5) comes from the fact that and . One way to circumvent this problem is to consider the extended f-divergences:
Definition A1
(Extended f-divergence). The extended f-divergence for a convex generator f, strictly convex at 1 and satisfying is defined by
Setting and in Equation (A7), and using the fact that , we get
Therefore we define the extended f-divergences as
That is, the formula for the extended f-divergences is
Then we estimate the extended f-divergence using importance sampling of the integral with respect to distribution r, using n variates as:
For example, for the KLD, we obtain the following Monte Carlo estimator:
since the extended KLD is
Equation (A12) can be interpreted as a sum of scalar Itakura–Saito divergences since the Itakura–Saito divergence is scale-invariant: with the scalar Itakura–Saito divergence
a Bregman divergence obtained for the generator .
Notice that the extended f-divergence is a f-divergence for the generator
We check that the generator satisfies both and , and we have . Thus with .
Let us remark that we only need to have the scalar function strictly convex at 1 to ensure that . Indeed, we may use the definition of Bregman divergences extended to strictly convex functions but not necessarily smooth functions [156,157]:
where denotes the subderivative of f at y.
Furthermore, noticing that for , we may enforce that , and obtain a standard f-divergence [2] which enjoys the property that , where denotes the Fisher information matrix of the parameteric family of densities.
Appendix B. The Multivariate Gaussian Family: An Exponential Family
We report the canonical decomposition of the multivariate Gaussian [158] family following [159]. The multivariate Gaussian family is also called the MultiVariate Normal family, or MVN family for short.
Let denote the composite (vector,matrix) parameter of an MVN. The d-dimensional MVN density is given by
where denotes the matrix determinant. The natural parameters are also expressed using both a vector parameter and a matrix parameter in a compound object . By defining the following compound inner product on a composite (vector,matrix) object
where denotes the matrix trace, we rewrite the MVN density of Equation (A17) in the canonical form of an exponential family [52]:
where
is the compound natural parameter and
is the compound sufficient statistic. The function is the strictly convex and continuously differentiable log-normalizer defined by:
The log-normalizer can be expressed using the ordinary parameters, , as:
The moment/expectation parameters [2] are
We report the conversion formula between the three types of coordinate systems (namely the ordinary parameter , the natural parameter and the moment parameter ) as follows:
The dual Legendre convex conjugate [2] is
and .
We check the Fenchel-Young equality when and :
The Kullback-Leibler divergence between two d-dimensional Gaussians distributions and (with ) is
We check that since and . Notice that when , we have
that is half the squared Mahalanobis distance for the precision matrix (a positive-definite matrix: ), where the Mahalanobis distance is defined for any positive matrix as follows:
Appendix C. Skew Jensen Divergences and Bregman Divergences
First, let us interpret geometrically the skewed Jensen divergences and the Bregman divergences using the chordal slope lemma of convexity theory [160] for univariate generators F:
Lemma A1 (Chordal slope lemma).
Let F be a strictly convex function on interval for . For any in I, we have:
That is, define the points , , and . Then the chordal slope lemma states that the slope of the chord is less than the slope of the chord , which is less than the slope of (Figure A1).
Figure A1.
Illustration of the chordal slope lemma.

