
An Explainable Artificial Intelligence Approach for Multi-Criteria ABC Item Classification

 , , and
, , and
Abstract
:1. Introduction
1.1. Literature Review of Inventory Classification Methods
1.2. ABC Inventory Classification: Problem Definition and Challenges
2. Background on Explainable Clustering
2.1. Explainable Clustering
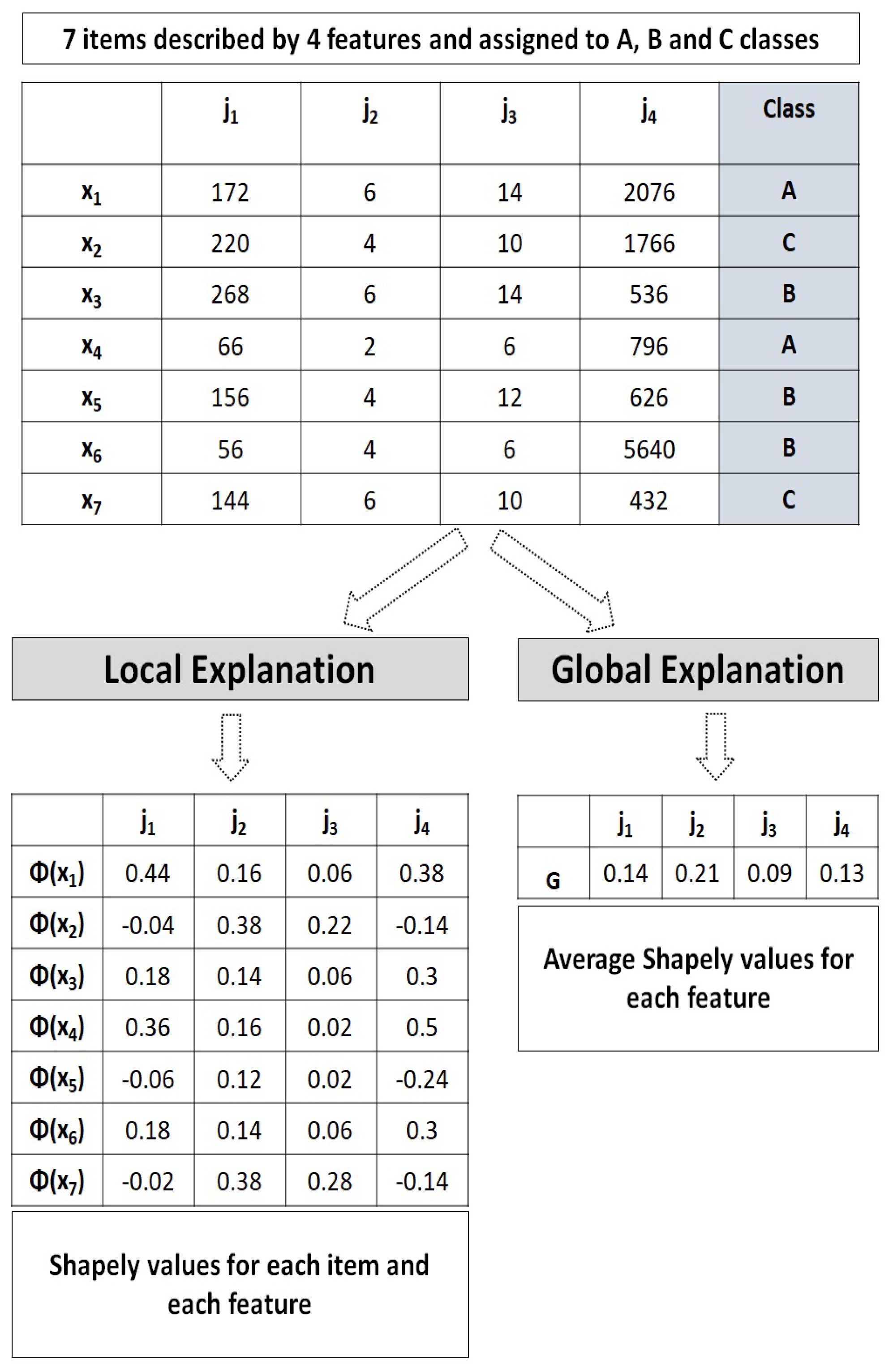
2.2. SHAP (Shapley Additive Explanations)
3. Proposed Explainable Clustering Method for Multi-Criteria ABC Inventory Classification
3.1. Phase 1: Item Classification
3.2. Phase 2: ABC-Inventory-Interpretation Phase
4. Experiments and Results
4.1. Evaluation of the Clustering Performance
4.2. Local Explanations of Item Assignment to the ABC Classes
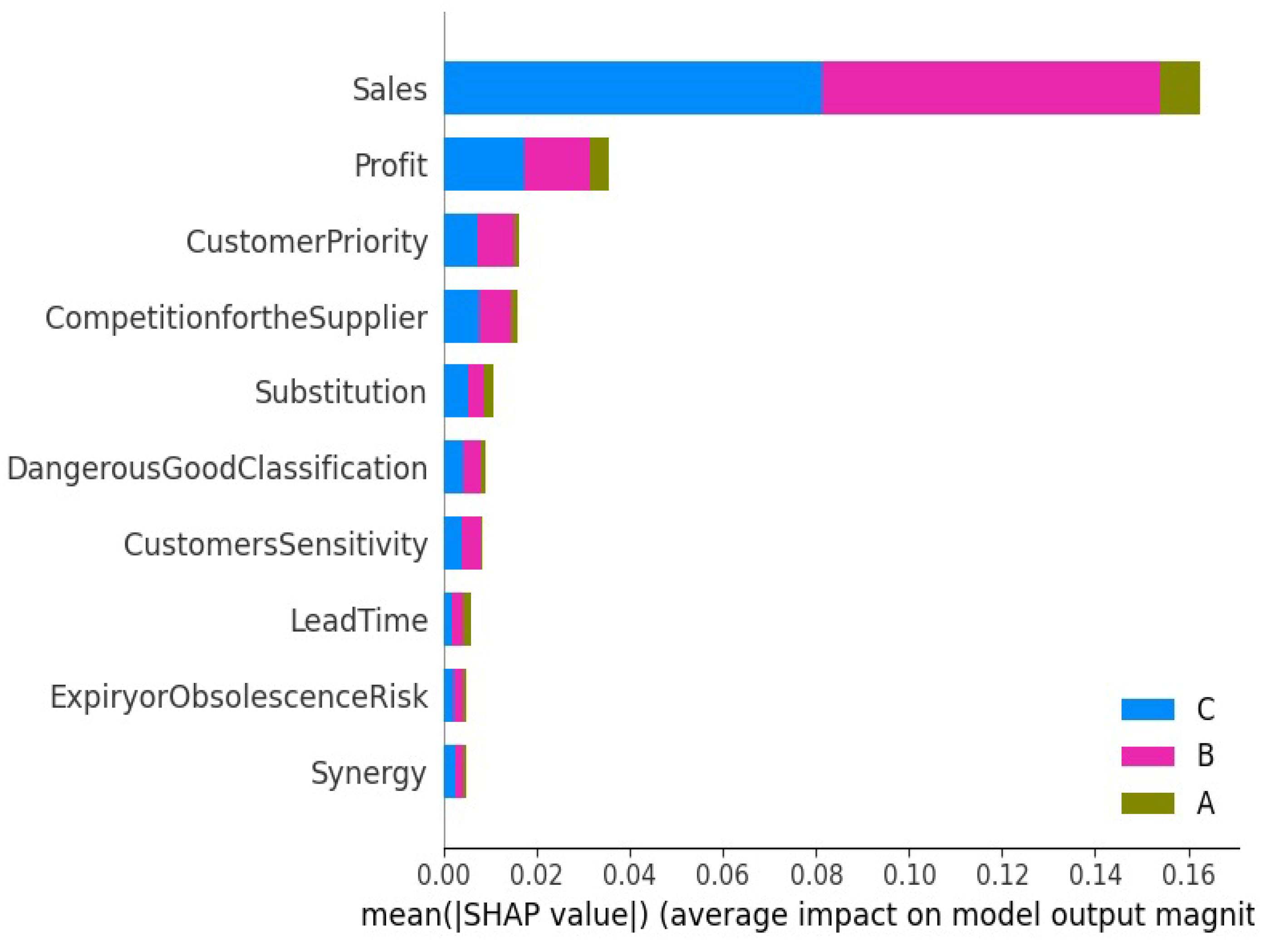
4.3. Global Explanations of ABC Classes
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Keskin, G.; Ozkan, C. Multiple criteria ABC analysis with FCM clustering. J. Ind. Eng. 2013, 2013, 827274. [Google Scholar] [CrossRef] [Green Version]
- Park, J.; Bae, H.; Bae, J. Cross-Evaluation-Based Weighted Linear Optimization for Multi-Criteria ABC Inventory Classification. Comput. Ind. Eng. 2014, 76, 40–48. [Google Scholar] [CrossRef]
- Ergün, E.; Ic, Y. An improved decision support system for ABC inventory classification. Evol. Syst. 2020, 11, 683–696. [Google Scholar] [CrossRef]
- Dickie, H.F. ABC Inventory Analysis Shoots for Dollars Not Pennies. Fact. Manag. Maint. 1951, 109, 92–94. [Google Scholar]
- Yiğit, F.; Esnaf, Ş. A new Fuzzy C-Means and AHP-based three-phased approach for multiple criteria ABC inventory classification. J. Intell. Manuf. 2021, 32, 1517–1528. [Google Scholar] [CrossRef]
- Chen, Y.; Li, K.W.; Marc Kilgour, D.; Hipel, K.W. A case-based distance model for multiple criteria ABC analysis. Comput. Oper. Res. 2008, 35, 776–796. [Google Scholar] [CrossRef]
- Saaty, T. The Analytic Hierarchy Process: Planning, Priority Setting, Resource Allocation; Advanced Book Program; McGraw-Hill International Book Company: New York, NY, USA, 1980. [Google Scholar]