Let for . Then the inequalities of the chordal slope lemma can be rewritten as:
since and . Thus we have:
or equivalently the following inequalities:
That is, we recover for (i.e., and ) the -skewed Jensen divergence [102]:
Now, a consequence of the chordal slope lemma is that for a strictly convex and differentiable function F, we have:
This can be geometrically visualized in Figure A1.
That is,
For multivariate strictly convex functions F, we observe that we can build a multivariate Bregman divergence from a family of 1D Bregman divergences [161] induced by the 1D strictly convex functions :
Theorem A1.
A multivariate Bregman divergence between two parameters and can be expressed as a univariate Bregman divergence for the generator induced by the parameters:
where
Proof.
The functions are 1D Bregman generators. Consider the directional derivative:
Since , , and , it follows that
□
Notations
Below is a list of notations we used in this document:
| inner product | |
| Mahalanobis distance , | |
| parameter divergence | |
| statistical divergence | |
| D, | Divergence and dual (reverse) divergence |
| Csiszár divergence | with |
| Bregman divergence | |
| Canonical divergence | |
| Bhattacharyya distance | |
| Jensen/Burbea-Rao divergence | |
| Chernoff information | |
| F, | Potential functions related by Legendre–Fenchel transformation |
| Riemannian distance | |
| B, | basis, reciprocal basis |
| natural basis | |
| covector basis (one-forms) | |
| contravariant components of vector v | |
| covariant components of vector v | |
| vector u is perpendicular to vector v () | |
| induced norm, length of a vector v | |
| M, S | Manifold, submanifold |
| tangent plane at p | |
| Tangent bundle | |
| space of smooth functions on M | |
| space of smooth vector fields on M | |
| direction derivative of f with respect to vector v | |
| Vector fields | |
| metric tensor (field) | |
| local coordinates x in a chat | |
| natural basis vector | |
| natural reciprocal basis vector | |
| ∇ | affine connection |
| covariant derivative | |
| parallel transport of vectors along a smooth curve c | |
| Parallel transport of along a smooth curve c | |
| , | geodesic, geodesic with respect to connection ∇ |
| Christoffel symbols of the first kind (functions) | |
| Christoffel symbols of the second kind (functions) | |
| R | Riemann–Christoffel curvature tensor |
| Lie bracket | |
| ∇-projection | |
| -projection | |
| C | Amari–Chentsov totally symmetric cubic 3-covariant tensor |
| parametric family of probability distributions | |
| exponential family, mixture family, probability simplex | |
| Fisher information matrix of family | |
| Fisher Information Matrix (FIM) for a parametric family | |
| Fisher information metric tensor field | |
| exponential connection | |
| mixture connection | |
| expected skewness tensor | |
| expected -connections | |
| ≡ | equivalence of geometric structures |
References
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 623–656. [Google Scholar] [CrossRef]
- Amari, S. Information Geometry and Its Applications; Applied Mathematical Sciences; Springer: Tokyo, Japan, 2016. [Google Scholar]
- Kakihara, S.; Ohara, A.; Tsuchiya, T. Information Geometry and Interior-Point Algorithms in Semidefinite Programs and Symmetric Cone Programs. J. Optim. Theory Appl. 2013, 157, 749–780. [Google Scholar] [CrossRef]
- Amari, S.; Nagaoka, H. Methods of Information Geometry; American Mathematical Society: Providence, RL, USA, 2007. [Google Scholar]
- Peirce, C.S. Chance, Love, and Logic: Philosophical Essays; U of Nebraska Press: Lincoln, NE, USA, 1998. [Google Scholar]
- Schurz, G. Patterns of abduction. Synthese 2008, 164, 201–234. [Google Scholar] [CrossRef]
- Wald, A. Statistical decision functions. Ann. Math. Stat. 1949, 165–205. [Google Scholar] [CrossRef]
- Wald, A. Statistical Decision Functions; Wiley: Chichester, UK, 1950. [Google Scholar]
- Dabak, A.G. A Geometry for Detection Theory. Ph.D. Thesis, Rice University, Houston, TX, USA, 1993. [Google Scholar]
- Do Carmo, M.P. Differential Geometry of Curves and Surfaces; Courier Dover Publications: New York, NY, USA, 2016. [Google Scholar]
- Amari, S.; Barndorff-Nielsen, O.E.; Kass, R.E.; Lauritzen, S.L.; Rao, C.R. Differential Geometry in Statistical Inference; Institute of Mathematical Statistics: Hayward, CA, USA, 1987. [Google Scholar]
- Dodson, C.T.J. (Ed.) Geometrization of Statistical Theory; ULDM Publications; University of Lancaster, Department of Mathematics: Bailrigg, UK, 1987. [Google Scholar]
- Murray, M.; Rice, J. Differential Geometry and Statistics; Number 48 in Monographs on Statistics and Applied Probability; Chapman and Hall: London, UK, 1993. [Google Scholar]
- Kass, R.E.; Vos, P.W. Geometrical Foundations of Asymptotic Inference; Wiley-Interscience: New York, NY, USA, 1997. [Google Scholar]
- Arwini, K.A.; Dodson, C.T.J. Information Geometry: Near Randomness and Near Independance; Springer: Berlin, Germany, 2008. [Google Scholar]
- Calin, O.; Udriste, C. Geometric Modeling in Probability and Statistics; Mathematics and Statistics, Springer International Publishing: Cham, Switzerland, 2014. [Google Scholar]
- Ay, N.; Jost, J.; Vân Lê, H.; Schwachhöfer, L. Information Geometry; Springer: Berlin, Germany, 2017; Volume 64. [Google Scholar]
- Corcuera, J.; Giummolè, F. A characterization of monotone and regular divergences. Ann. Inst. Stat. Math. 1998, 50, 433–450. [Google Scholar] [CrossRef]
- Mühlich, U. Fundamentals of Tensor Calculus for Engineers with a Primer on Smooth Manifolds; Springer: Berlin, Germany, 2017; Volume 230. [Google Scholar]
- Nielsen, F.; Nock, R. Hyperbolic Voronoi diagrams made easy. In Proceedings of the IEEE International Conference on Computational Science and Its Applications (ICCSA), Fukuoka, Japan, 23–26 March 2010; pp. 74–80. [Google Scholar]
- Whitney, H.; Eells, J.; Toledo, D. Collected Papers of Hassler Whitney; Nelson Thornes: London, UK, 1992. [Google Scholar]
- Absil, P.A.; Mahony, R.; Sepulchre, R. Optimization Algorithms on Matrix Manifolds; Princeton University Press: Princeton, NJ, USA, 2009. [Google Scholar]
- Cartan, E.J. On Manifolds with an Affine Connection and the Theory of General Relativity; Bibliopolis; Humanities Pr: London, UK, 1986. [Google Scholar]
- Akivis, M.A.; Rosenfeld, B.A. Élie Cartan (1869–1951); American Mathematical Society: Cambridge, MA, USA, 2011; Volume 123. [Google Scholar]
- Wanas, M. Absolute parallelism geometry: Developments, applications and problems. arXiv 2002, arXiv:gr-qc/0209050. [Google Scholar]
- Bourguignon, J.P. Ricci curvature and measures. Jpn. J. Math. 2009, 4, 27–45. [Google Scholar] [CrossRef]
- Baez, J.C.; Wise, D.K. Teleparallel gravity as a higher gauge theory. Commun. Math. Phys. 2015, 333, 153–186. [Google Scholar] [CrossRef]
- Ashburner, J.; Friston, K.J. Diffeomorphic registration using geodesic shooting and Gauss-Newton optimisation. NeuroImage 2011, 55, 954–967. [Google Scholar] [CrossRef] [Green Version]
- Lauritzen, S.L. Statistical manifolds. Differ. Geom. Stat. Inference 1987, 10, 163–216. [Google Scholar]
- Vân Lê, H. Statistical manifolds are statistical models. J. Geom. 2006, 84, 83–93. [Google Scholar]
- Furuhata, H. Hypersurfaces in statistical manifolds. Differ. Geom. Its Appl. 2009, 27, 420–429. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J. Divergence functions and geometric structures they induce on a manifold. In Geometric Theory of Information; Nielsen, F., Ed.; Springer: Berlin, Germany, 2014; pp. 1–30. [Google Scholar]
- Eguchi, S. Second order efficiency of minimum contrast estimators in a curved exponential family. Ann. Stat. 1983, 11, 793–803. [Google Scholar] [CrossRef]
- Eguchi, S. A differential geometric approach to statistical inference on the basis of contrast functionals. Hiroshima Math. J. 1985, 15, 341–391. [Google Scholar] [CrossRef]
- Hiriart-Urruty, J.B.; Lemaréchal, C. Fundamentals of Convex Analysis; Springer Science & Business Media: Berlin, Germany, 2012. [Google Scholar]
- Crouzeix, J.P. A relationship between the second derivatives of a convex function and of its conjugate. Math. Program. 1977, 13, 364–365. [Google Scholar] [CrossRef]
- Ay, N.; Amari, S. A novel approach to canonical divergences within information geometry. Entropy 2015, 17, 8111–8129. [Google Scholar] [CrossRef]
- Nielsen, F. What is ... an information projection? Not. AMS 2018, 65, 321–324. [Google Scholar] [CrossRef]
- Kurose, T. On the divergences of 1-conformally flat statistical manifolds. Tohoku Math. J. Second Ser. 1994, 46, 427–433. [Google Scholar] [CrossRef]
- Boissonnat, J.D.; Nielsen, F.; Nock, R. Bregman Voronoi diagrams. Discret. Comput. Geom. 2010, 44, 281–307. [Google Scholar] [CrossRef]
- Nielsen, F.; Piro, P.; Barlaud, M. Bregman vantage point trees for efficient nearest neighbor queries. In Proceedings of the 2009 IEEE International Conference on Multimedia and Expo, New York, NY, USA, 28 June–3 July 2009; pp. 878–881. [Google Scholar]
- Nielsen, F.; Boissonnat, J.D.; Nock, R. Visualizing Bregman Voronoi diagrams. In Proceedings of the Twenty-Third Annual Symposium on Computational Geometry, Gyeongju, Korea, 6–8 June 2007; pp. 121–122. [Google Scholar]
- Nock, R.; Nielsen, F. Fitting the smallest enclosing Bregman ball. In Proceedings of the European Conference on Machine Learning, Porto, Portugal, 3–7 October 2005; Springer: Berlin, Germany, 2005; pp. 649–656. [Google Scholar]
- Nielsen, F.; Nock, R. On the smallest enclosing information disk. Inf. Process. Lett. 2008, 105, 93–97. [Google Scholar] [CrossRef] [Green Version]
- Fischer, K.; Gärtner, B.; Kutz, M. Fast smallest-enclosing-ball computation in high dimensions. In Proceedings of the European Symposium on Algorithms, Budapest, Hungary, 16–19 September 2003; Springer: Berlin, Germany, 2003; pp. 630–641. [Google Scholar]
- Della Pietra, S.; Della Pietra, V.; Lafferty, J. Inducing features of random fields. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 380–393. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, F. On Voronoi Diagrams on the Information-Geometric Cauchy Manifolds. Entropy 2020, 22, 713. [Google Scholar] [CrossRef]
- Shima, H. The Geometry of Hessian Structures; World Scientific: New Jersey, NJ, USA, 2007. [Google Scholar]
- Zhang, J. Reference duality and representation duality in information geometry. AIP Conf. Proc. 2015, 1641, 130–146. [Google Scholar]
- Gomes-Gonçalves, E.; Gzyl, H.; Nielsen, F. Geometry and Fixed-Rate Quantization in Riemannian Metric Spaces Induced by Separable Bregman Divergences. In Proceedings of the 4th International Conference on Geometric Science of Information (GSI), Toulouse, France, 27–29 August 2019; Nielsen, F., Barbaresco, F., Eds.; Lecture Notes in Computer Science. Springer: Berlin, Germany, 2019; Volume 11712, pp. 351–358. [Google Scholar] [CrossRef]
- Nielsen, F. Cramér-Rao lower bound and information geometry. In Connected at Infinity II; Springer: Berlin, Germany, 2013; pp. 18–37. [Google Scholar]
- Nielsen, F.; Garcia, V. Statistical exponential families: A digest with flash cards. arXiv 2009, arXiv:0911.4863. [Google Scholar]
- Sato, Y.; Sugawa, K.; Kawaguchi, M. The geometrical structure of the parameter space of the two-dimensional normal distribution. Rep. Math. Phys. 1979, 16, 111–119. [Google Scholar] [CrossRef]
- Skovgaard, L.T. A Riemannian geometry of the multivariate normal model. Scand. J. Stat. 1984, 11, 211–223. [Google Scholar]
- Malagò, L.; Pistone, G. Information geometry of the Gaussian distribution in view of stochastic optimization. In Proceedings of the 2015 ACM Conference on Foundations of Genetic Algorithms XIII, Aberystwyth, UK, 17–20 January 2015; pp. 150–162. [Google Scholar]
- Nielsen, F.; Nock, R. On the geometry of mixtures of prescribed distributions. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2861–2865. [Google Scholar]
- Campbell, L.L. An extended Čencov characterization of the information metric. Proc. Am. Math. Soc. 1986, 98, 135–141. [Google Scholar]