- Xu, R.; Zhai, X. Fuzzy logarithmic least squares ranking method in analytic hierarchy process. Fuzzy Sets Syst. 1996, 77, 175–190. [Google Scholar] [CrossRef]
- Meade, L.; Sarkis, J. Analyzing organizational project alternatives for agile manufacturing processes: An analytical network approach. Int. J. Prod. Res. 1999, 37, 241–261. [Google Scholar] [CrossRef]
- Liu, Q.; Huang, D. Classifying ABC Inventory with Multicriteria Using a Data Envelopment Analysis Approach. In Proceedings of the Sixth International Conference on Intelligent Systems Design and Applications, Jinan, China, 16–18 October 2006; Volume 1, pp. 1185–1190. [Google Scholar] [CrossRef]
- Onwubolu, G.; Dube, B. Implementing an improved inventory control system in a small company: A case study. Prod. Plan. Control 2006, 17, 67–76. [Google Scholar] [CrossRef]
- Zheng, S.; Fu, Y.; Lai, K.K.; Liang, L. An improvement to multiple criteria ABC inventory classification using Shannon entropy. J. Syst. Sci. Complex. 2017, 30, 857–865. [Google Scholar] [CrossRef]
- Wu, S.; Fu, Y.; Lai, K.K.; Leung, J. A Weighted Least-Square Dissimilarity Approach for Multiple Criteria ABC Inventory Classification. Asia-Pac. J. Oper. Res. 2018, 35, 1850025. [Google Scholar] [CrossRef]
- Ramanathan, R. ABC inventory classification with multiple-criteria using weighted linear optimization. Comput. Oper. Res. 2006, 33, 695–700. [Google Scholar] [CrossRef]
- Ng, W.L. A simple classifier for multiple criteria ABC analysis. Eur. J. Oper. Res. 2007, 177, 344–353. [Google Scholar] [CrossRef]
- Hadi-Vencheh, A. An improvement to multiple criteria ABC inventory classification. Eur. J. Oper. Res. 2010, 201, 962–965. [Google Scholar] [CrossRef]
- Karagiannis, G. Partial average cross-weight evaluation for ABC inventory classification. Int. Trans. Oper. Res. 2021, 28, 1526–1549. [Google Scholar] [CrossRef]