- Vân Lê, H. The uniqueness of the Fisher metric as information metric. Ann. Inst. Stat. Math. 2017, 69, 879–896. [Google Scholar]
- Csiszár, I.; Shields, P.C. Information Theory and Statistics: A Tutorial; Foundations and Trends® in Communications and Information Theory; Now Publishers Inc.: Hanover, MA, USA, 2004; Volume 1, pp. 417–528. [Google Scholar]
- Jiao, J.; Courtade, T.A.; No, A.; Venkat, K.; Weissman, T. Information measures: The curious case of the binary alphabet. IEEE Trans. Inf. Theory 2014, 60, 7616–7626. [Google Scholar] [CrossRef]
- Qiao, Y.; Minematsu, N. A Study on Invariance of f-Divergence and Its Application to Speech Recognition. IEEE Trans. Signal Process. 2010, 58, 3884–3890. [Google Scholar] [CrossRef]
- Nielsen, F.; Nock, R. On the chi square and higher-order chi distances for approximating f-divergences. IEEE Signal Process. Lett. 2013, 21, 10–13. [Google Scholar] [CrossRef] [Green Version]
- Csiszár, I. Information-type measures of difference of probability distributions and indirect observation. Stud. Sci. Math. Hung. 1967, 2, 229–318. [Google Scholar]
- Mitchell, A.F.S. Statistical manifolds of univariate elliptic distributions. Int. Stat. Rev. 1988, 56, 1–16. [Google Scholar] [CrossRef]
- Hotelling, H. Spaces of statistical parameters. Bull. Am. Math. Soc. (AMS) 1930, 36, 191. [Google Scholar]
- Rao, R.C. Information and the accuracy attainable in the estimation of statistical parameters. Bull. Calcutta Math. Soc. 1945, 37, 81–91. [Google Scholar]
- Komaki, F. Bayesian prediction based on a class of shrinkage priors for location-scale models. Ann. Inst. Stat. Math. 2007, 59, 135–146. [Google Scholar] [CrossRef]
- Stigler, S.M. The epic story of maximum likelihood. Stat. Sci. 2007, 22, 598–620. [Google Scholar] [CrossRef]
- Rao, C.R. Information and the accuracy attainable in the estimation of statistical parameters. In Breakthroughs in Statistics; Springer: Berlin, Germany, 1992; pp. 235–247. [Google Scholar]
- Jeffreys, H. An invariant form for the prior probability in estimation problems. Proc. R. Soc. Lond. A 1946, 186, 453–461. [Google Scholar]
- Zhang, J. On monotone embedding in information geometry. Entropy 2015, 17, 4485–4499. [Google Scholar] [CrossRef] [Green Version]
- Naudts, J.; Zhang, J. Rho–tau embedding and gauge freedom in information geometry. Inf. Geom. 2018. [Google Scholar] [CrossRef]
- Nock, R.; Nielsen, F.; Amari, S. On Conformal Divergences and Their Population Minimizers. IEEE TIT 2016, 62, 527–538. [Google Scholar] [CrossRef] [Green Version]
- Azoury, K.S.; Warmuth, M.K. Relative loss bounds for on-line density estimation with the exponential family of distributions. Mach. Learn. 2001, 43, 211–246. [Google Scholar] [CrossRef] [Green Version]
- Banerjee, A.; Merugu, S.; Dhillon, I.S.; Ghosh, J. Clustering with Bregman divergences. J. Mach. Learn. Res. 2005, 6, 1705–1749. [Google Scholar]
- Nielsen, F.; Nock, R. Entropies and cross-entropies of exponential families. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 3621–3624. [Google Scholar]
- Nielsen, F.; Nock, R. Cumulant-free closed-form formulas for some common (dis)similarities between densities of an exponential family. Tech. Rep. 2020. [Google Scholar] [CrossRef]
- Amari, S. Differential geometry of a parametric family of invertible linear systems: Riemannian metric, dual affine connections, and divergence. Math. Syst. Theory 1987, 20, 53–82. [Google Scholar] [CrossRef]
- Schwander, O.; Nielsen, F. Fast learning of Gamma mixture models with k-MLE. In Proceedings of the International Workshop on Similarity-Based Pattern Recognition, York, UK, 3–5 July 2013; Springer: Berlin, Germany, 2013; pp. 235–249. [Google Scholar]
- Miura, K. An introduction to maximum likelihood estimation and information geometry. Interdiscip. Inf. Sci. 2011, 17, 155–174. [Google Scholar] [CrossRef] [Green Version]
- Reverter, F.; Oller, J.M. Computing the Rao distance for Gamma distributions. J. Comput. Appl. Math. 2003, 157, 155–167. [Google Scholar] [CrossRef] [Green Version]
- Pinele, J.; Strapasson, J.E.; Costa, S.I. The Fisher-Rao Distance between Multivariate Normal Distributions: Special Cases, Bounds and Applications. Entropy 2020, 22, 404. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, F. Pattern learning and recognition on statistical manifolds: An information-geometric review. In Proceedings of the International Workshop on Similarity-Based Pattern Recognition, York, UK, 3–5 July 2013; Springer: Berlin, Germany, 2013; pp. 1–25. [Google Scholar]
- Sun, K.; Nielsen, F. Lightlike Neuromanifolds, Occam’s Razor and Deep Learning. arXiv 2019, arXiv:1905.11027. [Google Scholar]
- Sun, K.; Nielsen, F. Relative Fisher Information and Natural Gradient for Learning Large Modular Models. In Proceedings of the 34th International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; pp. 3289–3298. [Google Scholar]
- Amari, S. Natural gradient works efficiently in learning. Neural Comput. 1998, 10, 251–276. [Google Scholar] [CrossRef]
- Cauchy, A. Methode générale pour la résolution des systèmes d’équations simultanées. C. R. l’Académie Sci. 1847, 25, 536–538. [Google Scholar]
- Curry, H.B. The method of steepest descent for non-linear minimization problems. Q. Appl. Math. 1944, 2, 258–261. [Google Scholar] [CrossRef] [Green Version]
- Bonnabel, S. Stochastic gradient descent on Riemannian manifolds. IEEE Trans. Autom. Control 2013, 58, 2217–2229. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, F. On geodesic triangles with right angles in a dually flat space. arXiv 2019, arXiv:1910.03935. [Google Scholar]
- Bregman, L.M. The relaxation method of finding the common point of convex sets and its application to the solution of problems in convex programming. USSR Comput. Math. Math. Phys. 1967, 7, 200–217. [Google Scholar] [CrossRef]
- Nielsen, F.; Hadjeres, G. Monte Carlo information-geometric structures. In Geometric Structures of Information; Springer: Berlin, Germany, 2019; pp. 69–103. [Google Scholar]
- Nielsen, F. Legendre Transformation and Information Geometry; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Raskutti, G.; Mukherjee, S. The information geometry of mirror descent. IEEE Trans. Inf. Theory 2015, 61, 1451–1457. [Google Scholar] [CrossRef] [Green Version]
- Bubeck, S. Convex Optimization: Algorithms and Complexity; Foundations and Trends® in Machine Learning: Hanover, MA, USA, 2015; Volume 8, pp. 231–357. [Google Scholar]
- Zhang, G.; Sun, S.; Duvenaud, D.; Grosse, R. Noisy natural gradient as variational inference. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5852–5861. [Google Scholar]
- Beyer, H.G.; Schwefel, H.P. Evolution strategies–A comprehensive introduction. Nat. Comput. 2002, 1, 3–52. [Google Scholar] [CrossRef]
- Berny, A. Selection and reinforcement learning for combinatorial optimization. In Proceedings of the International Conference on Parallel Problem Solving from Nature, Paris, France, 18–20 September 2000; Springer: Berlin, Germany, 2000; pp. 601–610. [Google Scholar]
- Wierstra, D.; Schaul, T.; Glasmachers, T.; Sun, Y.; Peters, J.; Schmidhuber, J. Natural evolution strategies. J. Mach. Learn. Res. 2014, 15, 949–980. [Google Scholar]
- Nielsen, F. An Information-Geometric Characterization of Chernoff Information. IEEE Sig. Proc. Lett. 2013, 20, 269–272. [Google Scholar] [CrossRef]
- Pham, G.; Boyer, R.; Nielsen, F. Computational Information Geometry for Binary Classification of High-Dimensional Random Tensors. Entropy 2018, 20, 203. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, F.; Boltz, S. The Burbea-Rao and Bhattacharyya centroids. IEEE Trans. Inf. Theory 2011, 57, 5455–5466. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, F. Chernoff Information of Exponential Families. arXiv 2011, arXiv:1102.2684. [Google Scholar]
- Nielsen, F. Generalized Bhattacharyya and Chernoff upper bounds on Bayes error using quasi-arithmetic means. Pattern Recognit. Lett. 2014, 42, 25–34. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, F. Hypothesis Testing, Information Divergence and Computational Geometry. In Proceedings of the International Conference on Geometric Science of Information Geometric Science of Information (GSI), Paris, France, 28–30 August 2013; pp. 241–248. [Google Scholar]
- Nielsen, F.; Sun, K. Guaranteed Bounds on Information-Theoretic Measures of Univariate Mixtures Using Piecewise Log-Sum-Exp Inequalities. Entropy 2016, 18, 442. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, F.; Nock, R. Sided and symmetrized Bregman centroids. IEEE Trans. Inf. Theory 2009, 55, 2882–2904. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, F.; Hadjeres, G. Monte Carlo Information Geometry: The dually flat case. arXiv 2018, arXiv:1803.07225. [Google Scholar]
- Ohara, A.; Tsuchiya, T. An Information Geometric Approach to Polynomial-Time Interior-Point Algorithms: Complexity Bound via Curvature Integral; Research Memorandum; The Institute of Statistical Mathematics: Tokyo, Japan, 2007; Volume 1055. [Google Scholar]
- Fuglede, B.; Topsøe, F. Jensen-Shannon divergence and Hilbert space embedding. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Chicago, IL, USA, 27 June–2 July 2004; p. 31. [Google Scholar]
- Vajda, I. On metric divergences of probability measures. Kybernetika 2009, 45, 885–900. [Google Scholar]
- Villani, C. Optimal Transport: Old and New; Springer Science & Business Media: Berlin, Germany, 2008; Volume 338. [Google Scholar]
- Dowson, D.C.; Landau, B.V. The Fréchet distance between multivariate normal distributions. J. Multivar. Anal. 1982, 12, 450–455. [Google Scholar] [CrossRef] [Green Version]
- Takatsu, A. Wasserstein geometry of Gaussian measures. Osaka J. Math. 2011, 48, 1005–1026. [Google Scholar]
- Chentsov, N.N. Statistical Decision Rules and Optimal Inference; Monographs; American Mathematical Society: Providence, RI, USA, 1982. [Google Scholar]
- Amari, S. Differential-Geometrical Methods in Statistics; Lecture Notes on Statistics; Second Edition in 1990; Springer: New York, NY, USA, 1985; Volume 28. [Google Scholar]
- Amari, S.; Nagaoka, H. Methods of Information Geometry; Jouhou kika no Houhou; Iwanami Shoten: Tokyo, Japan, 1993. (In Japanese) [Google Scholar]
- Gibilisco, P.; Riccomagno, E.; Rogantin, M.P.; Wynn, H.P. (Eds.) Algebraic and Geometric Methods in Statistics; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Srivastava, A.; Wu, W.; Kurtek, S.; Klassen, E.; Marron, J.S. Registration of Functional Data Using Fisher-Rao Metric. arXiv 2011, arXiv:1103.3817. [Google Scholar]
- Wei, S.W.; Liu, Y.X.; Mann, R.B. Ruppeiner geometry, phase transitions, and the microstructure of charged AdS black holes. Phys. Rev. D 2019, 100, 124033. [Google Scholar] [CrossRef] [Green Version]
- Quevedo, H. Geometrothermodynamics. J. Math. Phys. 2007, 48, 013506. [Google Scholar] [CrossRef] [Green Version]
- Amari, S. Theory of Information Spaces: A Differential Geometrical Foundation of Statistics; Post RAAG Reports; Tokyo, Japan, 1980; Available online: https://bsi-ni.brain.riken.jp/database/item/92 (accessed on 29 September 2020).
- Efron, B. Defining the curvature of a statistical problem (with applications to second order efficiency). Ann. Stat. 1975, 3, 1189–1242. [Google Scholar] [CrossRef]
- Nagaoka, H.; Amari, S. Differential Geometry of Smooth Families of Probability Distributions; Technical Report; METR 82-7; University of Tokyo: Tokyo, Japan, 1982. [Google Scholar]
- Croll, G.J. The Natural Philosophy of Kazuo Kondo. arXiv 2007, arXiv:0712.0641. [Google Scholar]
- Kawaguchi, M. An introduction to the theory of higher order spaces I. The theory of Kawaguchi spaces. RAAG Memoirs 1960, 3, 718–734. [Google Scholar]
- Barndorff-Nielsen, O.E.; Cox, D.R.; Reid, N. The role of differential geometry in statistical theory. Int. Stat. Rev. 1986, 54, 83–96. [Google Scholar] [CrossRef] [Green Version]
- Nomizu, K.; Katsumi, N.; Sasaki, T. Affine Differential Geometry: Geometry of Affine Immersions; Cambridge University Press: Cambridge, UK, 1994. [Google Scholar]