- Chu, C.W.; Liang, G.S.; Liao, C.T. Controlling inventory by combining ABC analysis and fuzzy classification. Comput. Ind. Eng. 2008, 55, 841–851. [Google Scholar] [CrossRef]
- Çebi, F.; Kahraman, C.; Bolat, B. A multiattribute ABC classification model using fuzzy AHP. In Proceedings of the 40th International Conference on Computers and Indutrial Engineering, Awaji City, Japan, 25–28 July 2010; pp. 1–6. [Google Scholar] [CrossRef]
- Partovi, F.Y.; Anandarajan, M. Classifying inventory using an artificial neural network approach. Comput. Ind. Eng. 2002, 41, 389–404. [Google Scholar] [CrossRef]
- Yu, M.C. Multi-criteria ABC analysis using artificial-intelligence-based classification techniques. Expert Syst. Appl. 2011, 38, 3416–3421. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Das, A.; Rad, P. Opportunities and challenges in explainable artificial intelligence (xai): A survey. arXiv 2020, arXiv:2006.11371. [Google Scholar]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable ai: A review of machine learning interpretability methods. Entropy 2020, 23, 18. [Google Scholar] [CrossRef] [PubMed]
- Arias-Castro, E.; Lerman, G.; Zhang, T. Spectral clustering based on local PCA. J. Mach. Learn. Res. 2017, 18, 253–309. [Google Scholar]
- Ding, C.; He, X. K-means clustering via principal component analysis. In Proceedings of the Twenty-First International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004; p. 29. [Google Scholar]
- Jafarzadegan, M.; Safi-Esfahani, F.; Beheshti, Z. Combining hierarchical clustering approaches using the PCA method. Expert Syst. Appl. 2019, 137, 1–10. [Google Scholar] [CrossRef]
- Kacem, M.A.B.H.; N’cir, C.E.B.; Essoussi, N. MapReduce-based k-prototypes clustering method for big data. In Proceedings of the 2015 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Paris, France, 19–21 October 2015; pp. 1–7. [Google Scholar]