- Norden, A.P. On Pairs of Conjugate Parallel Displacements in Multidimensional Spaces. In Doklady Akademii nauk SSSR; Kazan State University, Comptes rendus de l’Académie des Sciences de l’URSS: Kazan, Russia, 1945; Volume 49, pp. 1345–1347. [Google Scholar]
- Sen, R.N. On parallelism in Riemannian space I. Bull. Calcutta Math. Soc. 1944, 36, 102–107. [Google Scholar]
- Sen, R.N. On parallelism in Riemannian space II. Bull. Calcutta Math. Soc. 1944, 37, 153–159. [Google Scholar]
- Sen, R.N. On parallelism in Riemannian space III. Bull. Calcutta Math. Soc. 1946, 38, 161–167. [Google Scholar]
- Giné, E.; Nickl, R. Mathematical Foundations of Infinite-Dimensional Statistical Models; Cambridge University Press: Cambridge, UK, 2015; Volume 40. [Google Scholar]
- Amari, S. New Developments of Information Geometry; Jouhou Kikagaku no Shintenkai; Saiensu’sha: Tokyo, Japan, 2014. (In Japanese) [Google Scholar]
- Fujiwara, A. Foundations of Information Geometry; Jouhou Kikagaku no Kisou; Makino Shoten: Tokyo, Japan, 2015; p. 223. (In Japanese) [Google Scholar]
- Mitchell, A.F.S. The information matrix, skewness tensor and α-connections for the general multivariate elliptic distribution. Ann. Inst. Stat. Math. 1989, 41, 289–304. [Google Scholar] [CrossRef]
- Zhang, Z.; Sun, H.; Zhong, F. Information geometry of the power inverse Gaussian distribution. Appl. Sci. 2007, 9, 194–203. [Google Scholar]
- Peng, T.L.L.; Sun, H. The geometric structure of the inverse gamma distribution. Contrib. Algebra Geom. 2008, 49, 217–225. [Google Scholar]
- Zhong, F.; Sun, H.; Zhang, Z. The geometry of the Dirichlet manifold. J. Korean Math. Soc. 2008, 45, 859–870. [Google Scholar] [CrossRef]
- Peng, L.; Sun, H.; Jiu, L. The geometric structure of the Pareto distribution. Bol. Asoc. Mat. Venez. 2007, 14, 5–13. [Google Scholar]
- Pistone, G. Nonparametric information geometry. In Geometric Science of Information; Springer: Berlin, Germany, 2013; pp. 5–36. [Google Scholar]
- Hayashi, M. Quantum Information; Springer: Berlin, Germany, 2006. [Google Scholar]
- Pardo, M.d.C.; Vajda, I. About distances of discrete distributions satisfying the data processing theorem of information theory. IEEE Trans. Inf. Theory 1997, 43, 1288–1293. [Google Scholar] [CrossRef]
- Nielsen, F.; Nock, R. Total Jensen divergences: Definition, properties and k-means++ clustering. arXiv 2013, arXiv:1309.7109. [Google Scholar]
- Nielsen, F.; Nock, R. Total Jensen divergences: Definition, properties and clustering. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 2016–2020. [Google Scholar]
- Nielsen, F.; Nock, R. Patch Matching with Polynomial Exponential Families and Projective Divergences. In Proceedings of the International Conference on Similarity Search and Applications (SISAP), Tokyo, Japan, 24–26 October 2016; pp. 109–116. [Google Scholar]
- Nielsen, F.; Sun, K.; Marchand-Maillet, S. On Hölder Projective Divergences. Entropy 2017, 19, 122. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, F.; Barbaresco, F. (Eds.) Geometric Science of Information; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2013; Volume 8085. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, F.; Barbaresco, F. (Eds.) Geometric Science of Information; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2015; Volume 9389. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, F.; Barbaresco, F. (Eds.) Geometric Science of Information; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2017; Volume 10589. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, F. Geometric Structures of Information; Springer: Berlin, Germany, 2018. [Google Scholar]
- Nielsen, F. Geometric Theory of Information; Springer: Berlin, Germany, 2014. [Google Scholar]
- Ay, N.; Gibilisco, P.; Matús, F. Information Geometry and its Applications: On the Occasion of Shun-ichi Amari’s 80th Birthday, IGAIA IV Liblice, Czech Republic, 12–17 June 2016; Springer Proceedings in Mathematics & Statistics; Springer: Berlin, Germany, 2018; Volume 252. [Google Scholar]
- Keener, R.W. Theoretical Statistics: Topics for a Core Course; Springer: Berlin, Germany, 2011. [Google Scholar]
- Nielsen, F.; Sun, K. Guaranteed bounds on the Kullback–Leibler divergence of univariate mixtures. IEEE Signal Process. Lett. 2016, 23, 1543–1546. [Google Scholar] [CrossRef]
- Gordon, G.J. Approximate Solutions to Markov Decision Processes. Ph.D. Thesis, Carnegie Mellon University, Pittsburgh, PA, USA, 1999. [Google Scholar]
- Telgarsky, M.; Dasgupta, S. Agglomerative Bregman clustering. In Proceedings of the 29th International Conference on Machine Learning, Edinburgh, UK, 26 June–1 July 2012; Omnipress: Madison, WI, USA; pp. 1011–1018. [Google Scholar]
- Yoshizawa, S.; Tanabe, K. Dual differential geometry associated with Kullback–Leibler information on the Gaussian distributions and its 2-parameter deformations. SUT J. Math. 1999, 35, 113–137. [Google Scholar]
- Nielsen, F. On the Jensen–Shannon symmetrization of distances relying on abstract means. Entropy 2019, 21, 485. [Google Scholar] [CrossRef] [Green Version]
- Niculescu, C.; Persson, L.E. Convex Functions and Their Applications; Springer: Berlin, Germany, 2006. [Google Scholar]
- Nielsen, F.; Nock, R. The Bregman chord divergence. In Proceedings of the International Conference on Geometric Science of Information, Toulouse, France, 27–29 August 2019; Springer: Berlin, Germany; pp. 299–308. [Google Scholar]
Figure 1.
The parameter inference of a model from data can also be interpreted as a decision making problem: decide which parameter of a parametric family of models suits the “best” the data. Information geometry provides a differential-geometric structure on manifold M which useful for designing and studying statistical decision rules.
Figure 1.
The parameter inference of a model from data can also be interpreted as a decision making problem: decide which parameter of a parametric family of models suits the “best” the data. Information geometry provides a differential-geometric structure on manifold M which useful for designing and studying statistical decision rules.

Figure 2.
Primal basis (red) and reciprocal basis (blue) of an inner product space. The primal/reciprocal basis are mutually orthogonal: is orthogonal to , and is orthogonal to .
Figure 2.
Primal basis (red) and reciprocal basis (blue) of an inner product space. The primal/reciprocal basis are mutually orthogonal: is orthogonal to , and is orthogonal to .

Figure 3.
Illustration of the parallel transport of vectors on tangent planes along a smooth curve. For a smooth curve c, with and , a vector is parallel transported smoothly to a vector such that for any , we have .
Figure 3.
Illustration of the parallel transport of vectors on tangent planes along a smooth curve. For a smooth curve c, with and , a vector is parallel transported smoothly to a vector such that for any , we have .

Figure 4.
Parallel transport with respect to the metric connection: the curvature effect can be visualized as the angle defect along the parallel transport on smooth (infinitesimal) loops. For a sphere manifold, a vector parallel-transported along a loop does not coincide with itself (e.g., a sphere), while it always conside with itself for a (flat) manifold (e.g., a cylinder).
Figure 4.
Parallel transport with respect to the metric connection: the curvature effect can be visualized as the angle defect along the parallel transport on smooth (infinitesimal) loops. For a sphere manifold, a vector parallel-transported along a loop does not coincide with itself (e.g., a sphere), while it always conside with itself for a (flat) manifold (e.g., a cylinder).