- Mahmud, M.S.; Rahman, M.M.; Akhtar, M.N. Improvement of K-means clustering algorithm with better initial centroids based on weighted average. In Proceedings of the 2012 7th International Conference on Electrical and Computer Engineering, Dhaka, Bangladesh, 20–22 December 2012; pp. 647–650. [Google Scholar]
- Yedla, M.; Pathakota, S.R.; Srinivasa, T. Enhancing K-means clustering algorithm with improved initial center. Int. J. Comput. Sci. Inf. Technol. 2010, 1, 121–125. [Google Scholar]
- Bandyapadhyay, S.; Fomin, F.; Golovach, P.A.; Lochet, W.; Purohit, N.; Simonov, K. How to Find a Good Explanation for Clustering? In Proceedings of the AAAI-2022, Virtually, 22 February–1 March 2022; Volume 36. [Google Scholar]
- Dasgupta, S.; Nave Frost, M.M.; Rashtchian, C. Explainable k-Means and k-Medians Clustering. In Proceedings of the 37 th International Conference on Machine Learning, Virtually, 13–18 July 2020. [Google Scholar]
- Morichetta, A.; Casas, P.; Mellia, M. EXPLAIN-IT: Towards explainable AI for unsupervised network traffic analysis. In Proceedings of the 3rd ACM CoNEXT Workshop on Big Data, Machine Learning and Artificial Intelligence for Data Communication Networks, Orlando, FL, USA, 9 December 2019; pp. 22–28. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Wang, M.; Zheng, K.; Yang, Y.; Wang, X. An explainable machine learning framework for intrusion detection systems. IEEE Access 2020, 8, 73127–73141. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Lolli, F.; Ishizaka, A.; Gamberini, R. New AHP-based approaches for multi-criteria inventory classification. Int. J. Prod. Econ. 2014, 156, 62–74. [Google Scholar] [CrossRef] [Green Version]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Davies, D.L.; Bouldin, D.W. A cluster separation measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 224–227. [Google Scholar] [CrossRef]
- Calinski, T. A dendrite method for cluster analysis. Commun. Stat. 1974, 3, 1–27. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
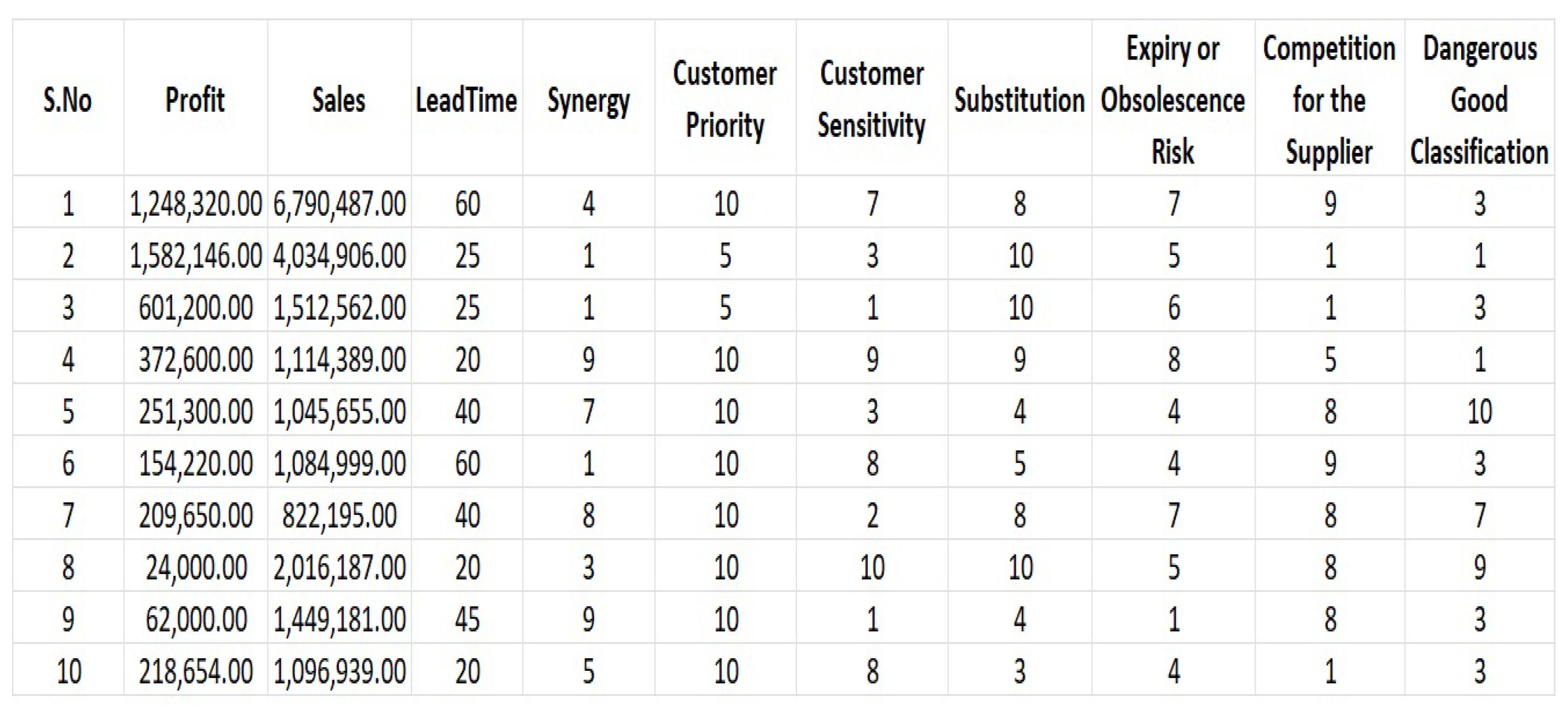
| Min | 1st Qu. | Median | Mean | 3rd Qu. | Max | |
|---|---|---|---|---|---|---|
| Profit | 1 | 150 | 1975 | 29,910 | 13,460 | 1,582,146 |
| Sales | 90 | 6600 | 28,213 | 173,467 | 103,401 | 6,790,487 |
| Lead Time | 3 | 20 | 20 | 46.41 | 30 | 60 |
| Synergy | 1 | 2 | 5 | 4.85 | 7 | 10 |
| Customer Priority | 1 | 5 | 5 | 6.48 | 10 | 10 |
| Customers Sensitivity | 1 | 3 | 5 | 5.21 | 8 | 10 |
| Substitution | 1 | 3 | 5 | 5.31 | 8 | 10 |
| Expiry or Obsolescence Risk | 1 | 3 | 5 | 4.96 | 7 | 10 |
| Competition for the Supplier | 1 | 1 | 5 | 4.7 | 7 | 9 |
| Dangerous Good Classification | 1 | 3 | 5 | 5.12 | 7 | 10 |
| Method | A | B | C |
|---|---|---|---|
| AHP-k-means | 1% | 16% | 83% |
| AHP-k-means-Veto | 1% | 10% | 89% |
| AHP-FCM | 9% | 15% | 76% |
| AHP-FCM-Rveto | 21% | 30% | 49% |
| Ex-K-means | 8% | 12% | 80% |
| Method | SC | DBI | CHI |
|---|---|---|---|
| AHP-k-means | 0.87 | 630.27 | 0.51 |
| AHP-k-means-Veto | 0.03 | 12.80 | 2.40 |
| AHP-FCM | 0.59 | 434.43 | 0.66 |
| Ex-k-means | 0.86 | 1203.03 | 0.28 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qaffas, A.A.; Ben HajKacem, M.-A.; Ben Ncir, C.-E.; Nasraoui, O. An Explainable Artificial Intelligence Approach for Multi-Criteria ABC Item Classification. J. Theor. Appl. Electron. Commer. Res. 2023, 18, 848-866. https://doi.org/10.3390/jtaer18020044
Qaffas AA, Ben HajKacem M-A, Ben Ncir C-E, Nasraoui O. An Explainable Artificial Intelligence Approach for Multi-Criteria ABC Item Classification. Journal of Theoretical and Applied Electronic Commerce Research. 2023; 18(2):848-866. https://doi.org/10.3390/jtaer18020044
Chicago/Turabian StyleQaffas, Alaa Asim, Mohamed-Aymen Ben HajKacem, Chiheb-Eddine Ben Ncir, and Olfa Nasraoui. 2023. "An Explainable Artificial Intelligence Approach for Multi-Criteria ABC Item Classification" Journal of Theoretical and Applied Electronic Commerce Research 18, no. 2: 848-866. https://doi.org/10.3390/jtaer18020044