Figure 5.
Differential-geometric concepts associated to an affine connection ∇ and a metric tensor g.
Figure 5.
Differential-geometric concepts associated to an affine connection ∇ and a metric tensor g.

Figure 6.
Dual Pythagorean theorems in a dually flat space.

Figure 7.
Five concentric pairs of dual Itakura–Saito circles.

Figure 8.
Common dually flat spaces associated to smooth and strictly convex generators.

Figure 9.
Visualizing the Cramér–Rao lower bound: the red ellipses display the Fisher information matrix of normal distributions at grid locations. The black ellipses are sample covariance matrices centered at the sample means calculated by repeating 200 runs of sampling 100 iid variates for the normal parameters of the grid.
Figure 9.
Visualizing the Cramér–Rao lower bound: the red ellipses display the Fisher information matrix of normal distributions at grid locations. The black ellipses are sample covariance matrices centered at the sample means calculated by repeating 200 runs of sampling 100 iid variates for the normal parameters of the grid.

Figure 10.
A divergence satisfies the property of information monotonicity iff . Here, parameter represents a discrete distribution.
Figure 10.
A divergence satisfies the property of information monotonicity iff . Here, parameter represents a discrete distribution.

Figure 11.
Overview of the main types of information manifolds with their relationships in information geometry.
Figure 11.
Overview of the main types of information manifolds with their relationships in information geometry.

Figure 12.
Statistical Bayesian hypothesis testing: the best Maximum A Posteriori (MAP) rule chooses to classify an observation from the class that yields the maximum likelihood.
Figure 12.
Statistical Bayesian hypothesis testing: the best Maximum A Posteriori (MAP) rule chooses to classify an observation from the class that yields the maximum likelihood.

Figure 13.
Exact geometric characterization (not necessarily i closed-form) of the best exponent error rate .
Figure 13.
Exact geometric characterization (not necessarily i closed-form) of the best exponent error rate .

Figure 14.
Geometric characterization of the best exponent error rate in the multiple hypothesis testing case.
Figure 14.
Geometric characterization of the best exponent error rate in the multiple hypothesis testing case.

Figure 15.
Example of a mixture family of order (3 components: Laplacian, Gaussian and Cauchy prefixed distributions).
Figure 15.
Example of a mixture family of order (3 components: Laplacian, Gaussian and Cauchy prefixed distributions).

Figure 16.
Example of w-GMM clustering into clusters.

Figure 17.
Principled classes of distances/divergences.

© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Nielsen, F. An Elementary Introduction to Information Geometry. Entropy 2020, 22, 1100. https://doi.org/10.3390/e22101100
AMA Style
Nielsen F. An Elementary Introduction to Information Geometry. Entropy. 2020; 22(10):1100. https://doi.org/10.3390/e22101100
Chicago/Turabian StyleNielsen, Frank. 2020. "An Elementary Introduction to Information Geometry" Entropy 22, no. 10: 1100. https://doi.org/10.3390/e22101100
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.